Category: learning
-
Crafting Interpreters (III): Resolving a Name Before It Runs
Resolver freezes variable identity before execution: each variable-use node gets either a fixed local depth or a deliberate global lookup, so mutable closure environments can change without changing lexical binding.
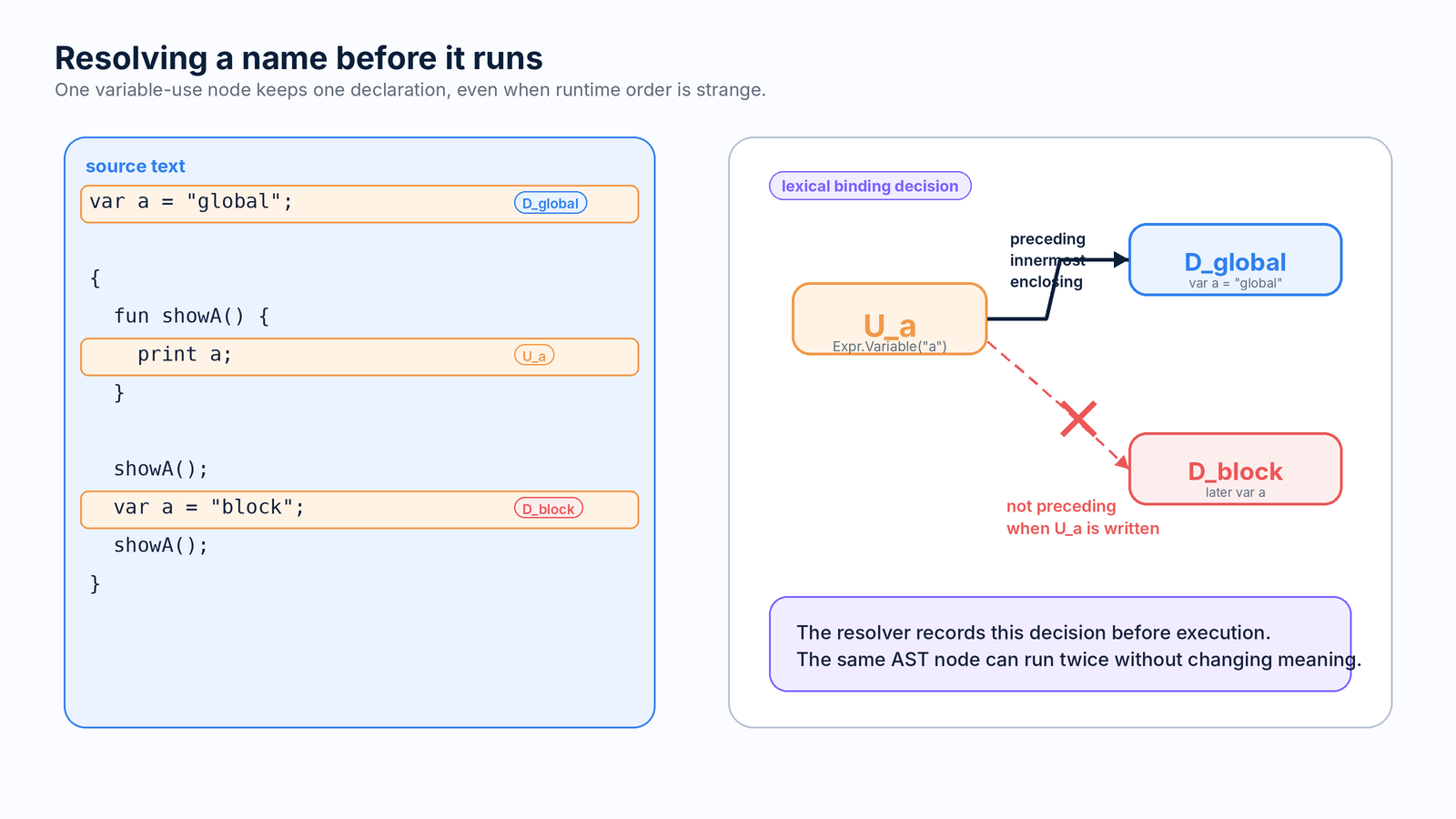
-
Crafting Interpreters (IV): Resolver Lays the Track, Interpreter Fills the Values
jlox's object system stays inside the same runtime model: classes, instances, methods, this, inheritance, and super are built from LoxClass, LoxInstance, LoxFunction, environments, closures, and resolver distances.
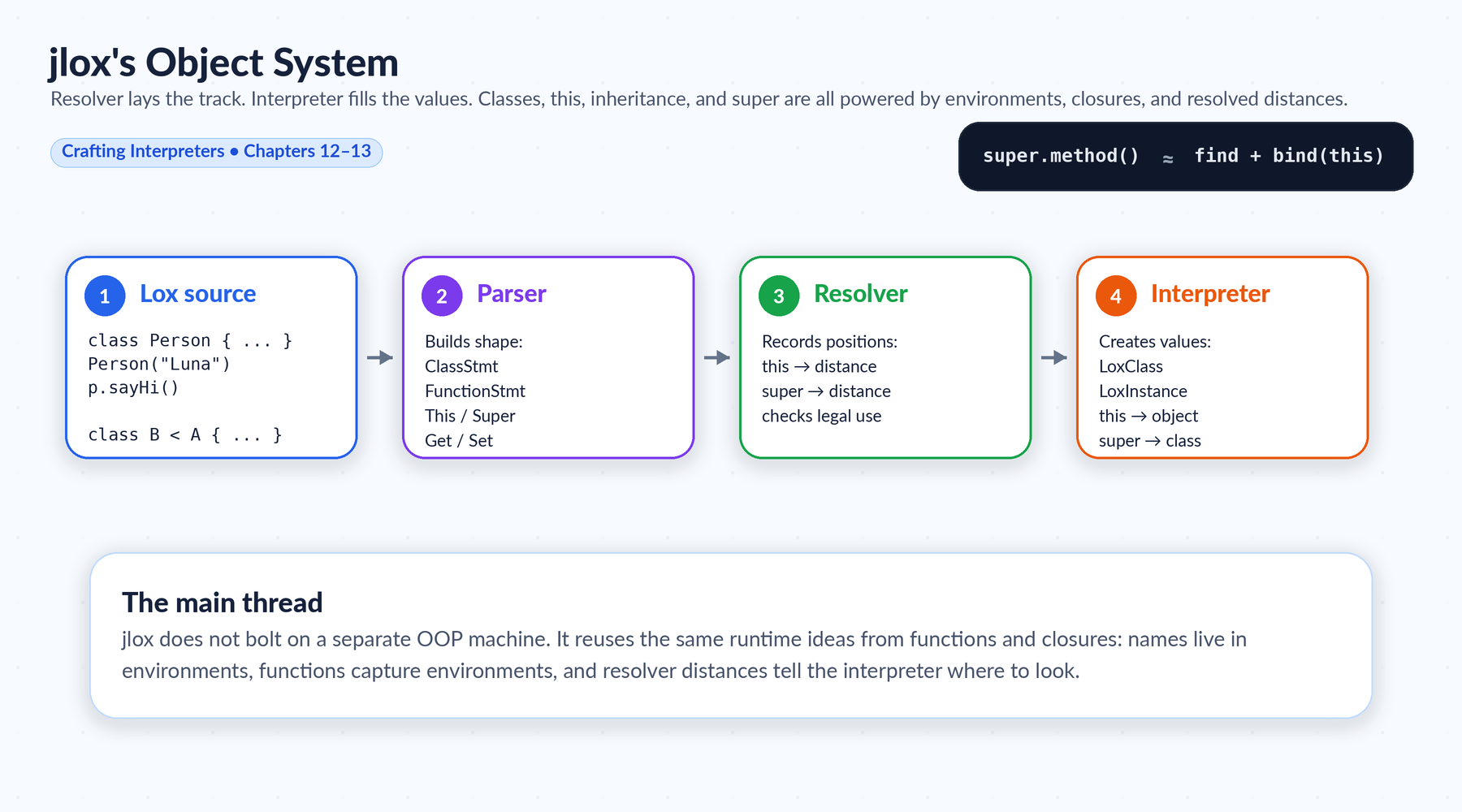
-
Crafting Interpreters (II): The Tree Begins to Run
An AST becomes a run when the interpreter walks it: expressions produce values, statements create effects, environments hold state, control flow chooses subtrees, and closures preserve captured scope.
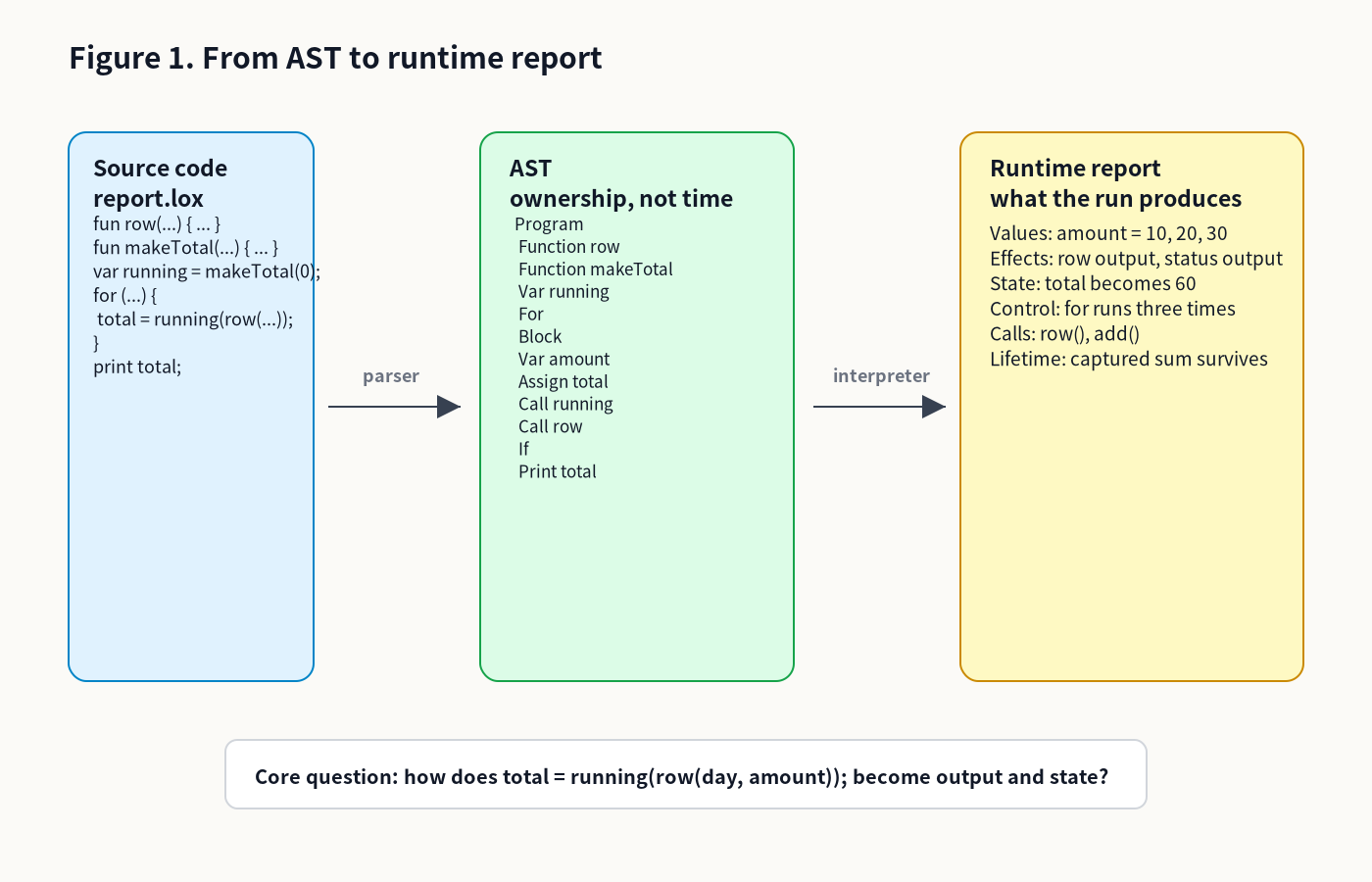
-
Crafting Interpreters (I): When Source Text Becomes Structure
Source text becomes executable structure in phases: scanning creates token boundaries, parsing turns precedence and associativity into an AST, and later phases consume that preserved tree.
-
Sutton RL: Chapter 6 - Temporal-Difference Learning
TLDR: TD learning updates from partial experience by bootstrapping current value estimates, combining Monte Carlo sampling with dynamic-programming-style updates.
-
Sutton RL: Chapter 5 - Monte Carlo Methods
TLDR: Monte Carlo methods learn value from complete sampled episodes, trading model-free simplicity for delayed updates and return variance.
-
Sutton RL: Day 2 - Multi-Armed Bandits
TLDR: Multi-armed bandits isolate the exploration/exploitation problem by removing state transitions and making action-value estimation the center.
-
Sutton RL: Day 3 - Dynamic Programming
Dynamic programming is the model-based starting point of reinforcement learning: with known MDP dynamics, Bellman equations become iterative value and policy update rules.