SkillOpt:在权重之外训练流程
谈论座席 skill 的简单方法是将其称为提示。
SkillOpt 让人感觉这是错误的。skill 更接近程序记忆:一种小型外部产物,告诉智能体在某个领域里该怎么做、先检查什么、要避开什么错误,以及哪些证据重要。
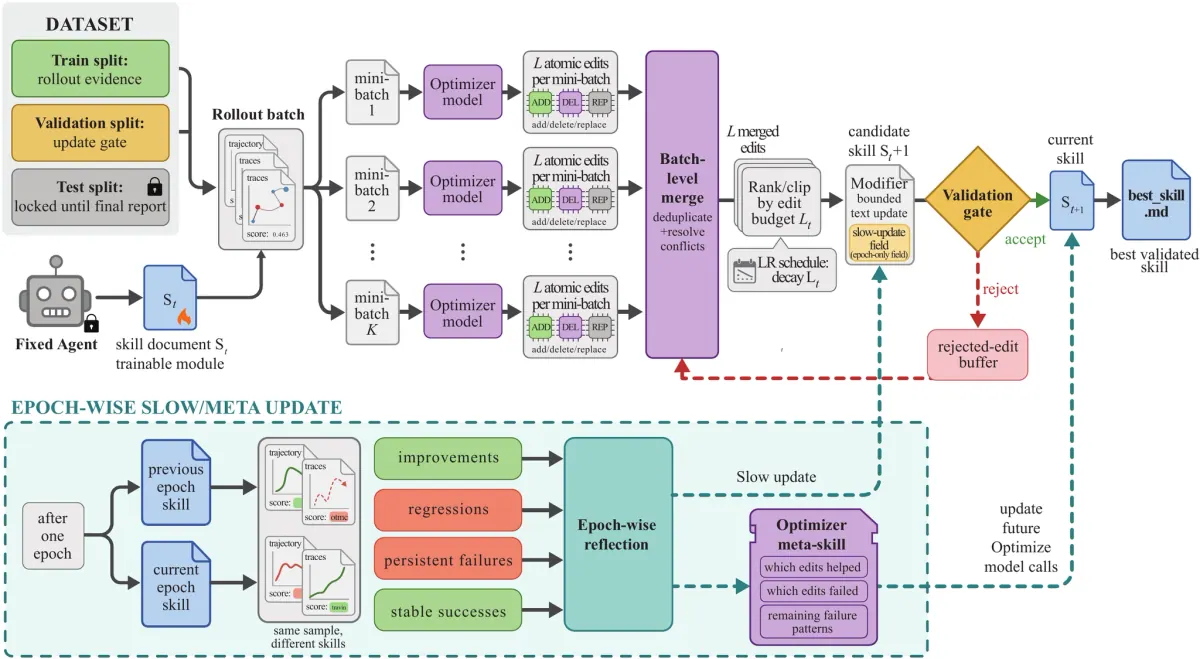
这篇论文的主要举措简单但功能强大:保持目标模型冻结,然后根据rollout证据优化 skill 文本。
正在训练什么
SkillOpt 不会调整模型权重。它训练一个文件。
这种区别很重要。可部署的对象是一个紧凑的 best_skill.md,通常小到足以直接检查。在推理时,优化器消失。该工具只是加载经过训练的 skill 并让目标模型使用它。
这样这个方法具有良好的工程形状:
frozen model
+ current skill
+ task rollouts
+ scored outcomes
-> optimizer proposes edits
-> validation gate accepts or rejects
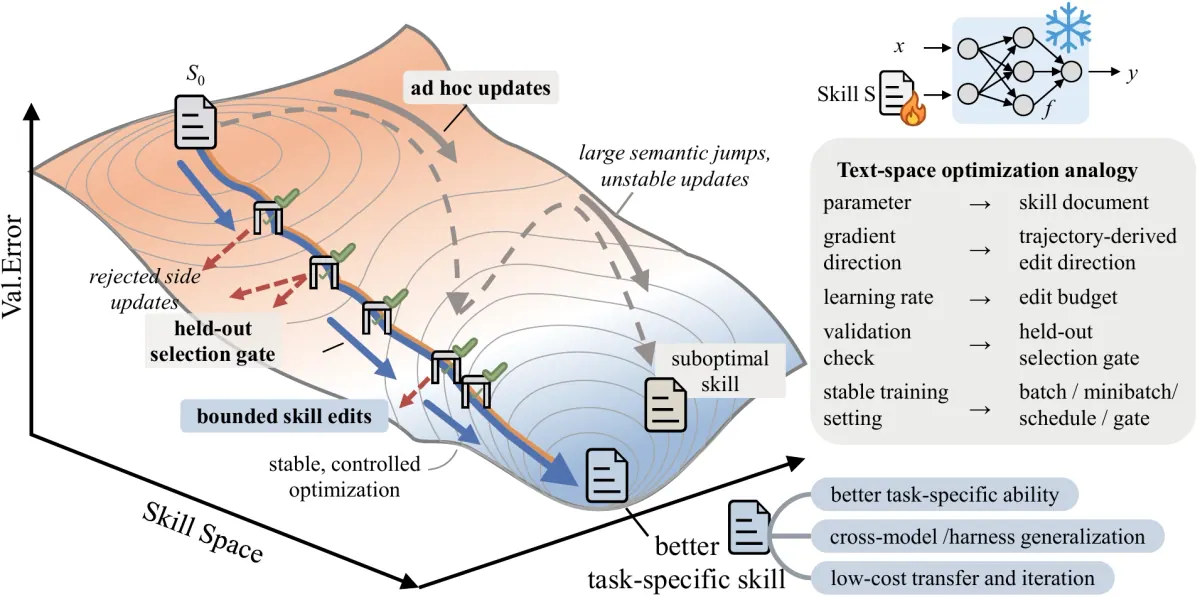
-> better skill artifact该 skill 成为文本空间中的参数:可读、可版本化、可审核以及跨 harness 移植。
为什么不直接重写提示
重要的细节是控制。优化器不会被要求每轮自由地生成一个新的超级提示。它建议进行有界编辑:添加、删除、替换、合并、排名或剪辑特定指令。
这篇论文将其视为文本学习率。如果每次更新都能改变太多,skill 就会变得不稳定。如果变化太少,它就无法学习。因此,一个好的 skill 优化器需要与任何训练循环相同的规则:
- 批量和小批量;
- 对成功和失败的反思;
- 编辑预算有限;
- 反面例子;
- 稳定模式更新缓慢;
- 部署前验证。
这是我最喜欢的部分。这篇论文把“改 prompt”从口味问题变成了优化问题。
验证门是中心
验证门是阻止系统成为热情的提示重写器的原因。
候选 skill 必须在 held-out selection split 上击败当前 skill。打平还不够。被拒绝的编辑不会因为无用而被丢掉;它们会成为后续几轮的负面反馈。
这就产生了一种有用的不对称性:
easy to propose
hard to accept对于智能体工程来说,这是正确默认值。文本指令的变异成本很低,而且很容易过拟合。这个门迫使系统证明:这次更改在触发它的 rollout 批次之外仍然有效。
学到的 skill 包含哪些内容
最有趣的学习规则不是神奇的短语。它们看起来像域过程。
对于电子表格任务,一项有用的 skill 可能是:在写入静态值之前检查工作簿结构和公式。对于 QA 任务,它可能会说:在复制文本之前将答案绑定到确切的表行或字段。对于编码任务,它可能会说:在更改实现之前重现失败的情况。
这就是为什么“skill”这个词是正确的。一项 skill 压缩了重复练习:
failure trace -> rule -> reusable procedure -> validation它不是一项任务的记忆。这是一种持续的行为方式。
为什么这很重要
SkillOpt 建议在两个昂贵的极端之间采取中间路径:
- 将每一项改进都融入到模型权重中;
- 手写越来越长的系统提示符。
许多收益都存在于程序性约束中:检查什么、避免什么、如何验证、如何格式化、何时停止。这些增益可以存储在模型外部的一份小型文本产物里。
这也正是我想要的个人博客写作模式。博客 skill 不应该强迫每一篇草稿都变成一个严格的模板。它应该保留可重用的过程:找到贯穿线,选择宽松的格式,用英语编写,仅在有帮助时使用代码/数学,并对呈现的页面进行质量检查。
更广泛的教训是,智能体需要周围可训练的外部产物,而不只是内部更大的模型。