SkillOpt
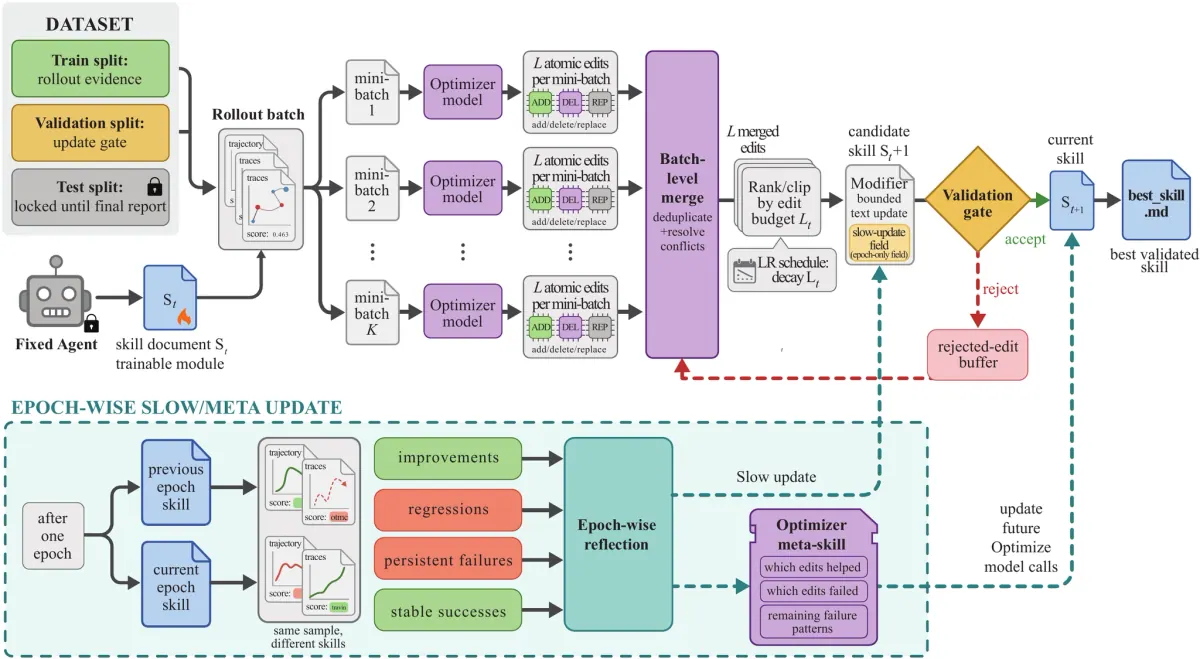
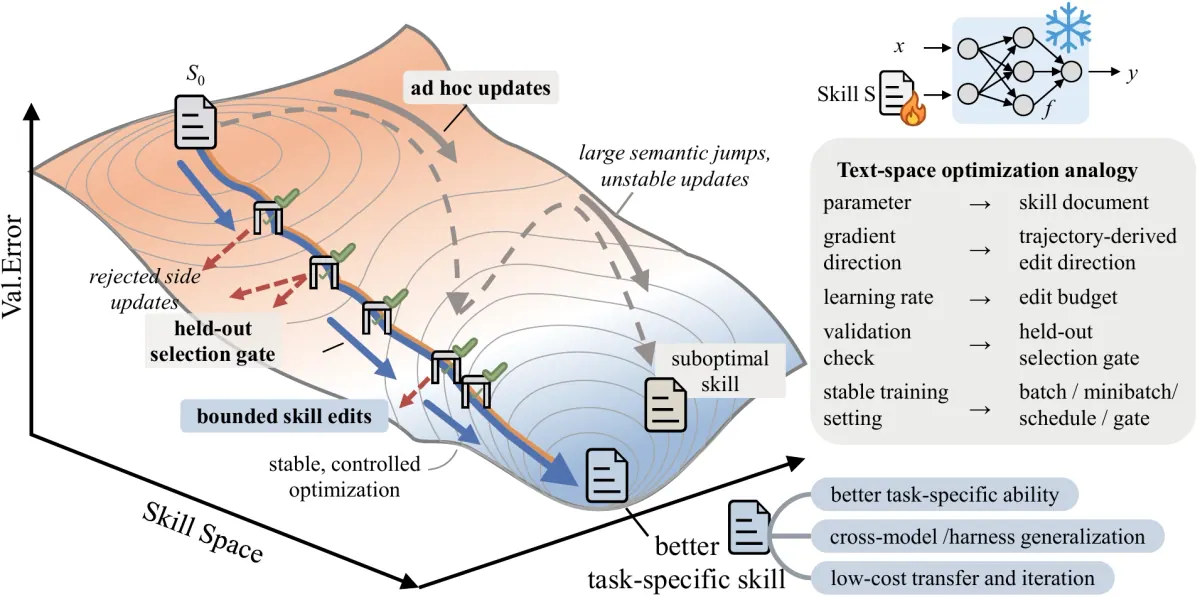
SkillOpt 把 agent skill 从“人写的提示词/经验总结”,改写成一个可以被训练的外部状态。目标模型保持冻结,只负责带着当前 skill 执行任务;另一个 optimizer model 读取带分数的 rollouts,把成功和失败轨迹压缩成受控的 add/delete/replace 编辑,并且只有当候选 skill 在 held-out validation split 上严格变好时才接受。它的核心主张很直接:如果 skill 是 agent 的程序性记忆,那它就不该靠一次性手写,而应该像参数一样被稳定优化。
-
Skill document 被当成 text-space 参数: 论文把 domain adaptation 的对象从 model weights 和 prompt,转移到一个可审计的
best_skill.md。这个文件通常只有 300-2,000 tokens,部署时不调用 optimizer、不改模型权重,只把训练好的 skill 放进 direct chat、Codex 或 Claude Code 这类 harness 里使用。 -
优化器不是自由改写,而是有学习率的文本更新: SkillOpt 用 rollout batch 收集证据,再把失败和成功轨迹分成 reflection minibatches,让 optimizer model 产出结构化编辑。所谓 textual learning rate 就是每步最多允许应用多少条 skill edits;默认还配合 schedule、batch/minibatch、merge/rank/clip,让 skill 的变化像训练步长一样可控,而不是每轮重写一份新 prompt。
-
Validation gate 是稳定性的核心: 每个 candidate skill 都必须在 selection split 上严格超过当前分数才会被接受,平局也拒绝。被拒绝的 edits 不会浪费,而是进入 rejected-edit buffer,成为后续优化的负反馈;再加上 epoch-wise slow/meta update,系统可以保留长期有效的编辑方向,同时避免局部失败把 skill 拉偏。
-
实证结果很激进: SkillOpt 在 6 个 benchmark、7 个 target model、3 种执行 harness 上,52/52 个评测单元都是最好或并列最好。以 GPT-5.5 为例,它把 direct chat 的平均 no-skill accuracy 提高 +23.5,在 Codex loop 里提高 +24.8,在 Claude Code 里提高 +19.1;在 direct chat 下还比每个 cell 里最强的 human skill、one-shot LLM skill、Trace2Skill、TextGrad、GEPA、EvoSkill 等 baseline oracle 高 +5.4。
-
学到的是可迁移的程序,而不是题目记忆: 训练出的 skill 可以跨模型、跨 harness、跨相近 benchmark 迁移。SpreadsheetBench skill 从 Codex 转到 Claude Code 仍带来 +59.7,Claude Code 转 Codex 带来 +43.6;OlympiadBench skill 转到 Omni-MATH 也在三个模型规模上保持正收益。案例里保留下来的规则也很像人类专家会写的程序性约束,例如“先检查 workbook 结构和公式,再写入静态值”或“把问题绑定到确切表格行/字段后再复制答案”。
为什么重要: 这篇论文把 “skills” 从 prompt 工程产物推到了一个更像优化对象的位置。它给 agent builder 的启发是:很多能力提升不一定要进权重,也不一定要靠更长的系统提示;可以把可复用流程、工具纪律、格式约束和失败模式压进一个小型 skill artifact,再用训练式 controls 去改它。更有意思的是,这个 artifact 部署时几乎没有额外系统复杂度,但训练时可以享受 optimizer strength、validation gate、learning-rate schedule、negative feedback 这些机器学习里成熟的稳定化工具。