RLM:递归语言模型
核心判断
这是一篇有真洞察的系统论文,但主张有点过。它的价值不在“递归”这个词,而在于把长上下文从 Transformer token 序列里拿出来,变成可以用代码检索、切片、调用和验证的外部对象。最危险的问题是:论文证明了强模型放在好 scaffolding 里可以赢不少基准,但还没证明这套机制已经是稳定、通用、可控的“新范式”。
1. 动机:痛点确实存在,但作者夸大了范围
这篇文章要解决的不是普通的“上下文窗口不够长”。问题更尖锐:即使模型的物理窗口足够大,有效注意力、信息保真度和长输入上的组合推理仍然会衰减。作者把它称为 context rot:上下文变长时,GPT-5 这类前沿模型也会退化。同时,许多真正的长上下文任务需要处理数百万甚至数千万个 token,而不只是从几个段落里找一根针。 (arXiv)
这个痛点是真实存在的,尤其是在 OOLONG 这类几乎每一行都要用上的任务里。作者还明确区分了简单的 NIAH 和信息密集型任务:NIAH 里答案大小不随输入增长,而 OOLONG / OOLONG-Pairs 里的处理量会随输入线性甚至二次增长。这个区别击中了许多长上下文论文的弱点:证明模型能找到目标,不等于证明它理解长文档。 (arXiv)
但这里也有包装。“任意长 prompt”更像营销话术,不是机制本身。RLM 并没有给神经网络真正无限的上下文,它只是把瓶颈从模型上下文窗口转移到外部环境、代码执行、子调用成本、搜索策略和 RAM。它解决的是可编程访问的长输入,不是任意长输入。
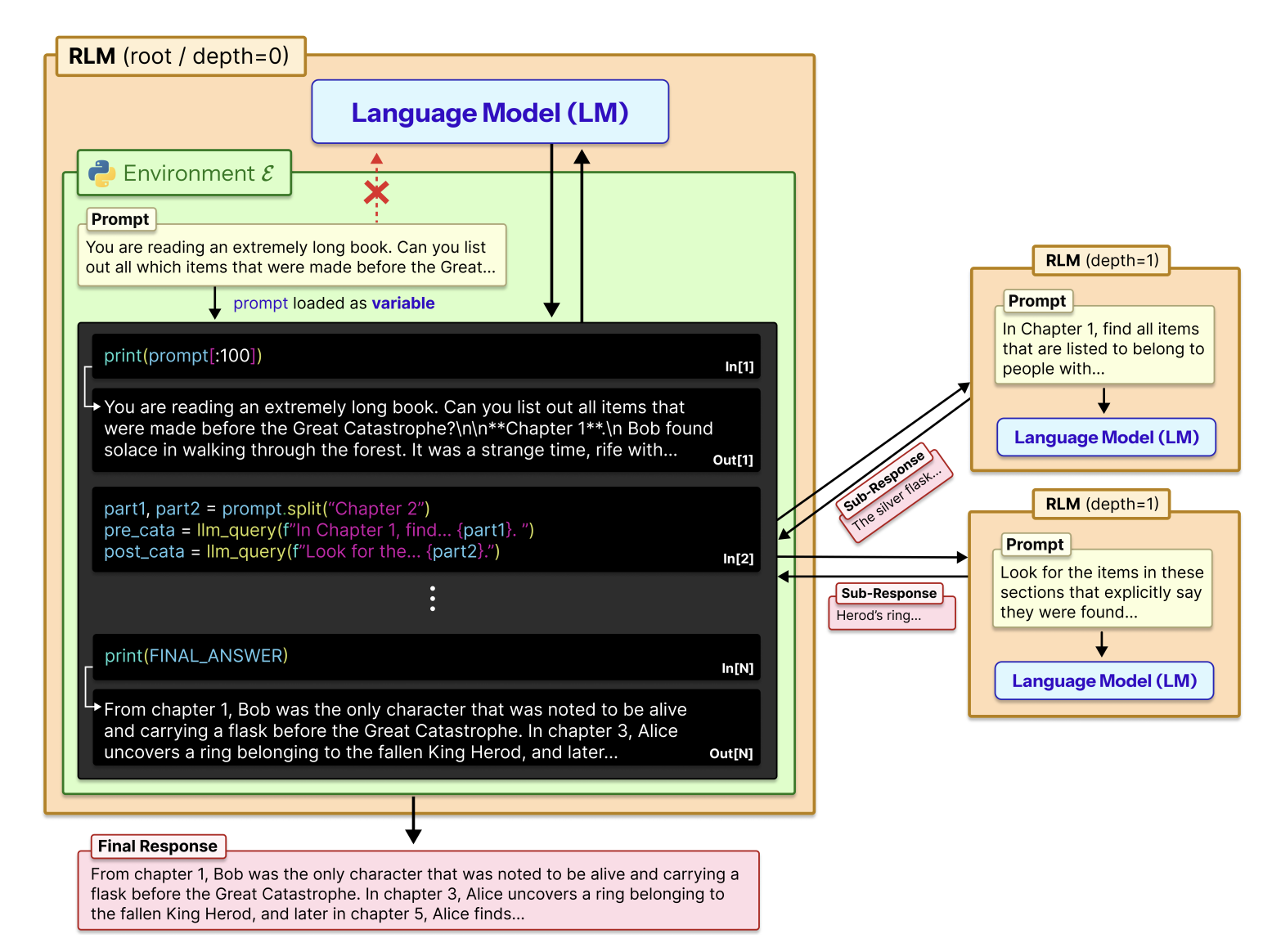
2. 贡献:核心不是递归,而是 prompt-as-environment
如果我只能保留一项贡献,我会保留这一贡献:提示被视为外部环境变量,而不是直接输入到模型上下文中的东西。这是这篇文章中最简洁、最可移植的想法。 RLM 将长提示放入 Python REPL 内的 context 变量中,让模型使用代码来检查、拆分、过滤和调用子 LM,然后将本地结果拼接回最终答案。 (arXiv)
当然,“递归调用 LM”很重要,但这不是第一性原理的贡献。证据表明,无子调用消融仍然跨越了模型上下文限制,并且在 Qwen3-Coder 的 CodeQA 和 BrowseComp+ 上,它甚至击败了完整的 RLM。完整的 RLM 仅在 OOLONG / OOLONG-Pairs 等信息密集型任务上打开了明显差距,其中系统需要大量语义转换和聚合。 (arXiv)
所以这篇论文的贡献应该更名为:外部记忆语言模型推理,而不是递归语言模型。递归只是外部环境中的一种操作。
3. 方法:把长上下文问题改写成外部内存问题
这个方法的关键见解是:不要强迫模型立刻“读完”整个长输入,而是让模型像程序一样管理输入访问路径。作者借鉴了核外算法:当小而快的主内存无法处理大型数据集时,答案不是简单扩大主内存,而是安排好数据移动。对 LLM 来说,对应做法不是把整个 prompt 塞进 Transformer,而是让模型决定看哪里、如何切片,以及哪些片段应该交给子 LM。 (arXiv)
这比摘要/压缩更强,因为摘要假设早期细节可以被压缩或忘记。在信息密集的任务中,这些细节可能不是一次性的。 RLM 可以将原始输入保留在外部环境中,并且仅在需要时检索本地片段。它也比普通的递归智能体更强,因为许多递归智能体可以递归地分解任务,但原始输入仍然必须首先适合模型窗口。 RLM 将输入本身置于外部环境中,因此递归发生在可编程片上。 (arXiv)
但这种见解也揭示了这个方法真正依赖的是什么。 RLM 不会自动理解长上下文。它依赖于模型编写代码、进行启发式搜索和构造子问题。这篇论文自己的轨迹分析表明,模型经常使用正则表达式、关键字和先验知识来缩小搜索空间。这很强大,但也意味着当先验薄弱、措辞对抗性或数据分布不均时,系统可能会系统性地错过证据。 (arXiv)
4. 结果:最有力的证据是信息密集型任务,不是 10M token 本身
有两个结果最能支撑论文主张。第一,BrowseComp+ 在 6M-11M token 上:由于上下文限制,GPT-5 base 为 0,而 RLM(GPT-5) 达到 91.33,明显领先 Summary agent 的 70.47 和 CodeAct+BM25 的 51.00。这个结果说明 RLM 确实可以把任务扩展到普通上下文之外。 (arXiv)
第二个结果更关键:OOLONG-Pairs。输入只有 32K token,理论上放得进上下文,但 GPT-5 base 几乎为 0,Summary agent 也几乎为 0,RLM(GPT-5) 达到 58.00。这个结果比“它可以处理 10M token”更有说服力,因为它说明问题不只是窗口长度,而是长输入内部的复合计算结构。 (arXiv)
这些结果不仅仅是漂亮的数字。作者包括基本模型、摘要基线、检索/代码智能体、无子调用消融以及围绕恒定、线性和二次信息密度设计的任务。这样证据链相对完整。 (arXiv)
但仍不能完全证明这个方法“普遍有效”。 OOLONG-Pairs 由 20 个手动修改的查询组成,因此其外部有效性受到限制。 BrowseComp+优势很强,但无子调用已经接近完整的 RLM,这意味着在某些任务中核心机制不是递归,而是基于 REPL 的外部访问。成本故事也并不干净。论文本身承认 RLM 具有长尾、高方差轨迹,其中有许多异常值,这些异常值比基本查询要昂贵得多。 (arXiv)
5. 局限:弱点是机制不稳定,不是实验不够
真正的弱点是:RLM 目前更像一个脆弱的智能体 scaffolding,依赖强模型行为,而不是稳定算法。附录相当坦诚。同一个 prompt 可能跨模型失效;Qwen3-Coder 需要额外提示来避免过多递归调用;小模型很难用,因为编码能力不够;thinking token 不足可能中断轨迹;用于分隔最终答案和中间思考的 FINAL 标签也很脆弱。 (arXiv)
更严重的是,作者观察到 RLM 轨迹经常做出非最优决策。 Qwen3-Coder 可能会在简单任务上启动数百或数千个递归子调用,而 GPT-5 只能进行十几个左右。模型也可能构建出正确的答案,然后放弃它,浪费更多的调用,甚至选择错误的最终答案。 (arXiv)
这个弱点是否推翻了核心结论?它并没有推翻提示即环境有价值的结论,但它确实削弱了 RLM 是一种通用、廉价、稳定的推理策略这一更大的主张。目前的证据表明,与此更接近的是:当根模型足够强大、可以编写代码、任务是可分解的、并且搜索策略恰好起作用时,RLM 就非常强大。它还没有证明它可以预测、可审计并且可以安全地部署在真正的开放式长期任务上。
最后三句话
- 这篇论文最值得学习的地方,是把长上下文从“扩大 Transformer 窗口”重构为“外部环境中的可编程数据访问”。这是有迁移价值的系统洞察。
- 最可疑的地方,是把强 prompt + REPL + 子模型调用这一套智能体 scaffolding 包装成“通用推理范式”。当前机制显然依赖模型行为、提示细节和任务可分解性。
- 它指向的未来研究方向不是继续堆更长上下文,而是训练模型规划阅读、验证证据、控制递归成本,并通过外部记忆做可靠推理。