RLM: Recursive Language Model
Core Judgment
This is a systems paper with real insight, but with claims that are a little too loud. Its real value is not the word “recursive.” Its value is that it takes long context out of the Transformer’s token sequence and turns it into an external object that can be retrieved, sliced, called, and verified by code. The most dangerous issue is this: it proves that a strong model inside a good scaffold can win many benchmarks, but it has not yet proven that this mechanism is already a stable, general, controllable “new paradigm.”
1. Motivation: the pain point is real, but the authors overstate the scope
The problem this paper wants to solve is not the ordinary problem of “the context window is not long enough.” It is a sharper problem: even if the model’s physical window is large enough, its effective attention, information fidelity, and compositional reasoning on long inputs still decay. The authors explicitly define the problem as context rot: when context gets longer, frontier models such as GPT-5 also degrade. At the same time, many real long-context tasks need to process millions or tens of millions of tokens, not just retrieve one needle from a few passages. (arXiv)
This pain point is real, especially on tasks such as OOLONG, where almost every line has to be used. The authors also make a clear distinction between simple NIAH and information-dense tasks: in NIAH, the answer size does not grow with the input, while in OOLONG / OOLONG-Pairs, the amount of processing grows linearly or quadratically with the input. This distinction matters because it hits the weak spot of many long-context papers: proving that a model can find the needle does not mean proving that it can understand a long document. (arXiv)
But there is also packaging. The phrase “arbitrarily long prompts” is more marketing than mechanism. RLM does not give the neural network a truly infinite context. It moves the bottleneck from the model context window into the external environment, code execution, subcall cost, search strategy, and RAM. What it solves is long input that can be accessed programmatically, not every arbitrary long input.
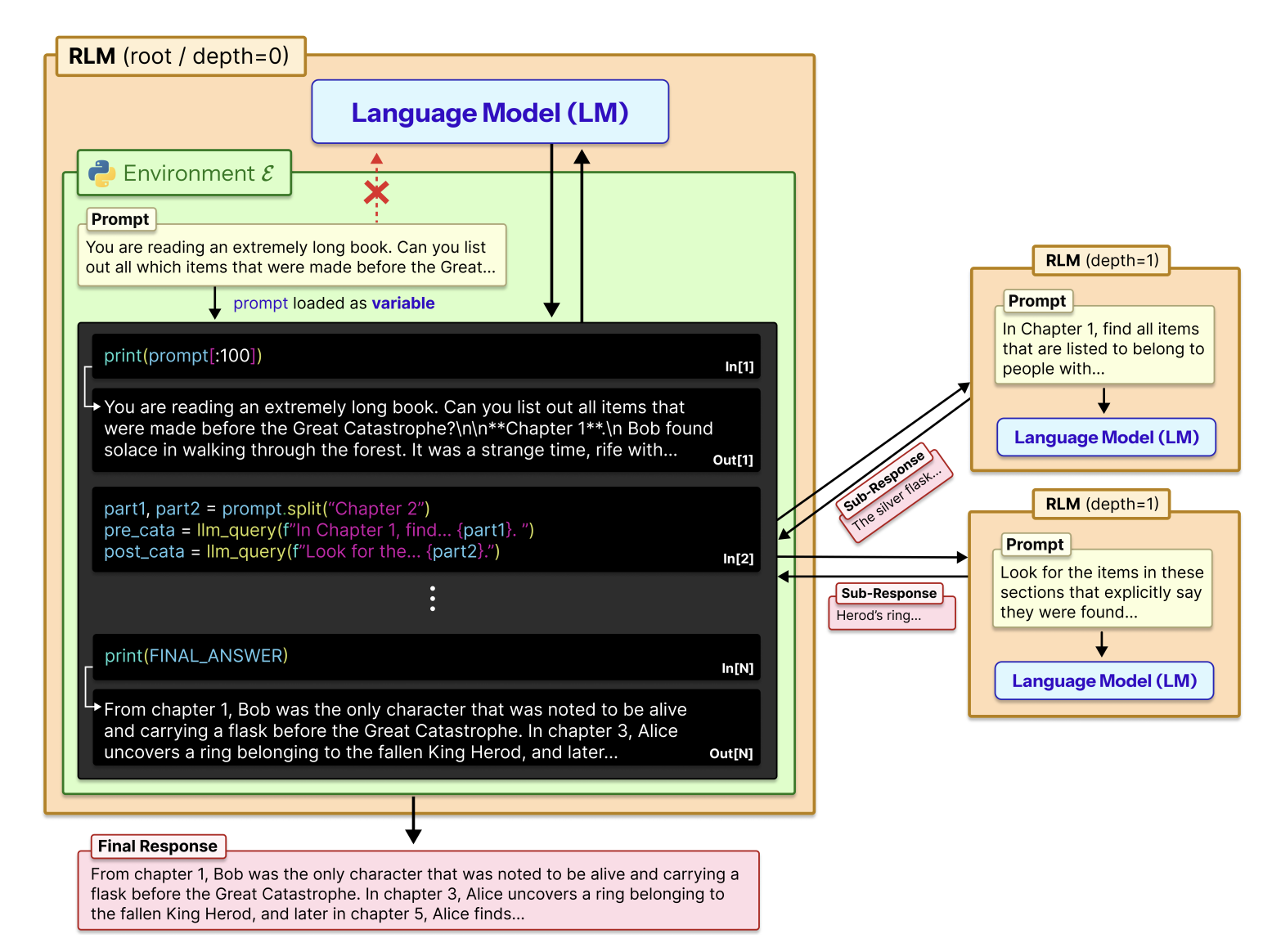
2. Contribution: the core contribution is not recursion, but “prompt-as-environment”
If I could keep only one contribution, I would keep this one: the prompt is treated as an external environment variable, not as something directly fed into the model context. This is the cleanest and most transferable idea in the paper. RLM puts the long prompt into the context variable inside a Python REPL, lets the model use code to inspect, split, filter, and call sub-LMs, and then stitches the local results back into the final answer. (arXiv)
“Recursively calling an LM” is important, of course, but it is not the first-principles contribution. The evidence is that the no-sub-calls ablation still crosses the model context limit, and on Qwen3-Coder’s CodeQA and BrowseComp+ it even beats full RLM. Full RLM only opens a significant gap on information-dense tasks such as OOLONG / OOLONG-Pairs, where the system needs a lot of semantic transformation and aggregation. (arXiv)
So the contribution of this paper should be renamed: external-memory language-model reasoning, not recursive language models. Recursion is only one operation inside the external environment.
3. Method: the key insight is turning the “long-context problem” into an “external-memory algorithm” problem
The key insight of the method is this: do not force the model to “read” the whole long input at once. Let the model manage the input access path like a program. The authors borrow from out-of-core algorithms: when small, fast main memory cannot handle a large dataset, the answer is not simply to enlarge main memory, but to schedule data movement intelligently. For LLMs, the corresponding move is not to stuff the entire prompt into the Transformer, but to let the model decide where to look, how to slice, and which fragments should be passed to sub-LMs. (arXiv)
This is stronger than summarization / compaction because a summary assumes early details can be compressed or forgotten. In information-dense tasks, those details may not be disposable. RLM can keep the original input in the external environment and only retrieve local fragments when needed. It is also stronger than an ordinary recursive agent because many recursive agents can decompose the task recursively, but the original input still has to fit into the model window first. RLM puts the input itself in the external environment, so recursion happens over programmable slices. (arXiv)
But this insight also exposes what the method truly depends on. RLM does not automatically understand long context. It relies on the model writing code, doing heuristic search, and constructing subproblems. The paper’s own trajectory analysis shows that models often use regex, keywords, and prior knowledge to narrow the search space. That is powerful, but it also means that when priors are weak, wording is adversarial, or data is out of distribution, the system may systematically miss evidence. (arXiv)
4. Result: the strongest evidence is information-dense tasks, not 10M tokens itself
Two results do the most work for the paper’s claim.
First, BrowseComp+ at 6M-11M tokens: GPT-5 base is 0 because of context limits, while RLM(GPT-5) reaches 91.33, clearly ahead of the Summary agent at 70.47 and CodeAct+BM25 at 51.00. This result shows that RLM can really extend tasks beyond ordinary context. (arXiv)
Second, and more importantly, OOLONG-Pairs: the input is only 32K tokens, so it can fit in context, but GPT-5 base is almost 0, the Summary agent is also almost 0, and RLM(GPT-5) reaches 58.00. This result is more convincing than “it can process 10M tokens,” because it shows that the problem is not just window length. It is the compositional computation structure inside long input. (arXiv)
These results are not just pretty numbers. The authors include a base model, summary baseline, retrieval/code agent, no-sub-calls ablation, and tasks designed around constant, linear, and quadratic information density. That makes the evidence chain relatively complete. (arXiv)
But it still does not fully prove that the method is “generally effective.” OOLONG-Pairs consists of 20 manually modified queries, so its external validity is limited. The BrowseComp+ advantage is strong, but no-sub-calls already comes close to full RLM, which means that in some tasks the core mechanism is not recursion, but REPL-based external access. The cost story is also not clean. The paper itself admits that RLM has long-tail, high-variance trajectories, with many outliers that are much more expensive than the base query. (arXiv)
5. Limitation: the fatal weakness is mechanism instability, not a lack of experiments
The fatal weakness is this: RLM currently looks more like a fragile agent scaffold that depends on strong model behavior than a stable algorithm. The appendix is quite candid. The same prompt can break across models; Qwen3-Coder needs extra prompting to avoid too many recursive calls; smaller models are hard to use because their coding ability is not strong enough; insufficient thinking tokens can interrupt trajectories; and the FINAL tag that separates final answers from intermediate thinking is also fragile. (arXiv)
More seriously, the authors observe that RLM trajectories often make non-optimal decisions. Qwen3-Coder may launch hundreds or thousands of recursive subcalls on simple tasks, while GPT-5 makes only a dozen or so. Models may also construct the correct answer, drop it, waste more calls, and even choose the wrong final answer. (arXiv)
Does this weakness overturn the core conclusion? It does not overturn the conclusion that prompt-as-environment is valuable, but it does weaken the larger claim that RLM is a general, cheap, stable inference strategy. The current evidence says something closer to this: when the root model is strong enough, can write code, the task is decomposable, and the search strategy happens to work, RLM is very strong. It has not yet proven that it is predictable, auditable, and safe to deploy on real open-ended long tasks.
Final three sentences
- The most valuable thing to learn from this paper: it reframes long context from “expand the Transformer window” into “programmable data access in an external environment,” which is a systems-level insight with real transfer value.
- The most suspicious thing about this paper: it packages a strong prompt + REPL + sub-model-call agent scaffold as a “general inference paradigm,” but the current mechanism clearly depends on model behavior, prompt details, and task decomposability.
- The direction it suggests for future research: the valuable work is not to keep stacking longer context, but to train models to plan reading, verify evidence, control recursion cost, and execute reliable reasoning over external memory.