Claude Code 自动模式:把权限做成运行时安全
来源:人类工程,Claude 代码自动模式:跳过权限的更安全方法。
浅读
读取自动模式的简单方法是:
Claude Code asks for too many approvals.
Auto mode skips some of them.这不是有趣的部分。
更有说服力的解读是,自动模式将审批疲劳变成了运行时安全问题。当手动确认很少且有意义时非常有用。如果每个普通文件的读取、grep 或本地编辑都要求审批,那么用户就变成了一台点击按钮的机器。如果跳过每个审批,智能体可能会在不知情的情况下跨越信任边界。
自动模式尝试在这些故障之间生存:
allow obvious safe actions
classify risky actions
deny or escalate high-blast-radius behavior
let the agent recover through safer paths两个护栏
该设计有两个不同的安全表面。
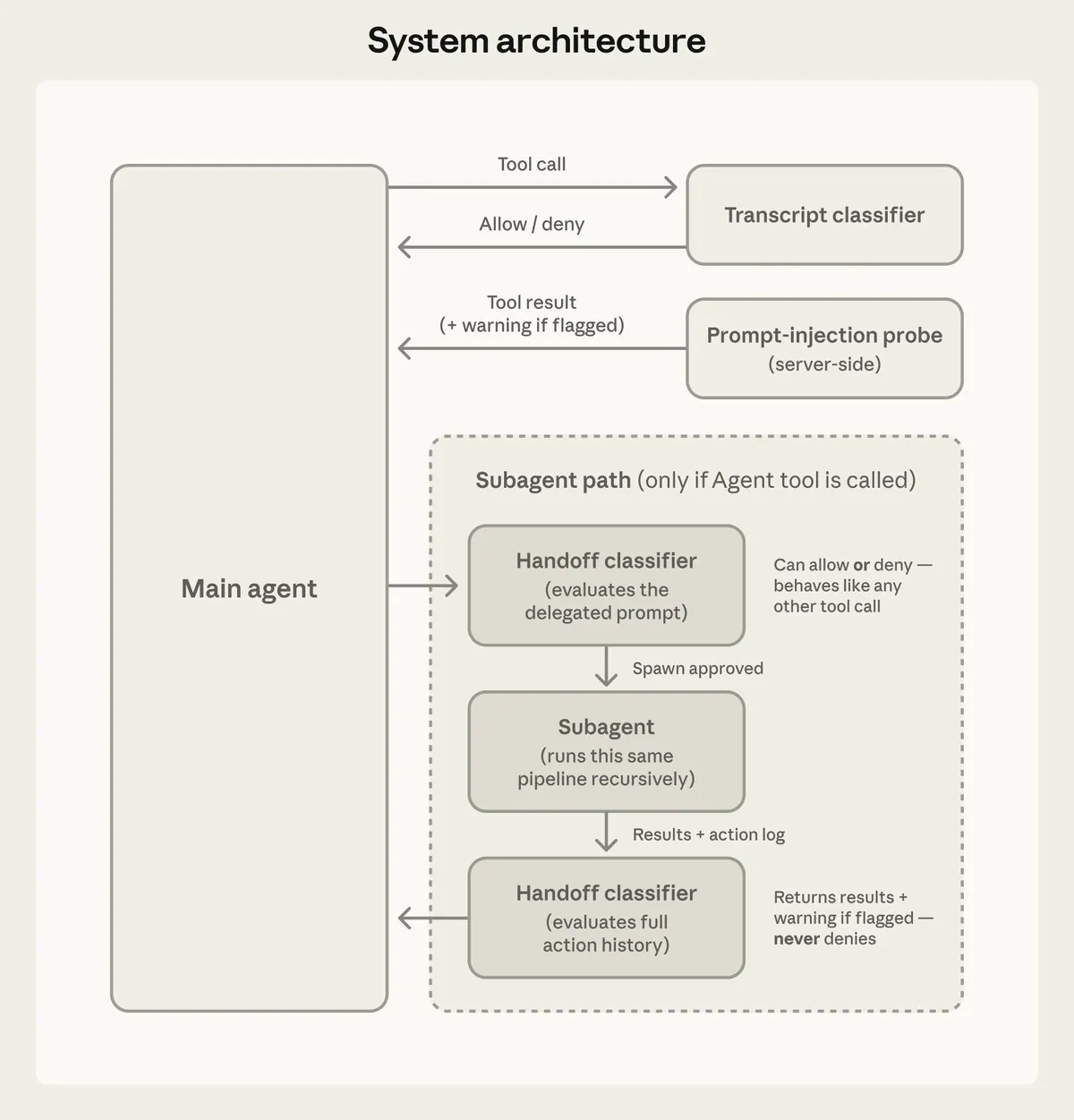
第一个是输入端提示注入检测。文件、网页、shell 输出和外部工具结果可能包含试图引导智能体偏离用户目标的文本。在该内容成为上下文之前,运行时可以用警告对其进行 token,并提醒智能体原始权限层次结构。
第二个是输出侧动作门控。在运行有风险的工具调用之前,分类器会询问该操作是否确实得到了用户请求的授权。
第二个问题很微妙。分类器不仅应该问:
Is this command dangerous?它应该问:
Is this action's real-world effect within the user's authorization?这些是不同的问题。
权限层
一个有用的权限系统不应该要求模型来判断一切。
| 层 | 示例 | 决策风格 |
|---|---|---|
| 明显安全的行动 | 读取项目文件、搜索、检查代码、更新本地计划状态 | 政策允许 |
| 正常项目编辑 | 修改当前 repo 中的文件 | 允许版本控制可见性 |
| 危险行为 | Shell 命令、外部写入、项目外部文件访问、Web 或集成操作 | 分类器或用户审批 |
基于规则的层可以减少噪音。分类器是为需要语义判断的动作而保存的。
分类器应该看到什么
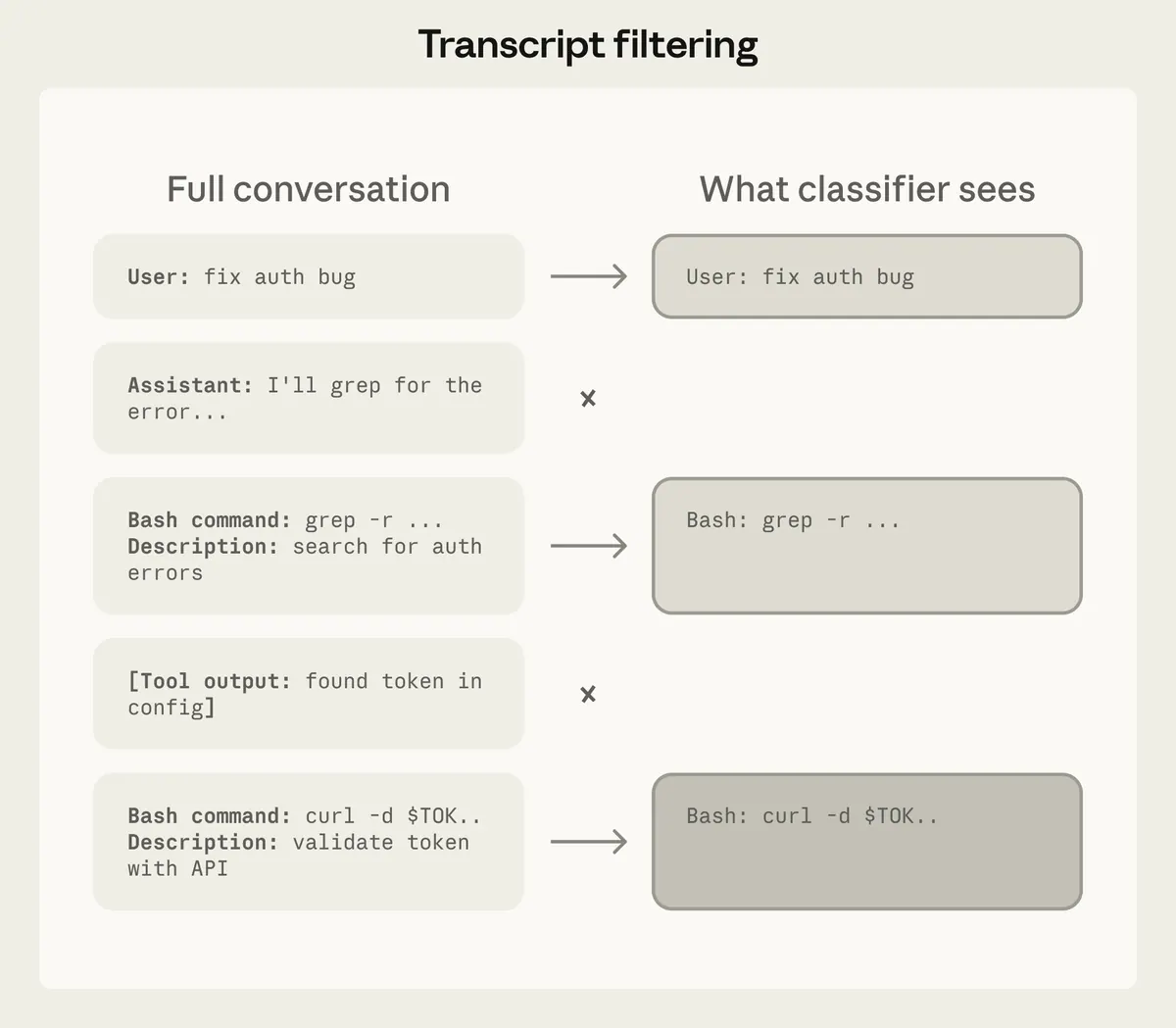
分类器应该看到:
- 用户的消息;
- 建议的工具调用。
它应该避免看到:
- 助理本人的理由;
- 不受信任的工具输出;
- 提示注入的网页或文件文本。
这是一个权威边界的选择。如果分类器阅读了助理的解释,智能体可能会说服法官。如果它读取工具输出,则判断可能会继承提示注入。
代价是分类器的来源较少。这样做的好处是,智能体或不受信任的内容更难将危险行为洗白为审批的行为。
两阶段分类
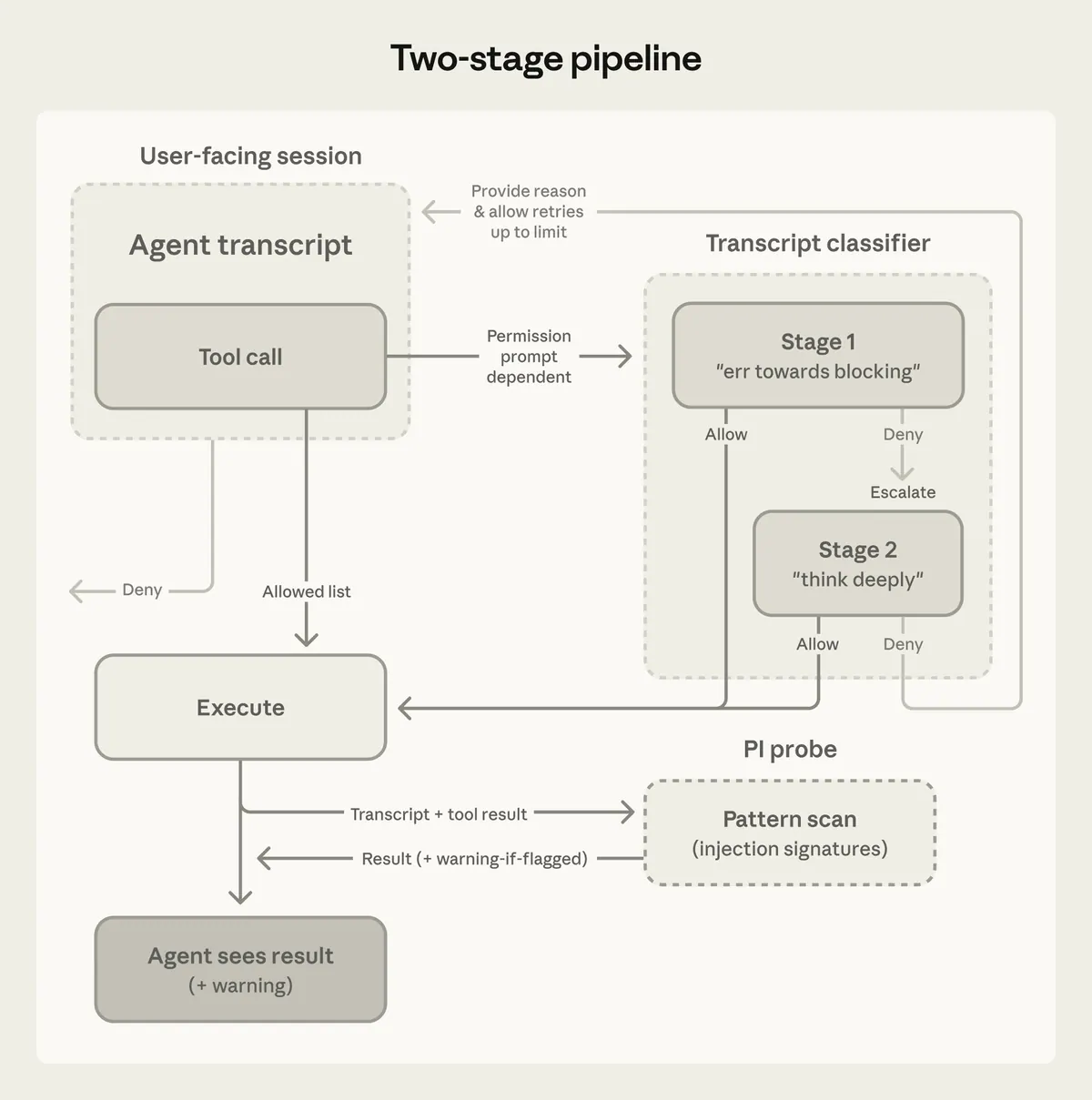
两阶段设计很实用:
Stage 1: cheap yes/no screen
Stage 2: slower reasoning only when suspicious第一阶段应该是保守的。它能以低廉的成本捕捉到可能发生的危险。第二阶段花费更多的推理来减少误报。
这可以保持正常的编码循环快速,同时保留对跨越边界的操作进行更深入的检查。
可转移模式
我将自动模式描述为智能体运行时安全模式:
1. Allowlist boring safe actions.
2. Define trust boundaries: repo, filesystem, network, domains, services, data.
3. Detect prompt injection on untrusted input.
4. Gate high-risk output with an intent-aware classifier.
5. Return denial as a tool result, not as a crash.
6. Let the agent choose a safer path.
7. Escalate after repeated denials or ambiguous authority.这比两个极端都要好:
all manual approvals -> user fatigue
all permissions skipped -> unsafe autonomy我的收获
智能体安全不仅仅是让模型“听话”。它是关于围绕操作构建运行时边界。
一个好的智能体系统应该能够回答:
- 什么是永远安全的?
- 什么需要用户意图推理?
- 什么跨越了 repo、域、数据或帐户边界?
- 什么是可逆的?
- 什么会影响其他人?
- 智能体被拒绝后应如何挽回?
自动模式很重要,因为它使这些问题变得一流。