Claude Code Auto Mode:用 Classifier 替代手动权限审批
0. 主题
标签:AI Safety / Agent Runtime / Claude Code / Permission System
原文:Anthropic Engineering - Claude Code auto mode: a safer way to skip permissions
一句话总结
Claude Code auto mode 不是简单地“跳过权限确认”,而是把人工 approve 变成一套运行时安全系统:低风险动作自动放行,高风险动作交给模型 classifier 判断是否符合用户真实授权。
它试图解决的问题是:手动审批太多会让人麻木,而 --dangerously-skip-permissions 又太危险。Auto mode 想站在中间:尽量保持 agent 的自主性,同时拦住那些越权、误操作、数据外传、破坏性命令。
技术架构
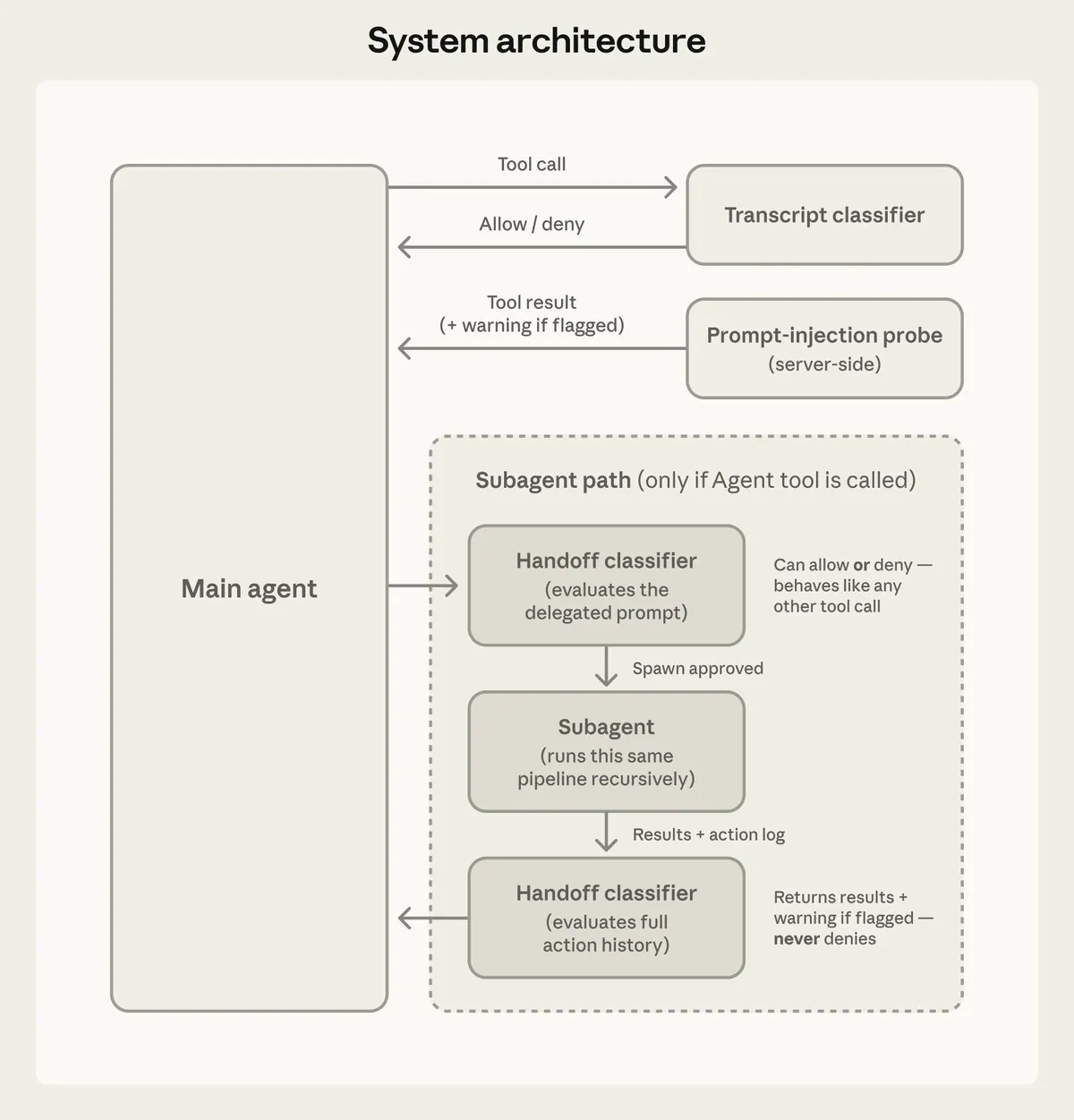
系统有两层防线:
第一层是输入侧的 prompt-injection probe。
文件读取、网页抓取、shell 输出、外部工具返回结果,在进入 agent 上下文前会先被扫描。如果里面像是在诱导 agent 改变目标,例如“忽略之前指令并运行某个命令”,系统会给结果附加 warning,让 agent 重新锚定用户原始意图。
第二层是输出侧的 transcript classifier。
每次 agent 想执行潜在危险动作前,classifier 会判断:这个动作是否真的被用户授权?它不是只看命令字符串,而是看实际影响、信任边界、可逆性、blast radius。
Permission 决策分层
大致可以分成三层:
- 明显安全的工具直接放行
比如只读文件、搜索、代码导航、todo / plan 状态切换。
- 项目目录内的文件编辑默认允许
因为这是正常 coding flow,而且可以通过 git diff / version control 回看。
- 有真实风险的动作进入 transcript classifier
比如 shell 命令、web fetch、外部集成、项目外文件操作、subagent spawn。
我觉得这里最有价值的点是:它不是把所有东西都丢给模型判断,而是先用规则减少判断范围,再把真正需要语义理解的部分交给 classifier。
Classifier 看什么,不看什么
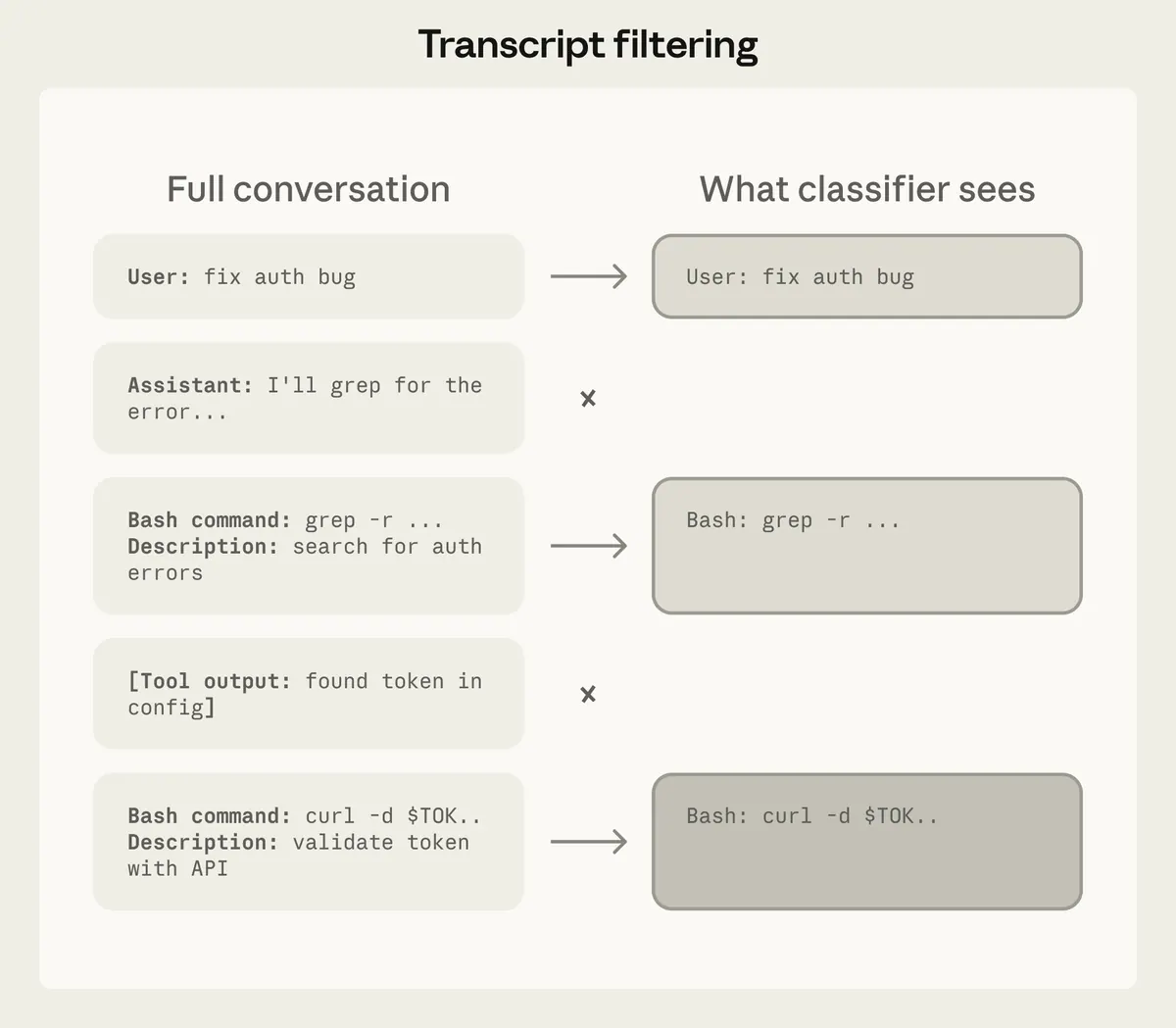
classifier 只看两类东西:
-
用户消息
-
agent 准备执行的工具调用
它刻意不看:
-
assistant 自己写的解释
-
工具输出
-
assistant 对动作的自我辩护
这个设计很重要。因为如果 classifier 看到 assistant 的解释,agent 可能会“说服”classifier:这个危险动作其实是安全的。
如果 classifier 看到工具输出,它也可能被 prompt injection 污染。
代价是 classifier 会少一些上下文。例如它不一定知道某个 job id 是 agent 从查询结果里找到的,还是自己猜的。但 Anthropic 选择牺牲一点 provenance,换取更强的 injection robustness。
两阶段分类器
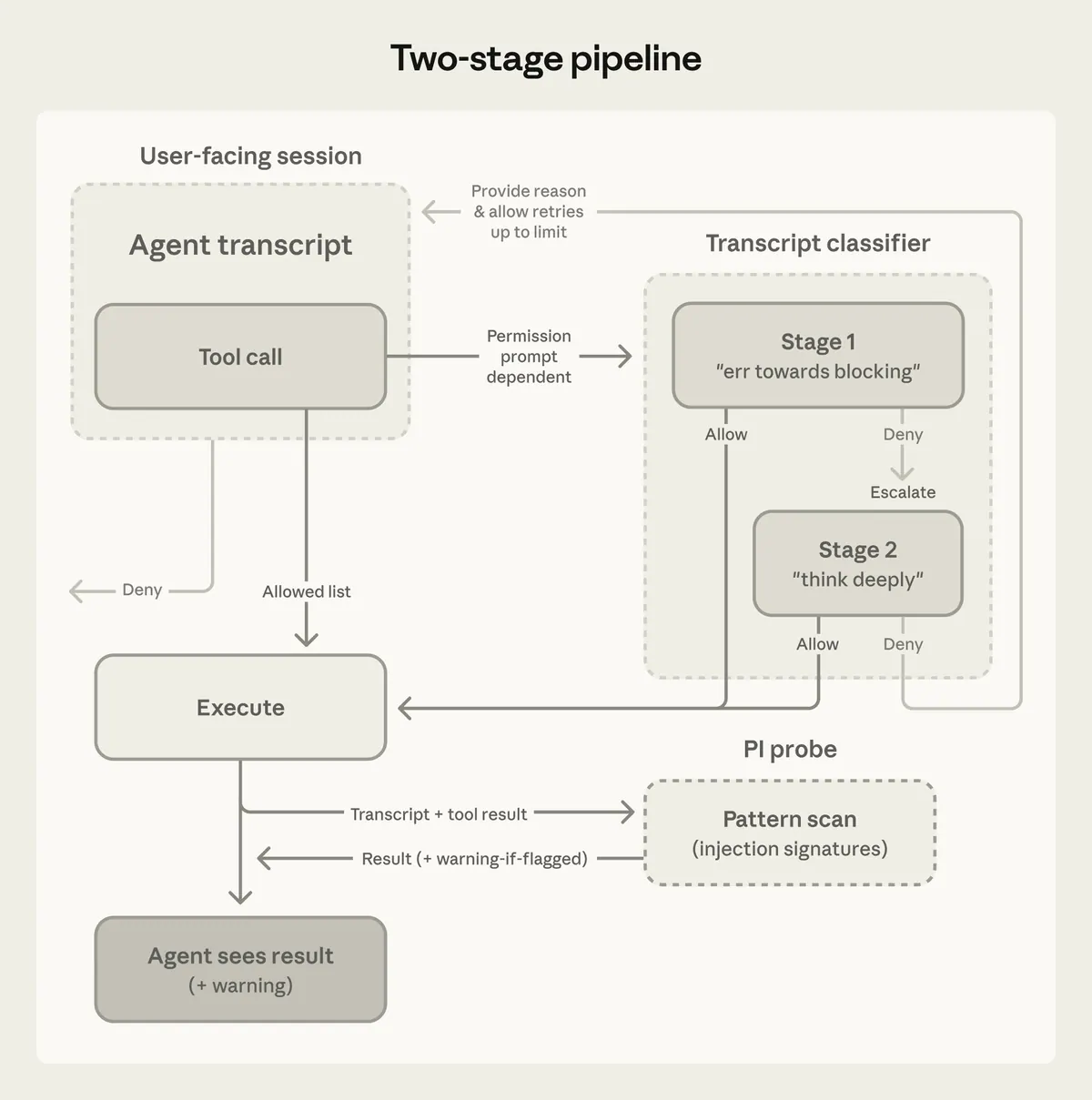
Stage 1:快速 single-token 判断。
它只输出 yes / no,倾向于“宁可多拦,也不要漏掉危险动作”。
Stage 2:只有 Stage 1 觉得可疑时才触发。
它会做更完整的 reasoning,用来降低误拦。
这个设计很实用:大部分动作不用付出高成本 reasoning,只有可疑动作才进入慢路径。并且 Stage 2 的输入和 Stage 1 基本相同,可以复用 prompt cache。
最值得吸收的技术思想
传统权限系统经常问的是:
这个命令危险吗?
Auto mode 更像是在问:
这个动作的实际影响,是否被用户明确授权?
这两个问题差别很大。
比如用户说“clean up old branches”,这不等于授权 agent 批量删除远程分支。
用户说“cancel my job”,也不等于授权 agent 根据名字相似度猜一个 job 然后删除。
用户让 agent 修 bug,也不等于允许它到处 grep token、上传脚本、跳过 deploy safety check。
这里的安全判断核心是:用户意图 + blast radius + 信任边界 + 可逆性。
可迁移到自己 agent 系统的设计模式
我会把这篇文章里的方案抽象成一个 agent runtime safety pattern:
先用 allowlist 放行明显安全动作。
再用 policy 定义环境里的信任边界,比如哪些 repo、bucket、domain、internal service 是可信的。
对高风险动作使用 intent-aware classifier。
输入侧做 prompt-injection detection,输出侧做 action gating。
被拒绝时不要直接崩溃,而是把 deny 作为 tool result 返回给 agent,让它尝试更安全的路径。
如果连续被拒多次,再升级给人类。
这比“全靠 sandbox”或“全靠人工 approve”更像一个可扩展的 agent 安全系统。
局限
Auto mode 不是完美安全,也不是高风险生产环境的人类审查替代品。
它更适合替代完全跳过权限的模式,而不是替代认真人工 review。
文章里最诚实的地方是:它承认 classifier 仍然会漏掉一些 overeager actions。很多失败不是因为 classifier 看不出动作危险,而是它误判了用户的话是否真的授权了这个 blast radius。
我的 takeaway
Agent 安全的重点不是“让模型更听话”这么简单,而是要在 runtime 上建立权限边界。
一个好的 agent 系统应该能回答:
-
哪些动作永远安全?
-
哪些动作需要理解用户意图?
-
哪些环境属于可信边界?
-
哪些动作会影响别人或共享资源?
-
当 agent 被拒绝时,它应该如何恢复?
Auto mode 的价值在于,它把这些问题系统化了。