Codex 源码阅读(III):子智能体是一棵线程树
副标题:从委托到持久线程树。
第一篇文章说,Codex 的智能体循环不是一个简单的 while tool 演示。turn 是受管理的运行时边界。
第二篇文章说,目标不是提示词,而是线程级的长期状态机,有持久性、延续门、记账和权限边界。
第三篇继续同一个故事:当一项任务对一个 turn 来说太大、对一个智能体来说太宽,无法线性推进时,会发生什么?
浅显的答案是:模型调用 spawn_agent,Codex 并行运行一些额外的模型调用。
这个答案忽略了设计。
Codex 子智能体不是临时工具调用,而是会话级线程树里的持久子线程。
spawn_agent 只是前门。真正的系统由子线程、分叉历史、智能体路径、邮箱、状态订阅、中断、注册表限制,以及可恢复的父子生成边构成。多智能体支持的核心不是并发,而是生命周期管理。
从具体任务开始。
Migrate the checkout service from the old payment client to the new billing SDK.
Requirements:
1. identify API contract risks;
2. update the adapter and call sites;
3. add integration tests;
4. run the checkout benchmark and confirm p95 does not regress;
5. produce a final risk list with verification evidence.这不是单一的工作。它自然地分为三种形状:
Main path: understand the adapter and decide the patch direction.
Side paths: audit contracts, add tests, run the benchmark.
Integration: merge findings back into the main patch and choose trade-offs.如果根智能体自己做完所有事,速度会很慢,上下文也会被合约细节、测试日志、基准输出和支线调查笔记塞满。如果它只是触发一次性模型调用,副任务就没有持久身份。你无法把这些副任务当作同一棵工作树的一部分来跟踪、中断、列出、恢复或归档。
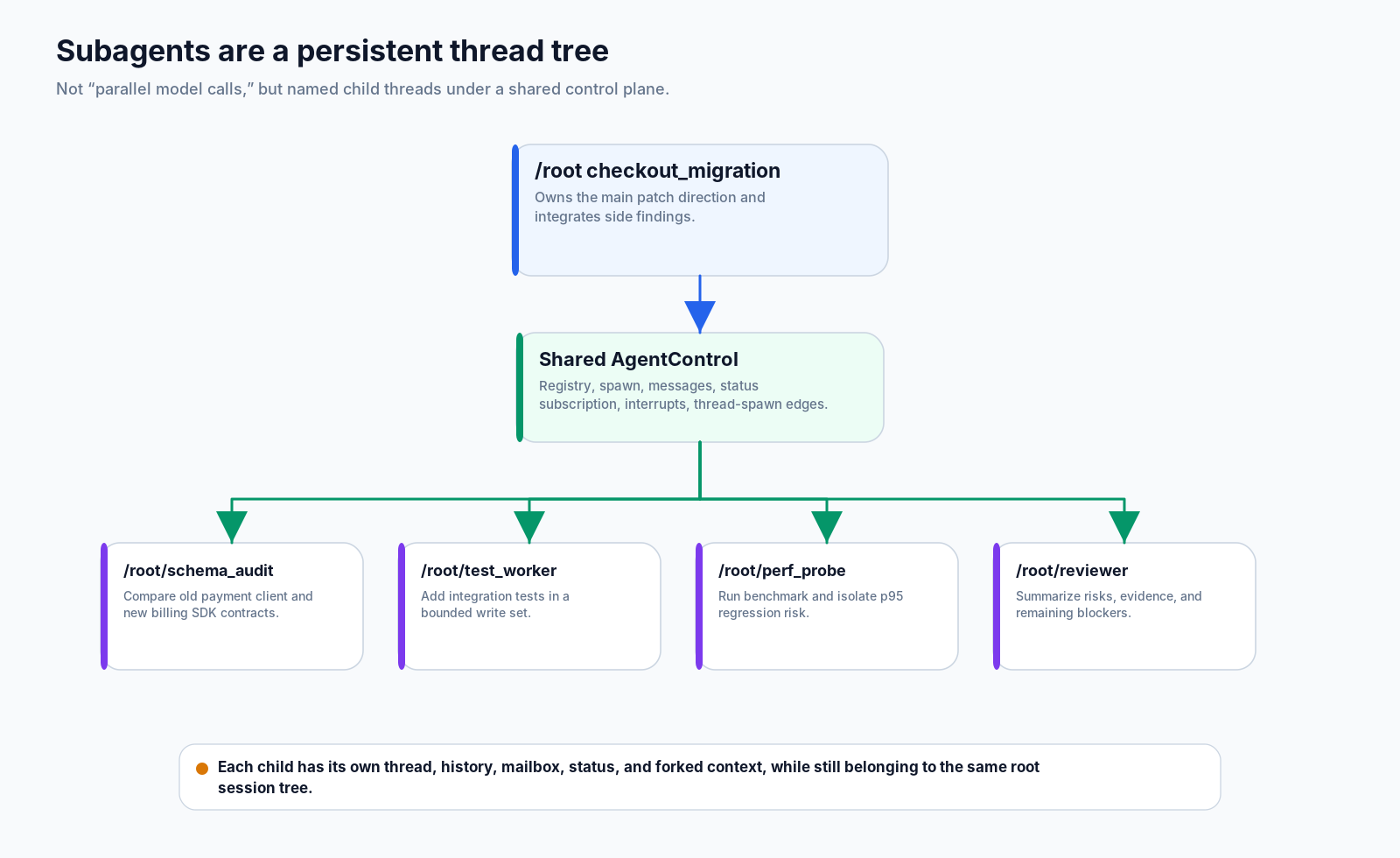
Codex 选择第三种形状:
/root
/root/schema_audit
/root/test_worker
/root/perf_probe根智能体保留主补丁。schema_audit 比较新旧合约。test_worker 在有界写入范围内添加集成覆盖。perf_probe 运行基准并报告 p95 证据。根智能体不必立刻阻塞等待所有结果;它可以继续推进主线,再等待、发送消息、中断,或在结果回来后整合。
这就是主要思想:
Codex 的多智能体不是“让多个模型同时思考”。它是一个根智能体,把工作组织成命名、可恢复的线程树。
1. 首先修复心智模型:子智能体不是后台函数
后台函数如下所示:
result = model.call(task)或者,使用并发:
future = run_model_in_background(task)Codex 子智能体更接近于此:
child_thread = thread_manager.spawn_or_fork_thread(...)
agent_control.register(child_thread, metadata)
persist_edge(parent_thread, child_thread)
send_initial_input(child_thread, message)这种差异是巨大的。
函数调用只活到返回为止。线程可以继续接收消息、运行更多 turn、等待、中断、被列出、从 rollout 中恢复,也可以随父级一起归档或删除。它有地址,也有生命周期。
这就是为什么阅读多智能体代码的最佳切入点不是工具列表。它是AgentControl。
2. AgentControl:多智能体控制平面
AgentControl 是 Codex 多智能体工作的控制平面句柄。它附加到会话服务。更关键是,一个根线程或会话树在所有后代之间共享一个 AgentControl。
该设计决定了系统的形状。
如果每个子智能体都有自己的控制平面,根节点就拿不到团队的稳定视图。子智能体也很难再生成自己的子智能体。状态更新、中断、邮箱和生成边会散落在互不相关的状态里。共享一个 AgentControl,让注册表和通信通道的作用域限定在根树内:它不是全系统所有线程的全局状态,也不是单个 turn 的局部状态。
你可以把它想象成一个小团队调度程序:
AgentControl
- spawn an agent
- send input and inter-agent messages
- interrupt an agent
- subscribe to agent status
- list agents in the tree
- record parent -> child thread-spawn edges
- restore descendant agents when a session resumes它不是 worker 本身。每个智能体线程仍然运行自己的常规 turn、工具运行时和历史记录。AgentControl 管理的是存在性、身份、通信和生命周期。
这与之前的帖子有明确的联系:
run_turn -> one model/tool/history loop
RegularTask -> one turn's outer lifecycle
Goal runtime -> long-running objective state
AgentControl -> multi-thread agent tree control plane将这些层分开,多智能体代码将变得更容易阅读。
3. AgentRegistry:容量和身份是运行时特性
AgentControl 背后最重要的部分之一是 AgentRegistry。
这个名字听起来像一个简单列表,但它承担的事情更多。
第一,它限制容量。会话树不能生成无限多的子智能体。注册表会跟踪总数,并在接纳新子智能体前预留生成名额。如果达到上限,生成就会失败。这是安全边界。没有它,一个能递归生成智能体的模型可能把多智能体系统变成资源爆炸。
第二,它保持身份。注册表将智能体路径映射到元数据,例如:
agent_id
agent_path
agent_nickname
agent_role
last_task_message第三,它给智能体提供可读名称。用户和模型不必只面对不透明的线程 ID。角色可以提供候选昵称,运行时可以分配可读名称,并在重名时加后缀。
这解决了两个核心问题:
Capacity: how many agents may exist in this session tree?
Addressability: how does one agent refer to another agent reliably?没有容量控制,多智能体系统会失控。没有可寻址性,沟通会退化成“文本某处有个 worker 说了点什么”。Codex 选择把智能体建模为线程树中的实体。
4. task_name 和 AgentPath:子智能体需要一个路径,而不仅仅是一个 id
多智能体 spawn_agent 接口需要 task_name 和 message。这个细节并不是装饰性的。
task_name 成为规范智能体路径的一部分。如果当前智能体是:
/root它产生:
{
"task_name": "schema_audit",
"message": "Compare the old payment client contract with the new billing SDK."
}新子智能体的路径可以是:
/root/schema_audit如果 /root/migration_worker 再生成 validator,子级会变成:
/root/migration_worker/validator这就是树的来源。
路径需要规则。它们必须从 /root 开始;路径段必须稳定;保留名称和含糊的路径片段必须被拒绝。这不是吹毛求疵的校验,而是通信语义。智能体需要一条运行时和模型都能一致解析的路径。
后台作业可以只靠不透明 ID 存活。协作智能体需要一个能用于消息、等待、后续任务和中断的名字。
5. spawn_agent:从工具调用到线程物化
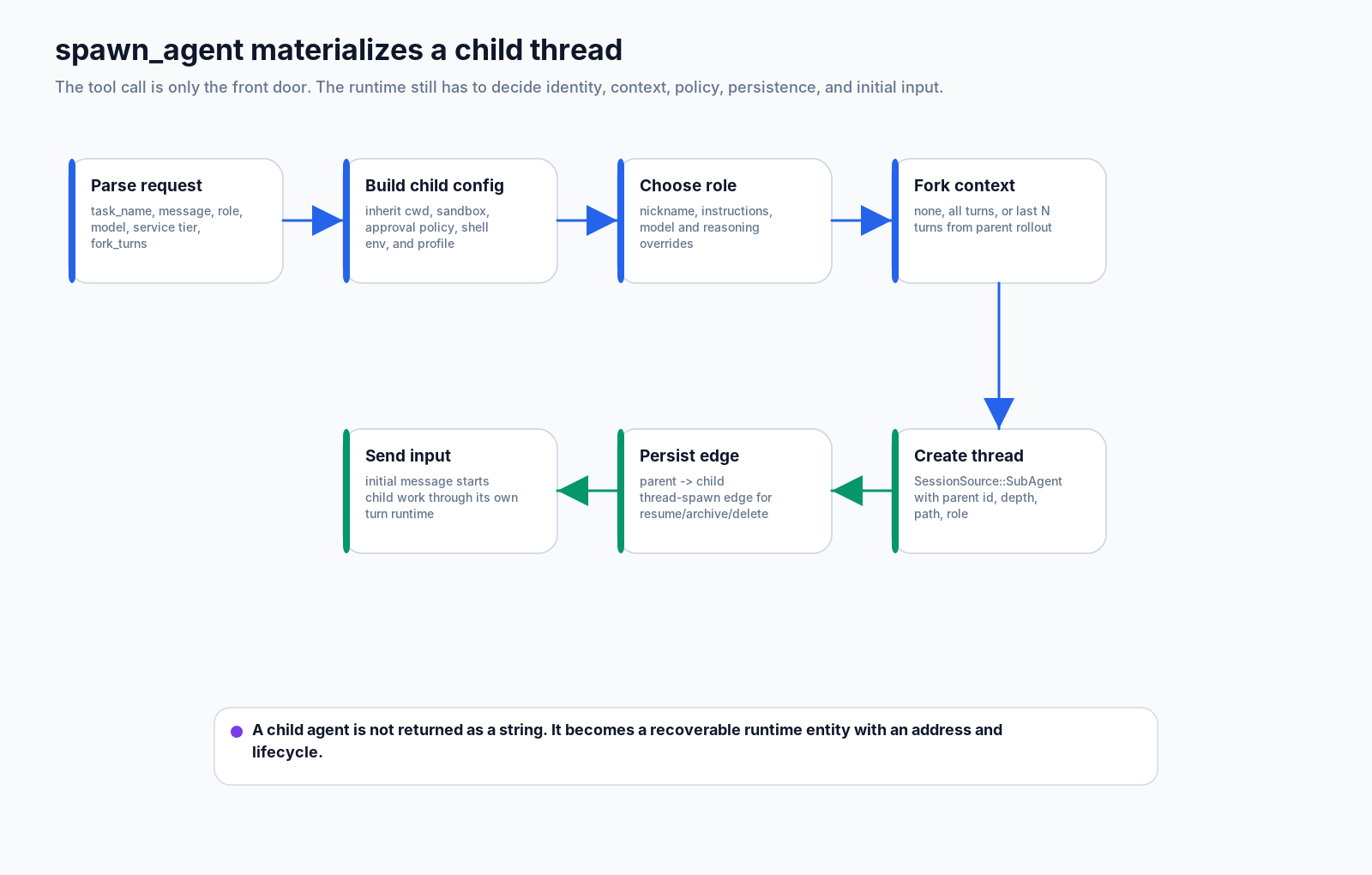
回到入口点。spawn_agent handler 做的事,远不止把任务字符串传给另一个模型。
一个有用的骨架是:
parse arguments:
message, task_name, agent_type, model, reasoning_effort, service_tier, fork_turns
parse fork mode:
none / all / last N turns
build child configuration from the parent turn:
cwd, sandbox, approval policy, permission profile, shell environment policy
apply role and model overrides:
role config, nickname, instructions, reasoning, service tier
construct subagent source:
parent_thread_id, depth, agent_path, agent_role
call AgentControl.spawn_agent_with_metadata
persist parent-child edge
send initial input to the child thread真正的工作是设定边界。
子智能体继承哪些背景?这由 fork_turns 决定。
它发挥什么作用?即 agent_type 和角色配置。
它使用哪种模型和推理设置?默认值可以从父级继承,但某些分支可以覆盖。
它在哪里执行?它继承当前运行时世界:工作目录、沙箱、审批策略、权限配置文件、选定环境和 shell 策略。
后期将如何解决?它接收路径、昵称、角色、父 ID 和深度。
以后还能恢复吗?父子生成边缘被保留。
这些设计都不是“并行调用模型”能概括的。
6. 继承不是省事,而是在保留执行世界
子智能体从父智能体继承关键运行时状态,包括 shell 快照和执行策略。
这不只是方便,而是正确性。
假设根智能体正在一个 repo 里工作,并带着特定的 cwd、工作区写入沙箱、审批策略和 shell 环境策略。如果子级悄悄在不同目录启动,或使用不同执行策略,它的测试和文件读取就无法和根智能体的工作对齐。子智能体会报告来自另一个世界的事实。
继承让整个团队处在同一个执行现实里。子级仍然可以有自己的历史和角色,但它的工具调用运行在兼容的运行时假设下。
这对编码任务尤其重要。“我运行了基准测试”只有在同一个 repo 状态和策略边界下才有意义,否则证据不能直接用于正在审查的补丁。
7. fork_turns:上下文是一种设计选择
分叉不是复制文本,而是在划上下文边界。
子级任务需要足够上下文才能独立工作,但也不能让每条支线都继承整个父级 rollout。如果基准 worker 收到几页合约审计记录,就是浪费上下文;如果合约审计 worker 没看到迁移限制,又可能漏掉重点。
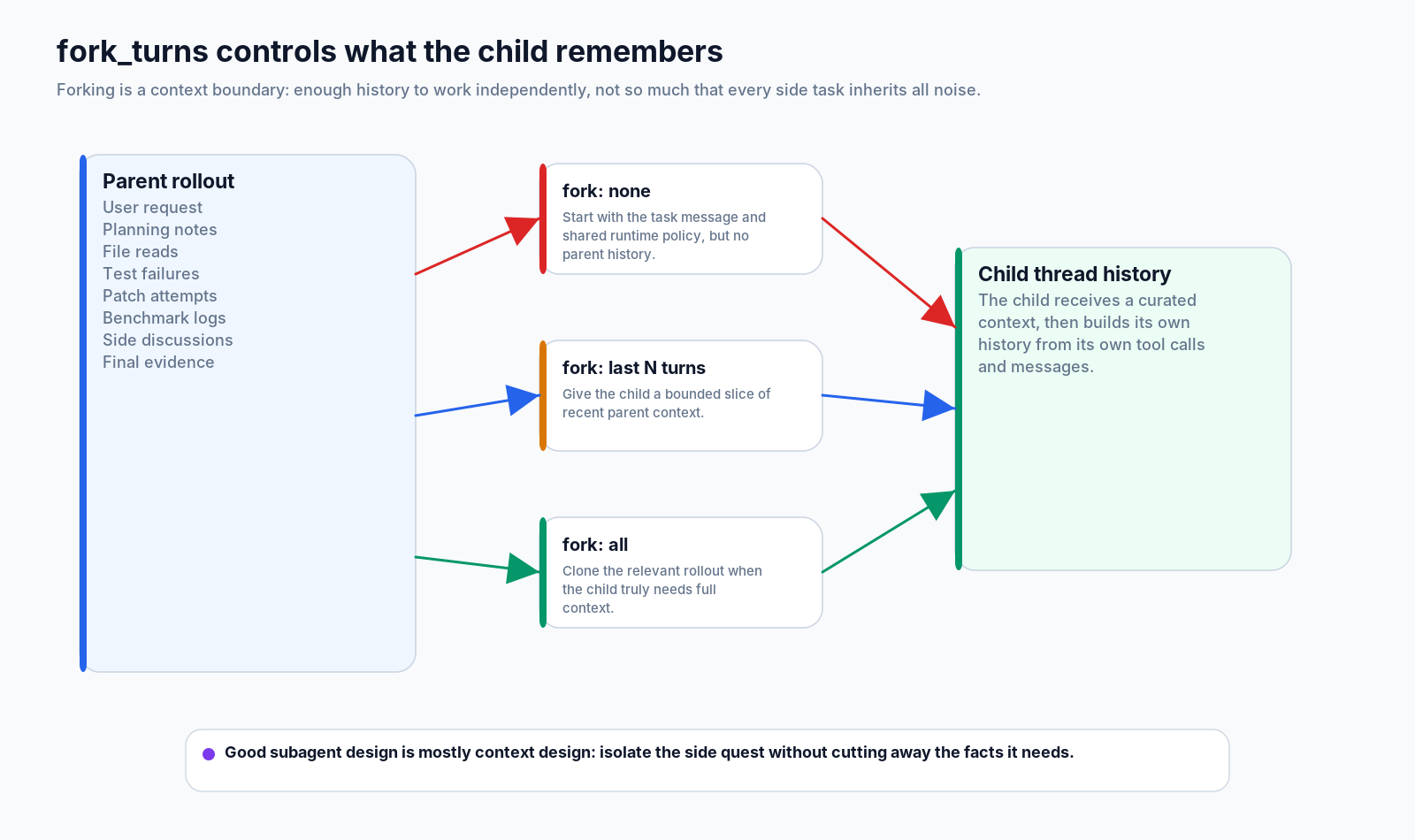
分叉模式编码了权衡:
fork: none -> child starts from task message and runtime policy
fork: last N -> child receives a bounded slice of recent parent context
fork: all -> child receives the relevant rollout when full context is necessary关键在于,子智能体分叉后的历史就是它自己的历史。它会记录自己的工具调用、证据、消息和错误。父级可以稍后阅读或等待,但子智能体不是父级提示词里的一个段落。
好的子智能体设计,很大一部分是上下文设计。支线任务要窄到能完成,也要和主线保持足够连接,才有用。
8.通信:发送、触发、等待、中断不一样
只要子智能体还活着,父级就需要不止一种互动方式。
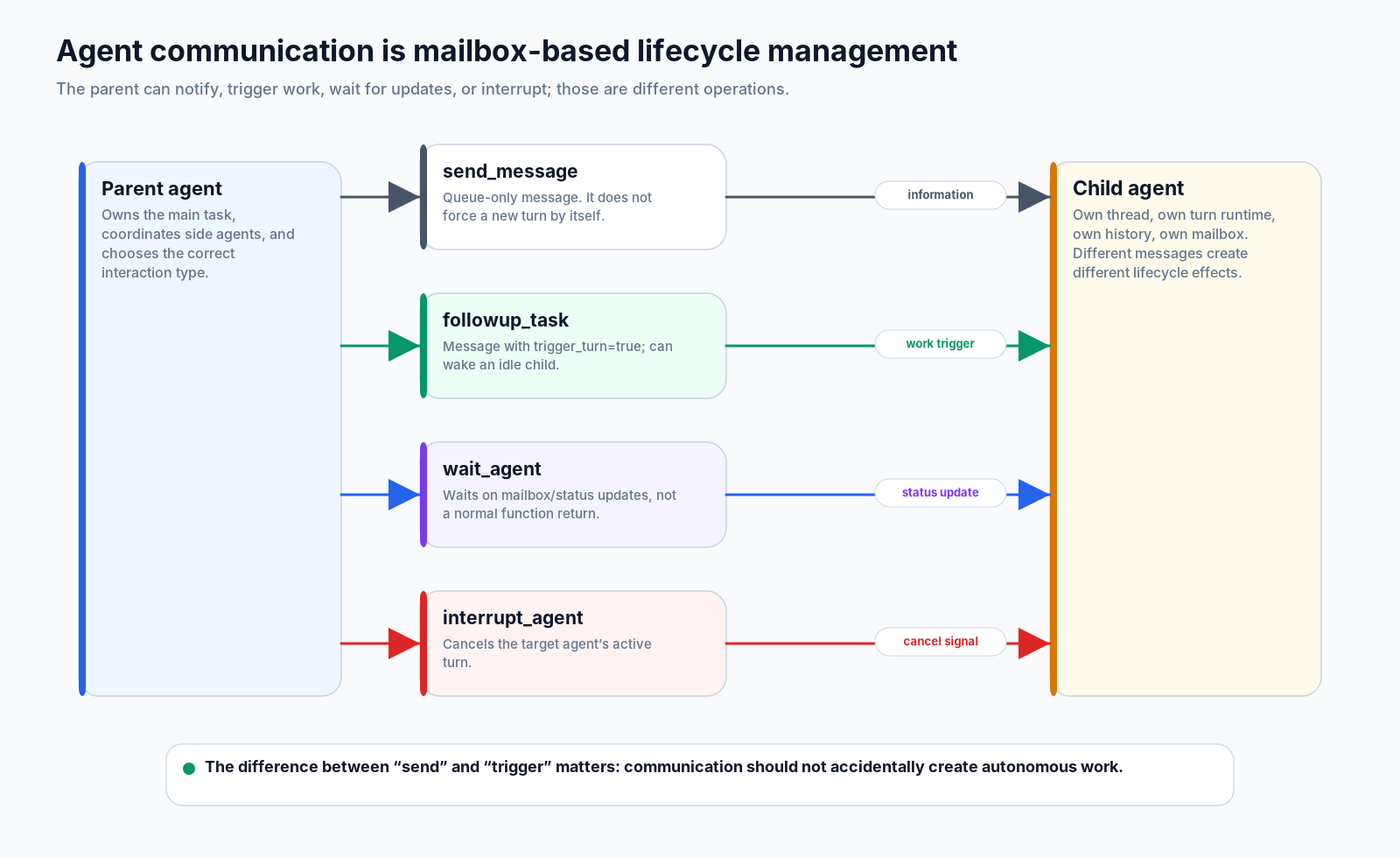
send_message 只入队。它把一条消息放进目标智能体的邮箱,但本身不应该强制开启新的 turn。当子智能体已经在工作,或消息只是提供参考时,这很有用。
followup_task 不一样。它带有触发语义,可以唤醒空闲子级来处理新任务。这个区别可以避免意外自治:不是每条消息都应该制造更多工作。
wait_agent 也不同于普通函数返回。父级等待的是运行时实体的邮箱或状态更新;这些实体可能仍在工作,也可能阻塞、中断或完成。
interrupt_agent 取消目标智能体的 active turn。它是尊重生命周期边界的多智能体操作:子级不是字符串结果;它正在运行的工作可能需要被认真停下。
一个有用的总结:
| 操作 | 意义 |
|---|---|
send_message | 把信息放入目标邮箱;不一定唤醒它。 |
followup_task | 用触发语义发送工作;如果目标空闲,可以开始另一轮。 |
wait_agent | 等待子线程的邮箱或状态更新。 |
interrupt_agent | 取消子智能体的 active turn。 |
list_agents | 检查当前已知的智能体树。 |
这张表说明了通信和函数调用的区别。函数调用会返回;智能体会在时间中持续沟通。
9. 完成观察者:结果需要回到父级世界
支线智能体只有在结果能回到父级推理循环时才有用。
这就是完成监视和邮箱更新要做的事。当 schema_audit 完成,根智能体应该收到一条可行动的结构化更新:合约风险、证据、不确定点,也许还有建议的后续行动。当 perf_probe 完成,根智能体应该收到基准输出和解释。结果不只是打印在某处,而是成为父级可以观察和吸收的信息。
这就是树模型重要的原因。父级知道哪个子智能体产生了哪个结果、它扮演什么角色,也知道如何要求澄清。如果 perf_probe 报告 p95 回归,root 可以发送有针对性的后续任务,而不是在对话文本里重新发起一次全局搜索。
10. 恢复:树必须重新长出来
持久性是对某事物是否真正是子智能体还是只是后台任务的最终测试。
如果 app 在 checkout 迁移进行到一半时重启,根线程不应该忘记 schema_audit、test_worker 和 perf_probe 的存在。运行时需要从持久化的线程生成边恢复后代智能体,并重建注册表视图。
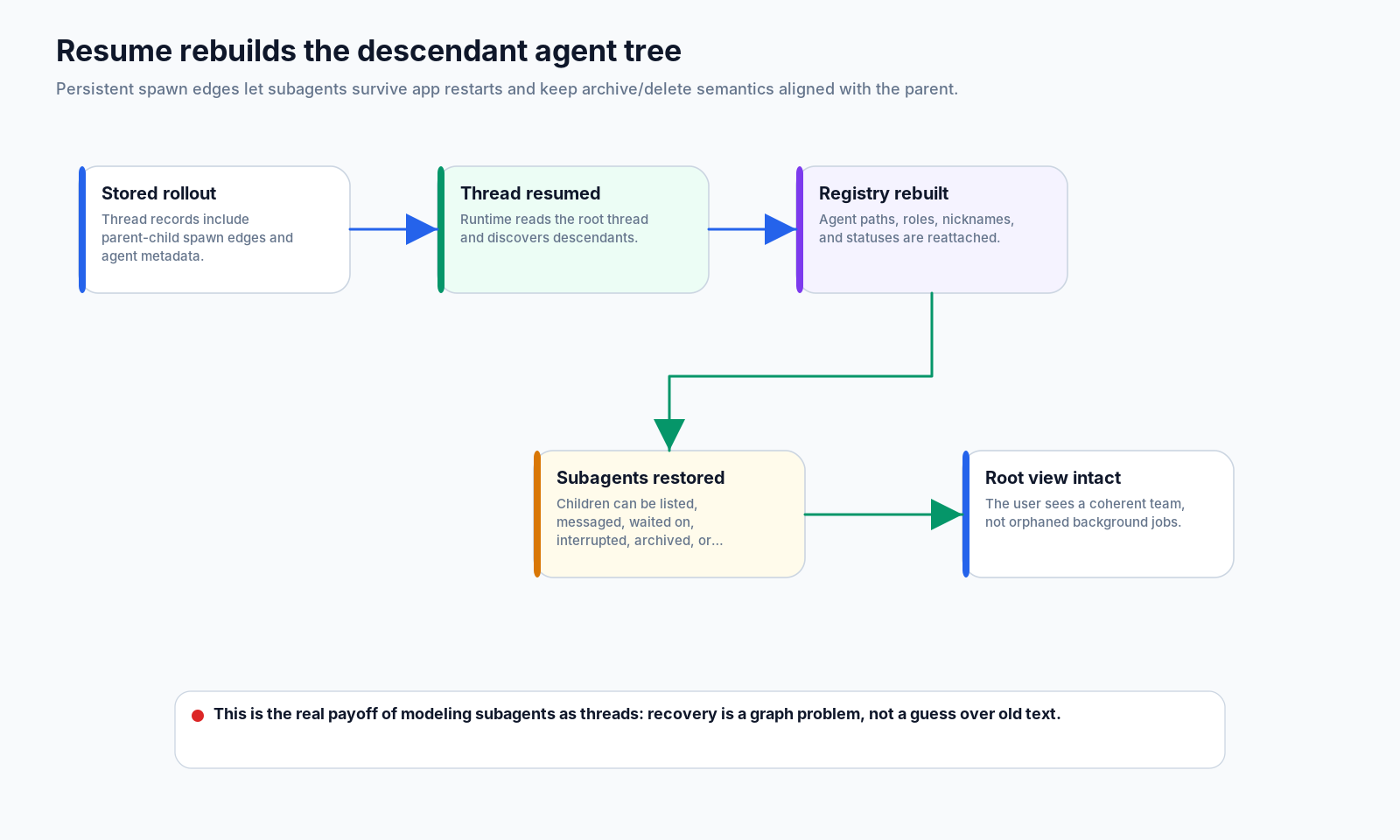
这带来了几个生命周期的好处:
list_agents still shows the team
wait_agent can still refer to a restored child
archive/delete can apply to the whole descendant tree
status can be reconstructed from thread state
messages can continue to use stable agent paths如果子智能体只是临时 future,恢复只能靠猜。有了线程树,恢复就变成了图操作。
11. 这个设计对 Codex 有何说明
Codex 的多智能体设计很有立场:协作是运行时结构,不只是模型提示。
这种结构是有成本的。它需要注册表、路径、分叉模式、邮箱、生成边缘、状态事件和恢复逻辑。但它也提供了一次性并行调用所不具备的系统属性:
| 属性 | 为什么这很重要 |
|---|---|
| 身份 | 可以称呼、列出、等待和打断子智能体。 |
| 上下文边界 | 支线任务可以使用精选视图,而不是继承整个父级 rollout。 |
| 运行时继承 | 子智能体在兼容的执行世界里运行。 |
| 通信 | 智能体可以持续交换消息,而不只是返回字符串。 |
| 容量控制 | 递归生成有一个硬性限制。 |
| 持久性 | 可以用会话树恢复后代。 |
主要的教训是尖锐的:
多智能体支持的重点不是并行性,而是把委托变成可恢复、有边界、可收束的工作。
所以 spawn_agent 不应被理解成“调用另一个模型”。更准确地说,它是在当前根会话树下物化一个子线程。
12. 源代码阅读清单
在阅读 Codex 的子智能体代码时,请使用以下问题:
Which AgentControl instance owns this session tree?
How does AgentRegistry enforce capacity?
What agent path will this child receive?
What role, nickname, model, and reasoning settings are applied?
What parent history is forked, and what is intentionally left out?
Which runtime policy is inherited from the parent?
How does the initial message enter the child thread?
How does the parent receive completion or mailbox updates?
What happens if the child is interrupted?
How is the descendant tree restored on resume?如果能回答这些问题,多智能体系统就不再像一袋工具,而是一套用于协作的树形运行时。
源图
读完这篇文章后需要阅读的有用文件和区域:
codex-rs/core/src/agent/control.rs用于AgentControl和共享控制平面模型。codex-rs/core/src/agent/registry.rs用于容量限制、身份、元数据和昵称处理。codex-rs/core/src/tools/handlers/multi_agents_v2/spawn.rs用于spawn_agent和子线程具体化。codex-rs/core/src/tools/handlers/multi_agents_v2/message_tool.rs用于消息传递、后续、等待和中断语义。- 用于归档、删除、恢复和后代恢复的线程持久性和 app 服务器生命周期代码。