Codex Source Dive (III): subagents are a thread tree
Subtitle: From delegation to a persistent thread tree.
The first post argued that Codex’s agentic loop is not a simple while tool demo. A turn is a managed runtime boundary.
The second post argued that Goal is not a prompt. It is a thread-level long-running state machine with persistence, continuation gates, accounting, and authority boundaries.
This third post continues the same story. What happens when a task is too large for one turn and too wide for one agent to push linearly?
The shallow answer is: the model calls spawn_agent, and Codex runs a few extra model calls in parallel.
That answer misses the design.
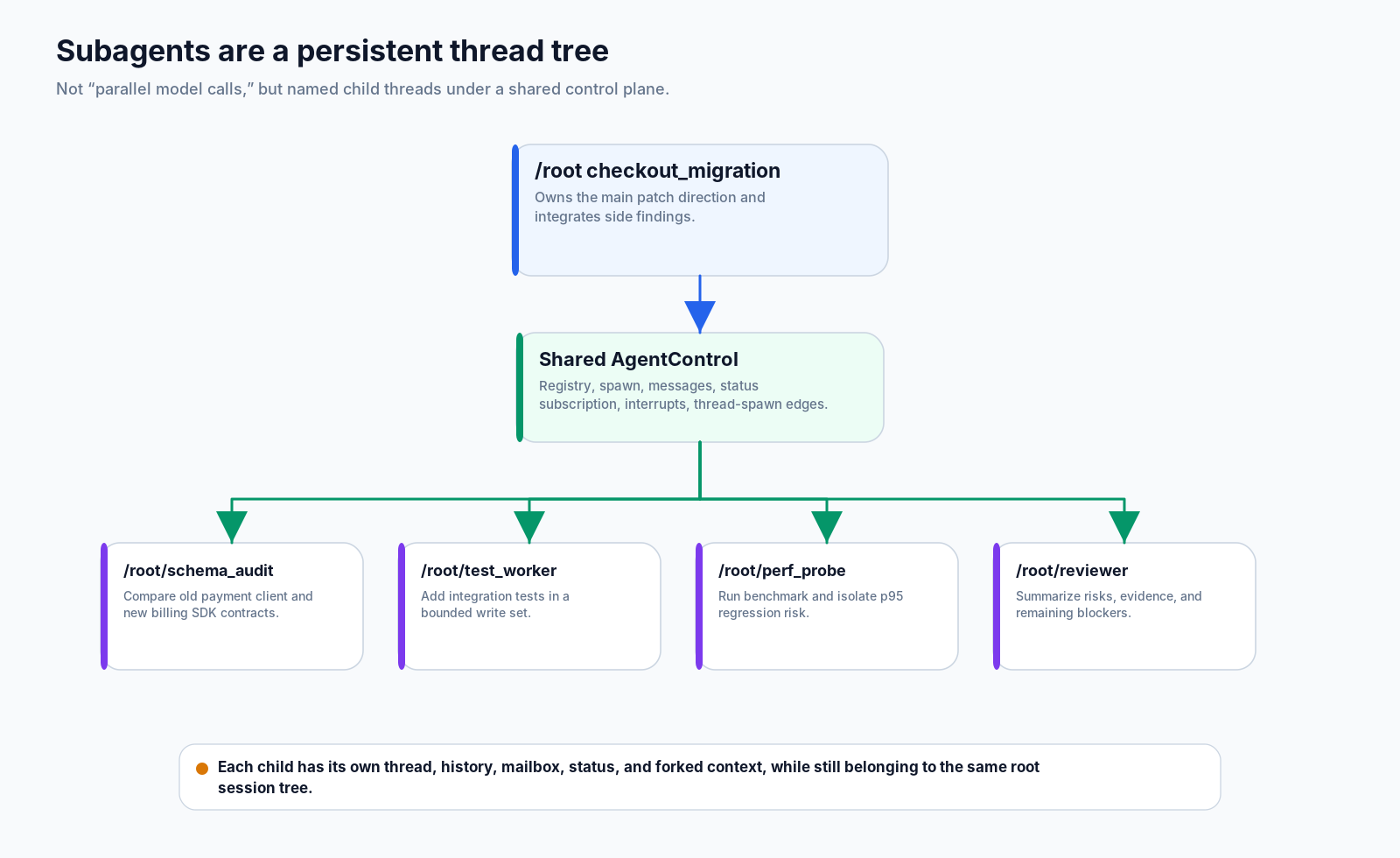
A Codex subagent is not a temporary tool call. It is a persistent child thread in a session-level thread tree.
spawn_agent is only the front door. The real system is built out of child threads, forked history, agent paths, mailboxes, status subscriptions, interrupts, registry limits, and parent-child spawn edges that can be restored later. Multi-agent support is not just concurrency. It is lifecycle management.
Start with a concrete task.
Migrate the checkout service from the old payment client to the new billing SDK.
Requirements:
1. identify API contract risks;
2. update the adapter and call sites;
3. add integration tests;
4. run the checkout benchmark and confirm p95 does not regress;
5. produce a final risk list with verification evidence.This is not a single line of work. It naturally splits into three shapes:
Main path: understand the adapter and decide the patch direction.
Side paths: audit contracts, add tests, run the benchmark.
Integration: merge findings back into the main patch and choose trade-offs.If the root agent does everything itself, it will be slow and its context will fill with contract details, test logs, benchmark output, and side investigation notes. If it fires off one-off model calls, the side tasks have no durable identity. You cannot follow up, interrupt, list, resume, or archive them as part of the same work tree.
Codex chooses a third shape:
/root
/root/schema_audit
/root/test_worker
/root/perf_probeThe root agent keeps the main patch. schema_audit compares old and new contracts. test_worker adds integration coverage in a bounded write set. perf_probe runs the benchmark and reports p95 evidence. The root does not have to block on all of them immediately; it can keep working, then wait, message, interrupt, or integrate as results appear.
That is the main idea:
Multi-agent Codex is not “more models thinking at once.” It is a root agent organizing work as a tree of named, recoverable threads.
1. Fix the mental model first: a subagent is not a background function
A background function looks like this:
result = model.call(task)or, with concurrency:
future = run_model_in_background(task)A Codex subagent is closer to this:
child_thread = thread_manager.spawn_or_fork_thread(...)
agent_control.register(child_thread, metadata)
persist_edge(parent_thread, child_thread)
send_initial_input(child_thread, message)That difference is enormous.
A function call lives until it returns. A thread can keep receiving messages, run more turns, be waited on, be interrupted, be listed, be restored from rollout, and be archived or deleted with its parent. It has an address and a lifecycle.
That is why the best entry point for reading the multi-agent code is not the list of tools. It is AgentControl.
2. AgentControl: the multi-agent control plane
AgentControl is the control-plane handle for Codex multi-agent work. It is attached to session services. More importantly, one root thread or session tree shares one AgentControl across all descendants.
That design determines the shape of the system.
If every subagent had its own control plane, the root would not have a stable view of the team. A child would struggle to spawn its own child. Status updates, interrupts, mailboxes, and spawn edges would scatter across unrelated state. Sharing one AgentControl keeps the registry and communication channels scoped to the root tree: not global to every thread in the system, and not local to a single turn.
You can think of it as a small team dispatcher:
AgentControl
- spawn an agent
- send input and inter-agent messages
- interrupt an agent
- subscribe to agent status
- list agents in the tree
- record parent -> child thread-spawn edges
- restore descendant agents when a session resumesIt is not the worker. Each agent thread still runs its own regular turns, tool runtime, and history. AgentControl manages existence, identity, communication, and lifecycle.
That connects cleanly with the previous posts:
run_turn -> one model/tool/history loop
RegularTask -> one turn's outer lifecycle
Goal runtime -> long-running objective state
AgentControl -> multi-thread agent tree control planeKeep those layers separate and the multi-agent code becomes much easier to read.
3. AgentRegistry: capacity and identity are runtime features
One of the most important pieces behind AgentControl is AgentRegistry.
The name makes it sound like a plain list. It is more than that.
First, it enforces capacity. A session tree cannot spawn unlimited subagents. The registry tracks total count and reserves spawn slots before admitting a new child. If the maximum is reached, spawning fails. That is a safety boundary. Without it, a model that can recursively spawn agents can turn multi-agent into resource explosion.
Second, it maintains identity. The registry maps agent paths to metadata such as:
agent_id
agent_path
agent_nickname
agent_role
last_task_messageThird, it gives agents readable names. Users and models should not have to reason only in opaque thread ids. Roles can provide nickname candidates, and the runtime can allocate readable names, with suffixes when the pool repeats.
That solves two core problems:
Capacity: how many agents may exist in this session tree?
Addressability: how does one agent refer to another agent reliably?Without capacity, multi-agent systems run away. Without addressability, communication degrades into “somewhere in the text, one worker said something.” Codex instead models agents as entities in a thread tree.
4. task_name and AgentPath: a child needs a path, not just an id
The multi-agent spawn_agent interface requires a task_name and a message. That detail is not cosmetic.
task_name becomes part of the canonical agent path. If the current agent is:
/rootand it spawns:
{
"task_name": "schema_audit",
"message": "Compare the old payment client contract with the new billing SDK."
}the new child can be addressed as:
/root/schema_auditIf /root/migration_worker spawns validator, the child becomes:
/root/migration_worker/validatorThat is where the tree comes from.
Paths need rules. They must begin at /root; segments must be stable; reserved names and ambiguous path fragments must be rejected. This is not pedantic validation. It is communication semantics. Agents need paths that both the runtime and the model can resolve consistently.
A background job can survive with an opaque id. A collaborative agent needs a name that can be used in messages, waits, follow-ups, and interrupts.
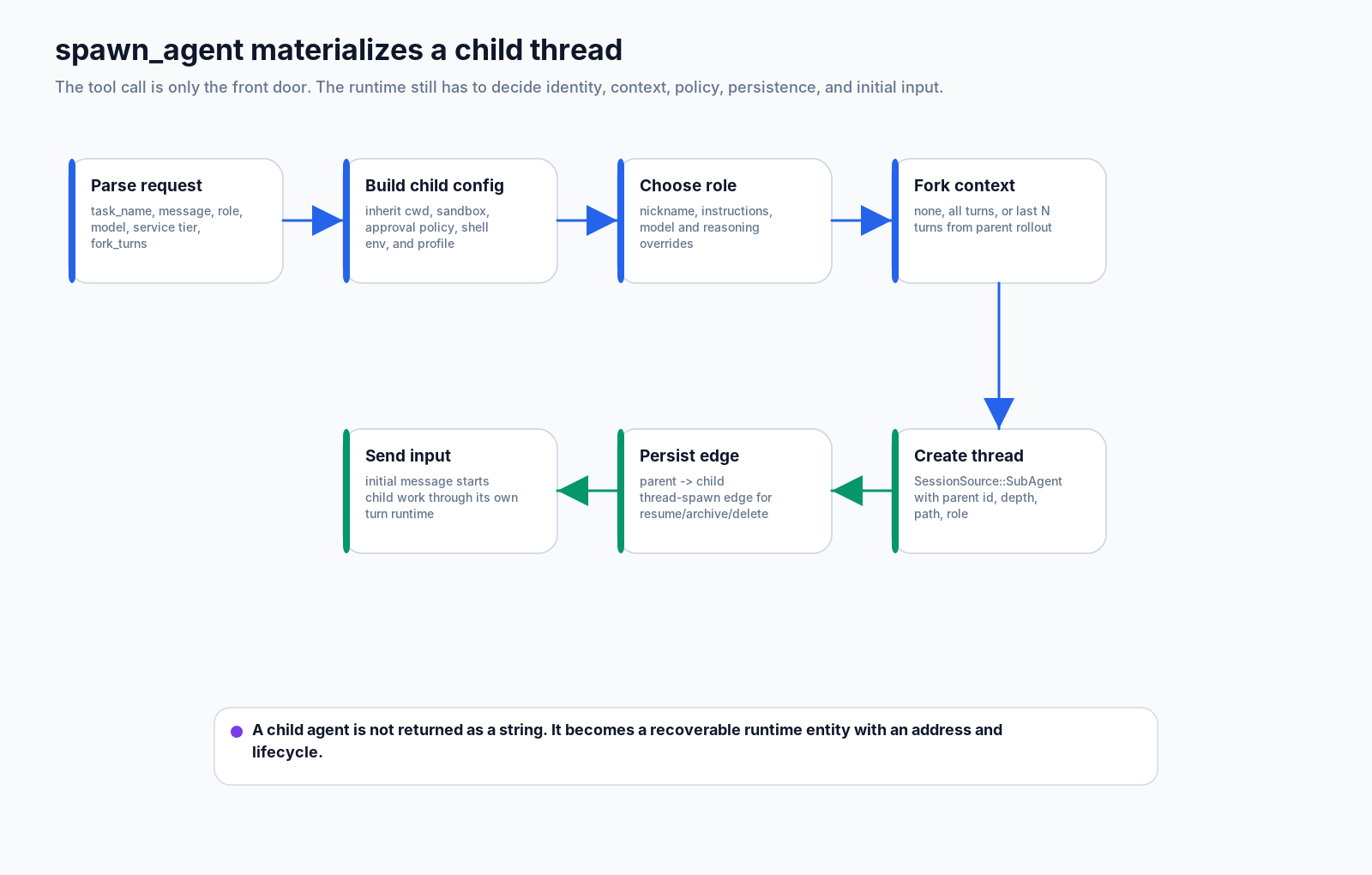
5. spawn_agent: from tool call to thread materialization
Now return to the entry point. The spawn_agent handler has to do much more than pass a task string to another model.
A useful skeleton is:
parse arguments:
message, task_name, agent_type, model, reasoning_effort, service_tier, fork_turns
parse fork mode:
none / all / last N turns
build child configuration from the parent turn:
cwd, sandbox, approval policy, permission profile, shell environment policy
apply role and model overrides:
role config, nickname, instructions, reasoning, service tier
construct subagent source:
parent_thread_id, depth, agent_path, agent_role
call AgentControl.spawn_agent_with_metadata
persist parent-child edge
send initial input to the child threadThe real work is boundary-setting.
What context does the child inherit? That is fork_turns.
What role does it play? That is agent_type and role config.
Which model and reasoning settings does it use? Defaults may inherit from the parent, but some forks can override.
Where does it execute? It inherits the current runtime world: working directory, sandbox, approval policy, permission profile, selected environment, and shell policy.
How will it be addressed later? It receives a path, nickname, role, parent id, and depth.
Can it be recovered later? The parent-child spawn edge is persisted.
None of those ideas fit into “parallel call the model.”
6. Inheritance is not laziness; it preserves the execution world
Subagents inherit key runtime state from the parent, including the shell snapshot and execution policy.
That is not convenience. It is correctness.
Suppose the root agent is working inside a repository with a particular cwd, workspace-write sandbox, approval policy, and shell environment policy. If a child silently starts in a different directory or with a different execution policy, its tests and file reads may not be comparable to the root’s work. The child would report facts from a different world.
Inheritance keeps the team in the same operating reality. The child can still have its own history and role, but its tool calls run under compatible runtime assumptions.
This is especially important for coding tasks, where “I ran the benchmark” only means something if it was run in the same repo state and policy envelope as the patch being reviewed.
7. fork_turns: context is a design choice
Forking is not just copying text. It is a context boundary.
A child needs enough context to work independently, but not so much that every side task inherits the entire parent rollout. If the benchmark worker receives pages of contract-audit notes, it may waste context. If the contract auditor receives no migration constraints, it may miss the point.
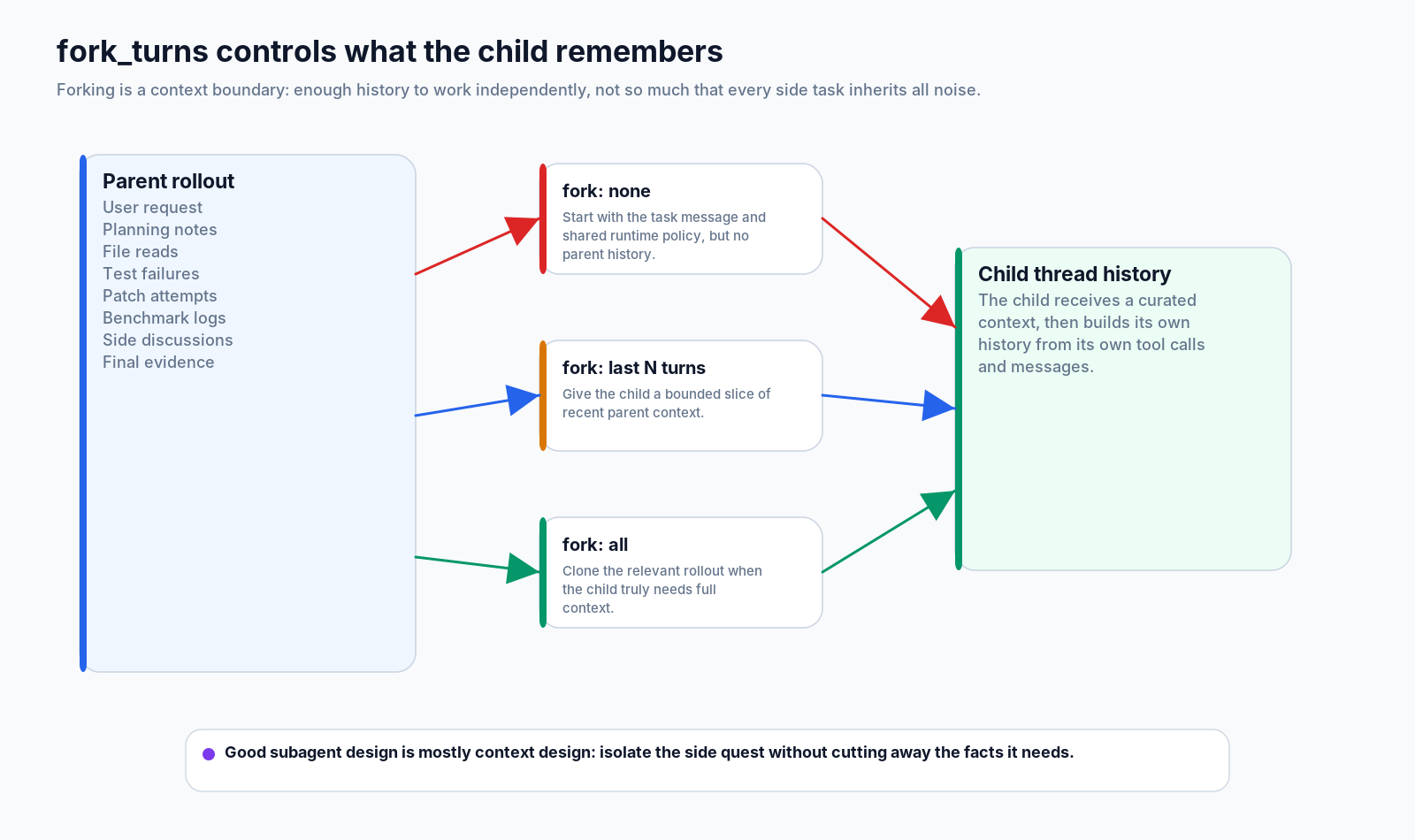
The fork mode encodes the trade-off:
fork: none -> child starts from task message and runtime policy
fork: last N -> child receives a bounded slice of recent parent context
fork: all -> child receives the relevant rollout when full context is necessaryThe important point is that the child’s history becomes its own after the fork. It will record its own tool calls, evidence, messages, and mistakes. The parent can later read or wait on it, but the child is not just a paragraph inside the parent’s prompt.
Good subagent design is mostly context design. You want a side quest that is narrow enough to finish, but connected enough to be useful.
8. Communication: send, trigger, wait, and interrupt are not the same
Once a child is alive, the parent needs several kinds of interaction.
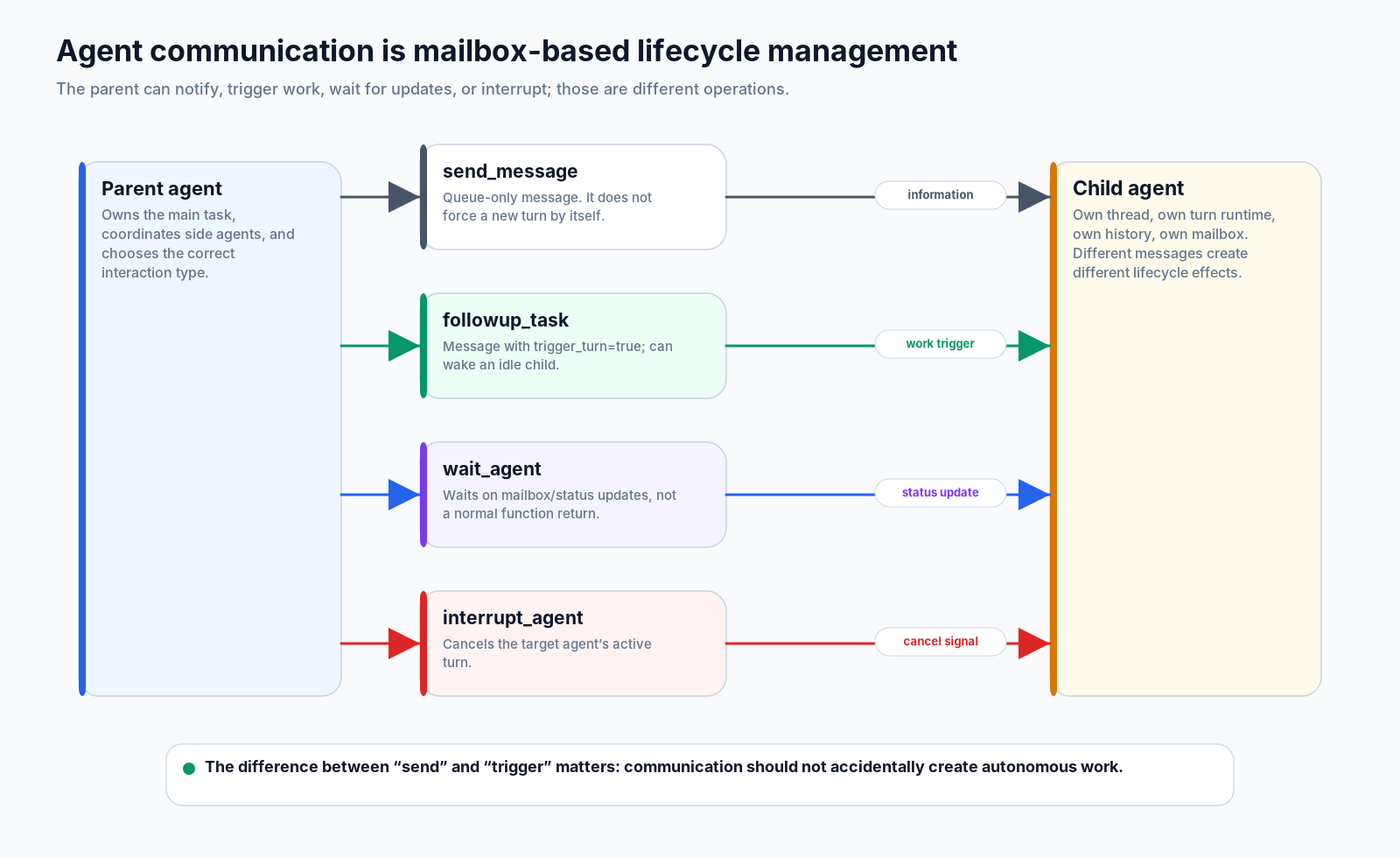
send_message is queue-only. It puts a message into the target agent’s mailbox, but it should not by itself force a new turn. That is useful when the child is already working or when the message is informational.
followup_task is different. It sets trigger semantics, so an idle child can be woken to process the new task. This distinction prevents accidental autonomy. Not every message should create more work.
wait_agent is also different from a normal function return. The parent waits for mailbox or status updates from a runtime entity that may still be working, blocked, interrupted, or completed.
interrupt_agent cancels the target agent’s active turn. It is the multi-agent version of respecting the lifecycle boundary: a child is not a string result; it is running work that may need to be stopped cleanly.
A useful summary:
| Operation | Meaning |
|---|---|
send_message | Put information in the target mailbox; do not necessarily wake it. |
followup_task | Send work with trigger semantics; may start another turn if idle. |
wait_agent | Wait for a mailbox/status update from a child thread. |
interrupt_agent | Cancel a child’s active turn. |
list_agents | Inspect the current tree of known agents. |
That table is the difference between communication and function calls. Function calls return. Agents communicate over time.
9. Completion watchers: results need to return to the parent’s world
A side agent is only useful if its result can re-enter the parent’s reasoning loop.
That is the job of completion watching and mailbox updates. When schema_audit finishes, the root should receive a structured update it can act on: contract risks, evidence, uncertain points, and perhaps a recommended follow-up. When perf_probe finishes, the root should receive benchmark output and interpretation. The result is not merely printed somewhere; it becomes a message the parent can observe and incorporate.
This is why the tree model matters. The parent knows which child produced which result, what role it had, and how to ask for clarification. If perf_probe reports a p95 regression, root can send a targeted follow-up instead of starting a new global search through conversation text.
10. Resume: the tree has to grow back
Persistence is the final test for whether something is really a subagent or just a background task.
If the app restarts while the checkout migration is in progress, the root thread should not forget that schema_audit, test_worker, and perf_probe existed. The runtime needs to restore descendant agents from persisted thread-spawn edges and rebuild the registry view.
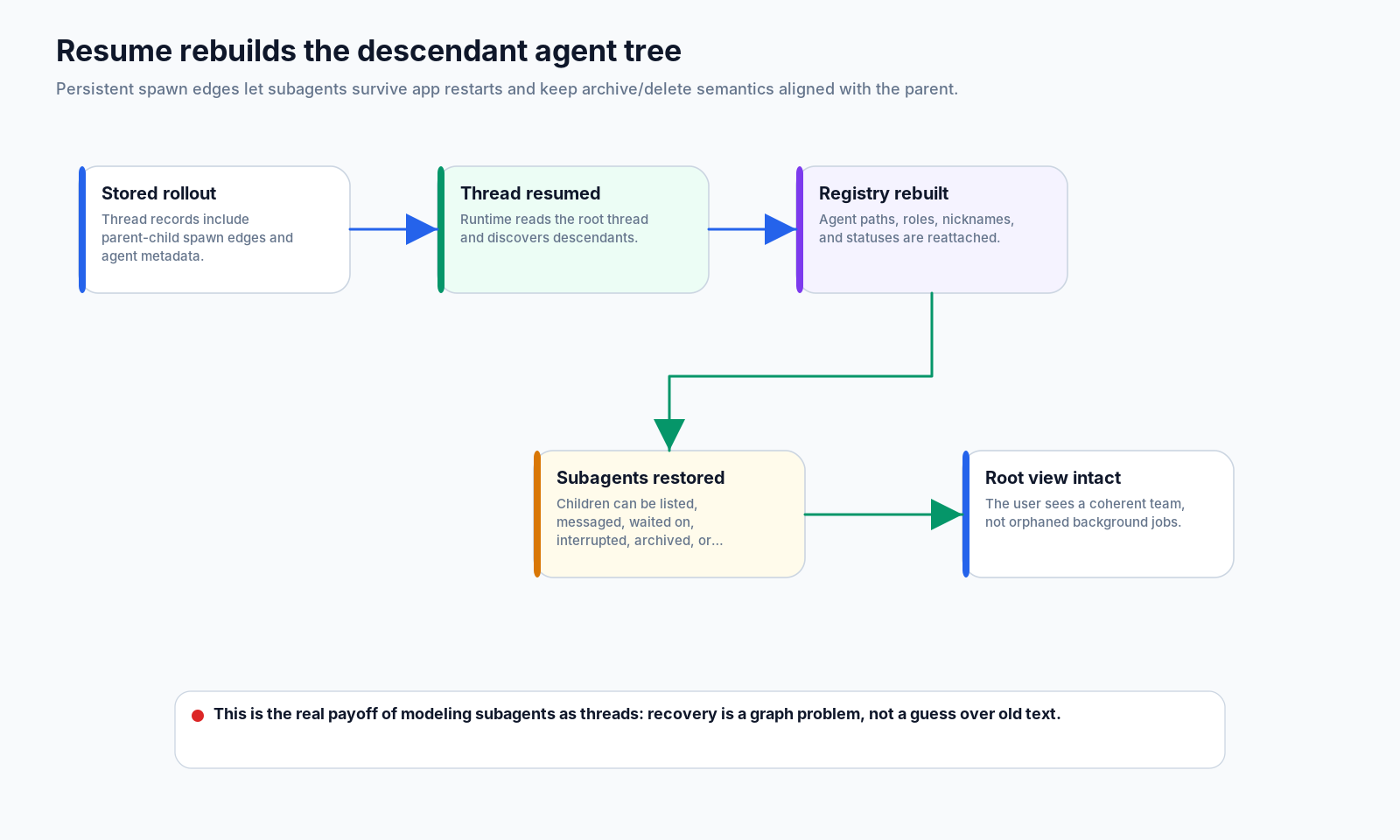
That gives several lifecycle benefits:
list_agents still shows the team
wait_agent can still refer to a restored child
archive/delete can apply to the whole descendant tree
status can be reconstructed from thread state
messages can continue to use stable agent pathsIf subagents were only temporary futures, recovery would be guesswork. With a thread tree, recovery becomes a graph operation.
11. What this design says about Codex
Codex’s multi-agent design is opinionated. It treats collaboration as runtime structure, not just model prompting.
That structure has a cost. It requires registries, paths, fork modes, mailboxes, spawn edges, status events, and resume logic. But it also gives the system properties that one-off parallel calls do not have:
| Property | Why it matters |
|---|---|
| Identity | A child can be addressed, listed, waited on, and interrupted. |
| Context boundary | A side task can work with a curated view instead of the entire parent rollout. |
| Runtime inheritance | Children run in a compatible execution world. |
| Communication | Agents can exchange messages over time, not just return strings. |
| Capacity control | Recursive spawning has a hard limit. |
| Persistence | Descendants can be restored with the session tree. |
The main lesson is sharp:
Multi-agent support is not primarily about parallelism. It is about turning delegation into recoverable, bounded, addressable work.
That is why spawn_agent should not be read as “call another model.” It should be read as “materialize a child thread under the current root session tree.”
12. Source-reading checklist
When reading Codex’s subagent code, use these questions:
Which AgentControl instance owns this session tree?
How does AgentRegistry enforce capacity?
What agent path will this child receive?
What role, nickname, model, and reasoning settings are applied?
What parent history is forked, and what is intentionally left out?
Which runtime policy is inherited from the parent?
How does the initial message enter the child thread?
How does the parent receive completion or mailbox updates?
What happens if the child is interrupted?
How is the descendant tree restored on resume?If you can answer those questions, the multi-agent system stops looking like a bag of tools. It becomes a tree-shaped runtime for collaboration.
Source map
Useful files and areas to read after this post:
codex-rs/core/src/agent/control.rsforAgentControland the shared control-plane model.codex-rs/core/src/agent/registry.rsfor capacity limits, identity, metadata, and nickname handling.codex-rs/core/src/tools/handlers/multi_agents_v2/spawn.rsforspawn_agentand child-thread materialization.codex-rs/core/src/tools/handlers/multi_agents_v2/message_tool.rsfor messaging, follow-up, waiting, and interruption semantics.- Thread persistence and app-server lifecycle code for archive, delete, resume, and descendant restoration.