Crafting Interpreters (I): When Source Text Becomes Structure
How characters acquire boundaries, hierarchy, and evaluation order
TLDR: Source text does not contain a hidden tree. A scanner first turns characters into typed tokens, then the parser uses grammar, precedence, and associativity to choose one AST that later phases can evaluate and diagnose without rediscovering the structure.
print 1 - 2 * 3 < 4 == false;This line looks settled to a human reader. We already know that 2 * 3 belongs together, that subtraction happens before comparison, and that equality comes last. The implementation knows none of that when the file arrives. It receives a flat character sequence. Multiplication has no privileged position. There is no tree, no parent-child relationship, and no runtime order hiding between the bytes.
So ask one concrete question:
Which phase first places
2 * 3under the right side of subtraction?
The complete journey is compact enough to write in one line:
characters → tokens → AST → evaluationBut each arrow resolves a different kind of uncertainty. The scanner decides where meaningful pieces begin and end. The parser decides how those pieces nest. The AST preserves that decision so later phases do not need to rediscover it. Evaluation comes only after all of that.
Technical promise: by the end of this article, you will be able to trace the opening line from a character buffer to tokens and then to an AST, and explain exactly where maximal munch, lookahead, precedence, associativity, recursive descent, and panic-mode recovery enter the trace.
The series will eventually keep asking, “Where is n now?” This first episode stops one step earlier: before a variable can be bound, stored, captured, or retained, the implementation must first learn how source text becomes structure.
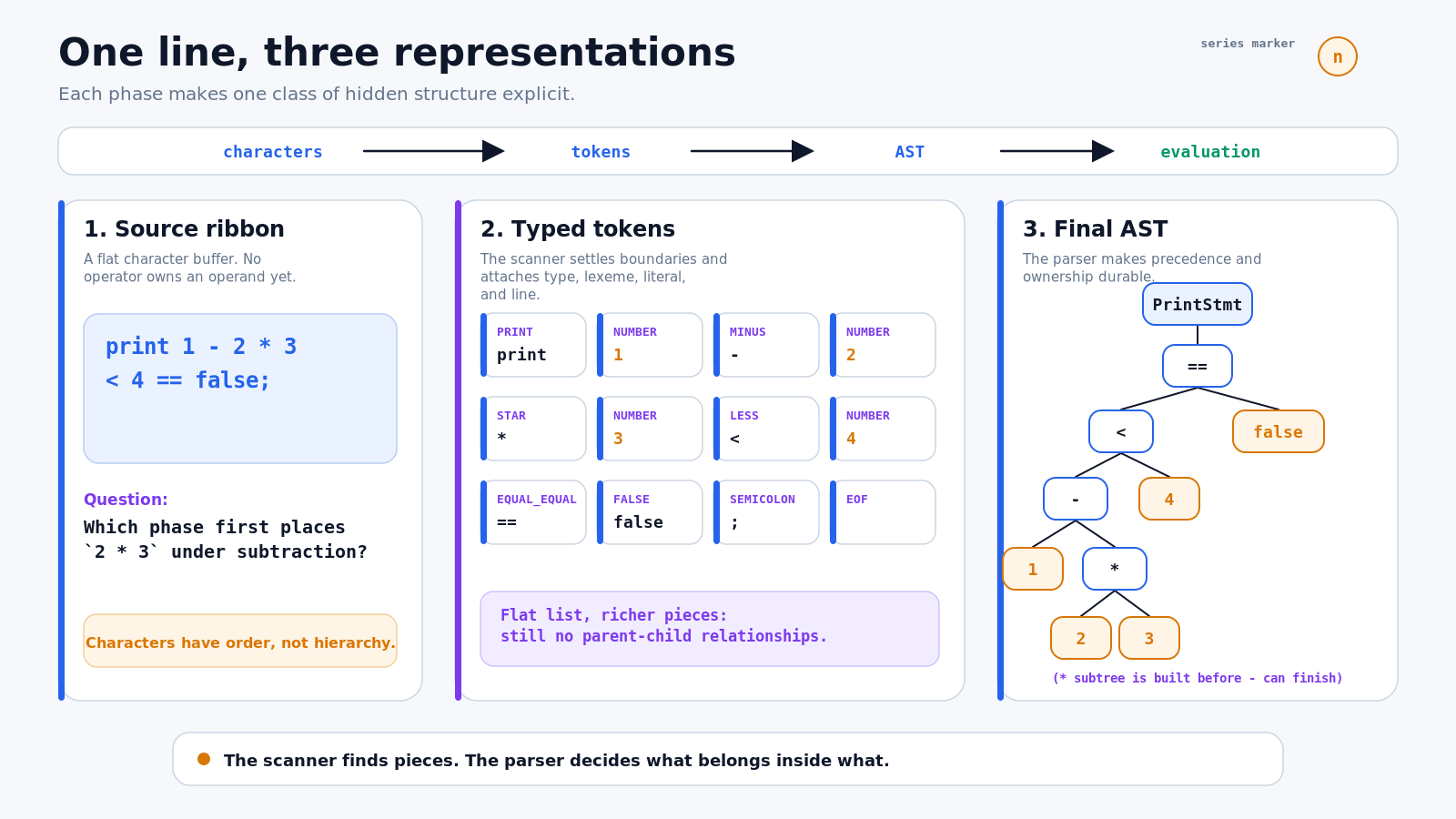
Figure 1. The scanner exposes token boundaries; the parser exposes ownership and evaluation order.
1. The program arrives flat
Freeze jlox just before the scanner consumes the first character. The entire source file is one Java String. Three integers are enough to describe the scanner’s position:
startpoints to the first character of the lexeme currently being scanned;currentpoints just after the characters already consumed;linerecords the current source line for diagnostics.
Those fields are deliberately modest. The scanner is not trying to understand an expression. It is running a repeated transaction over a linear input:
mark the lexeme start
→ consume enough characters
→ classify the lexeme
→ emit one tokenThe outer loop makes that transaction visible:
List<Token> scanTokens() {
while (!isAtEnd()) {
start = current;
scanToken();
}
tokens.add(new Token(EOF, "", null, line));
return tokens;
}At the opening line’s first iteration, start == current == 0. scanToken() calls advance() and consumes p. A p could begin an identifier, so the scanner keeps advancing while the next character is alphanumeric or _. It consumes r, i, n, and t, then stops before the space.
Only now does the source slice have a boundary:
source[start..current) = "print"The scanner looks up that completed lexeme in its keyword table and finds a reserved word. It emits a token whose type is PRINT and whose lexeme is print. The space is handled in the next iteration: start moves to the space, advance() consumes it, and the scanner emits nothing because whitespace is not meaningful to Lox’s parser.
This is the first structural gain. Five characters have become one typed unit. The scanner has not learned that print contains an expression, and it has not learned anything about multiplication. It has only established a boundary and a name for the thing inside it.
The scanner can now name pieces of the line. Its next problem is that some boundaries cannot be chosen from the current character alone.
2. Boundaries carry language policy
A scanner can look like a glorified switch, but the edge cases reveal that it is enforcing language design. Consider three small tests:
or
orchid
! =
!=
123.45
123.The first pair creates the need for maximal munch. If the scanner emitted the keyword or as soon as it saw the first two letters of orchid, the rest of the name would be broken into unrelated pieces. Lox instead follows a longest-match rule: when more than one lexical rule could match, the rule that consumes the most characters wins.
That means keyword recognition happens after identifier scanning, not during it. The scanner first consumes the entire identifier-shaped run orchid. It then asks the keyword table whether that completed lexeme is reserved. or is found and becomes an OR token. orchid is not found and becomes an IDENTIFIER token. Boundary first, classification second.
The second pair introduces one-character lookahead. After consuming !, the scanner cannot yet know whether the token is BANG or BANG_EQUAL. It conditionally consumes the next character only when that character is =:
private boolean match(char expected) {
if (isAtEnd()) return false;
if (source.charAt(current) != expected) return false;
current++;
return true;
}
private char peekNext() {
if (current + 1 >= source.length()) return '\0';
return source.charAt(current + 1);
}For !=, match('=') succeeds and both characters form one token. For ! =, the next character is a space, so the scanner emits BANG; a later iteration emits EQUAL. Whitespace is not merely decorative here. It prevents the two characters from sharing a lexeme.
The number test needs two-character lookahead. Once the scanner has consumed 123, it sees a dot. The dot belongs to the number only when a digit follows it. The condition is effectively:
peek() == '.' && isDigit(peekNext())That accepts 123.45 as one NUMBER token with numeric literal value 123.45. It rejects the dot as part of 123. because there is no following digit. The scanner emits NUMBER("123"), then starts a new iteration and emits DOT("."). This detail matters: under Lox’s rules, a trailing dot does not silently become part of a floating-point literal.
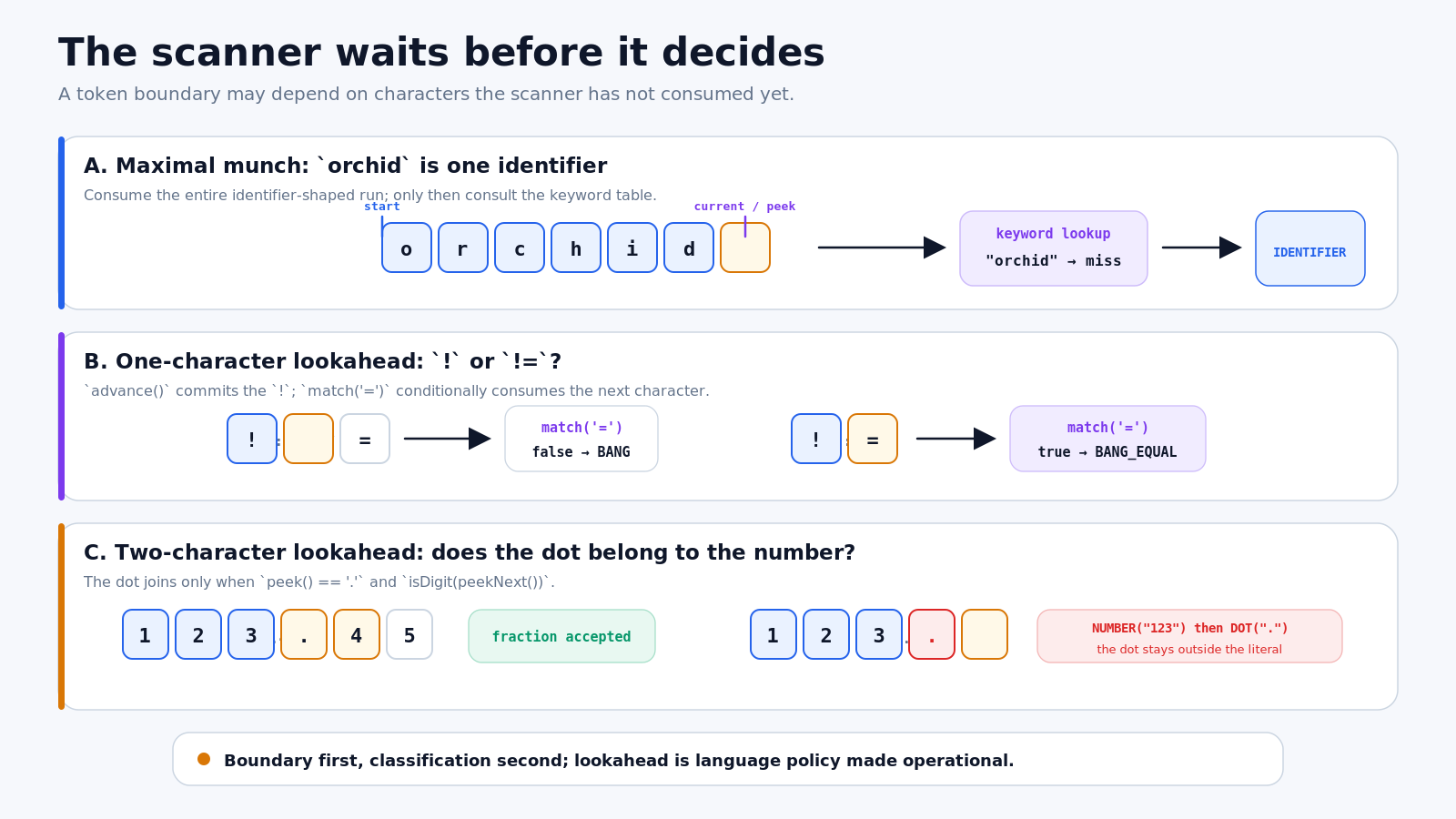
Figure 2. The scanner sometimes has to wait: maximal munch finishes a candidate lexeme, while lookahead tests what may join it.
Each emitted token carries four kinds of information:
- Type —
NUMBER,STAR,PRINT, and so on, so later phases do not repeatedly compare strings. - Lexeme — the exact source slice, useful for diagnostics and operator spelling.
- Literal value — a converted runtime-friendly payload for number and string literals. Boolean and
niltokens are keywords; the parser creates their literal nodes later. - Source location —
jloxkeeps the line number; production tools often retain offsets, columns, and lengths too.
The token object is also a phase contract. Once the scanner emits NUMBER, the parser no longer needs to know whether the characters were found by a digit loop, a regular expression, or a generated finite-state machine. It can consume a uniform stream. Conversely, the scanner does not need to know whether that number will become the left operand of subtraction, an argument to a function, or a field initializer. Good phase boundaries discard responsibilities as deliberately as they add information.
Source location is part of that contract, not metadata pasted on later. By the time the parser discovers a missing parenthesis in jlox, the scanner has already tokenized the entire file and reached EOF. Carrying location on tokens lets the parser point back to the relevant lexeme without reverse-engineering offsets from the tree. Structure and diagnostics are being prepared together.
Only after these examples is the theory useful. Lox’s lexical rules form a regular language: a finite-state process with a small amount of lookahead can recognize its lexemes. That is why a hand-written scanner can move monotonically through the source, never needing to build a tree or remember arbitrarily deep nesting. Parentheses may nest without limit, but recognizing the individual ( and ) tokens does not require the scanner to match the pairs. Pairing them is the parser’s job.
By the time scanning finishes, the opening line has become a flat token list:
PRINT NUMBER(1) MINUS NUMBER(2) STAR NUMBER(3)
LESS NUMBER(4) EQUAL_EQUAL FALSE SEMICOLON EOFThe boundaries are settled. The list is richer than the source string, but it is still a list. Nothing in it says that STAR owns the two adjacent number tokens.
Tokenization has removed one uncertainty and exposed the next: the same flat list can still support more than one tree.
3. One token list leaves two programs on the table
Strip the opening line down to its arithmetic center:
1 - 2 * 3The scanner produces the same five meaningful tokens no matter how the expression should be evaluated:
NUMBER(1) MINUS NUMBER(2) STAR NUMBER(3)Now draw two possible trees.
In the first, subtraction is the child of multiplication:
*
/ \
- 3
/ \
1 2That tree means (1 - 2) * 3, which evaluates to -3.
In the second, multiplication is the right child of subtraction:
-
/ \
1 *
/ \
2 3That tree means 1 - (2 * 3), which evaluates to -5.
Both trees consume every token exactly once. Both are structurally plausible if all we know is “a binary expression has a left operand, an operator, and a right operand.” The difference is not in the vocabulary. It is in ownership.
This is grammar ambiguity in its most useful form: one input admits multiple valid structural interpretations, and those structures have different behavior. The parser’s job is therefore larger than checking whether the tokens are legal. It must choose the one tree that expresses Lox’s precedence and associativity rules.
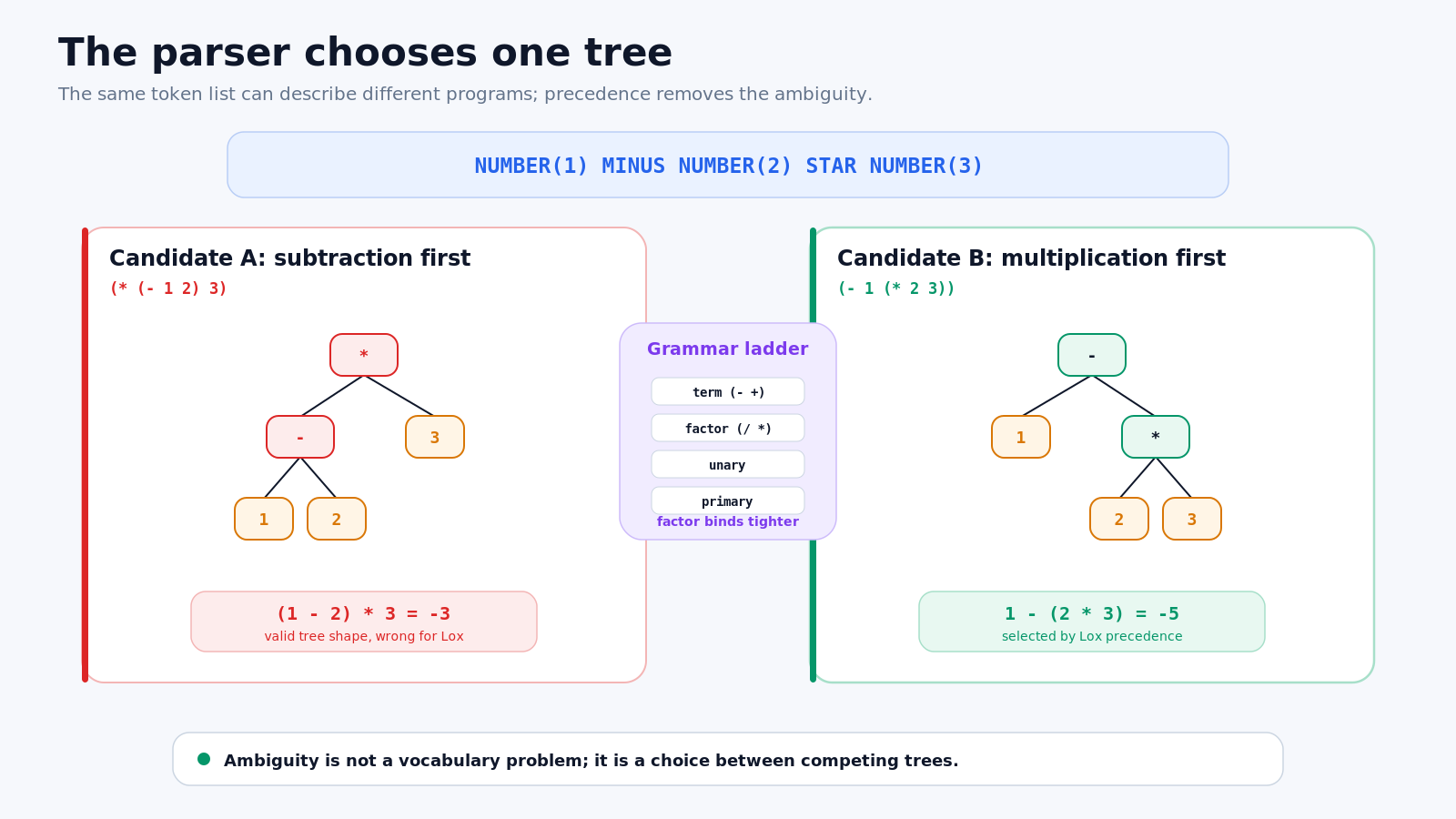
Figure 3. Ambiguity becomes concrete when two trees produce different results. Lox selects multiplication before subtraction.
Precedence decides which kind of operator binds more tightly when different operators appear together. * has higher precedence than -, so the multiplication subtree must form inside the subtraction expression.
Associativity decides how repeated operators at the same precedence level group. Lox’s arithmetic, comparison, and equality operators are left-associative, so 10 - 3 - 2 means (10 - 3) - 2. Unary operators are right-associative, so !!false nests from the right.
The scanner cannot make either decision. It does not know whether - is waiting for a complete factor on its right, and it should not know. Letting tokenization depend on grammatical context would entangle two phases that have cleanly different responsibilities.
The parser needs a grammar whose own shape makes the intended tree easier to build than the wrong one.
4. Grammar turns precedence into tree shape
Lox removes the ambiguity by stratifying expressions into a ladder. From lowest precedence to highest, the relevant rules are:
expression → equality ;
equality → comparison ( ( "!=" | "==" ) comparison )* ;
comparison → term ( ( ">" | ">=" | "<" | "<=" ) term )* ;
term → factor ( ( "-" | "+" ) factor )* ;
factor → unary ( ( "/" | "*" ) unary )* ;
unary → ( "!" | "-" ) unary | primary ;
primary → NUMBER | STRING | "true" | "false" | "nil"
| "(" expression ")" ;The crucial relationship is that a lower-precedence rule asks the next tighter rule to parse each operand. term() does not parse arbitrary expressions around -; it asks factor() for both sides. factor() in turn asks unary(). A multiplication therefore has a chance to finish before control returns to the subtraction layer.
Recursive descent translates that grammar almost literally into methods. Term and factor share the same shape:
private Expr term() {
Expr expr = factor();
while (match(MINUS, PLUS)) {
Token operator = previous();
Expr right = factor();
expr = new Expr.Binary(expr, operator, right);
}
return expr;
}
private Expr factor() {
Expr expr = unary();
while (match(SLASH, STAR)) {
Token operator = previous();
Expr right = unary();
expr = new Expr.Binary(expr, operator, right);
}
return expr;
}The loop form is also a parsing constraint, not just a coding preference. A mathematically natural rule for multiplication might be factor → factor ("/" | "*") unary | unary. That rule is left-recursive: the first thing factor() would do is call factor() again without consuming a token. A hand-written recursive-descent parser would recurse forever. Rewriting the rule as one unary followed by zero or more operator-and-operand pairs accepts the same expression language while guaranteeing progress. The parser consumes a real operand before it can repeat.
This is a recurring implementation lesson: grammars describe languages, but not every equivalent grammar is equally usable by every parsing strategy. We are not changing Lox’s semantics when we remove left recursion. We are choosing a representation of the grammar that maps cleanly onto the control flow of recursive descent.
The loops do two jobs. First, they allow chains such as 1 * 2 / 3. Second, because each new Binary node uses the tree accumulated in expr as its left operand, the chain becomes left-associative:
1 - 2 - 3
first: Binary(1, -, 2)
then: Binary(previousTree, -, 3)
result: ((1 - 2) - 3)Now trace only the calls needed for 1 - 2 * 3.
expression() calls equality(), which calls comparison(), which calls term(). The first factor() under term() parses the primary literal 1 and returns it. term() sees -, so it consumes the operator and asks factor() for the right operand.
That second factor() parses 2, then sees *. Because * belongs to the factor layer, factor() consumes it, parses 3, and immediately constructs:
Binary(Literal(2), STAR, Literal(3))Only after that subtree is complete does factor() return to term(). The subtraction layer now receives the entire multiplication tree as its right operand and constructs:
Binary(Literal(1), MINUS, Binary(2, STAR, 3))That is the decisive moment. The scanner never “gave multiplication priority.” The grammar did, through the call relationship between term() and factor(), and the parser made the choice concrete by allocating the multiplication node first.
Continue the same trace through the rest of the opening expression:
PrintStmt
└── Binary ==
├── Binary <
│ ├── Binary -
│ │ ├── Literal 1
│ │ └── Binary *
│ │ ├── Literal 2
│ │ └── Literal 3
│ └── Literal 4
└── Literal falseThe multiplication sits deepest. Subtraction contains it. Comparison contains the subtraction. Equality becomes the outermost expression. print is the statement shell around that expression; the book introduces full statement parsing shortly after the expression parser, but it does not change the precedence story inside the shell.
Recursive descent is often introduced as a parsing technique. It is more useful to see it as a state trace. Each active grammar rule is a Java call frame. Descending means asking a tighter rule to settle a smaller question. Returning means handing a completed subtree back to the caller. The runtime call stack temporarily holds “where the parser is”; the AST records the durable result.
The parser has now selected a tree. Later phases need a stable representation of that choice, not a replay of the parser’s call stack.
5. The AST becomes the handoff point
The parser’s call stack vanishes when parsing returns. The chosen structure must not vanish with it. That durable representation is the abstract syntax tree.
“Abstract” matters. A concrete parse tree can preserve every grammar production and punctuation token. An AST keeps the distinctions later phases need and drops much of the scaffolding used to recognize them. For the expression subset in this episode, four node kinds carry most of the story:
Literalstores an atomic value such as1,"hello", orfalse.Unarystores an operator token and one operand.Binarystores a left expression, an operator token, and a right expression.Groupingstores the expression inside explicit parentheses.
A binary node is almost aggressively simple:
static class Binary extends Expr {
Binary(Expr left, Token operator, Expr right) {
this.left = left;
this.operator = operator;
this.right = right;
}
final Expr left;
final Token operator;
final Expr right;
}The fields reveal what the parser decided. left and right are no longer adjacent tokens in a list; they are child references. The operator token remains because later phases need its type to choose behavior and its source location to report errors.
Notice what the node does not store. It does not retain the scanner’s start and current cursors. It does not store the precedence number that justified the shape. It does not keep a pointer back to the parser method that allocated it. Those were construction-time concerns. Once the tree exists, the nesting itself is the proof. This selective forgetting is why an AST is a useful intermediate representation rather than a serialized parser trace. It preserves semantic structure while letting temporary implementation state disappear.
That distinction becomes valuable when tools transform the tree. A formatter may care about original tokens and comments, so it often keeps a richer concrete syntax tree. An interpreter wants the opposite: a compact structure where irrelevant punctuation and parser bookkeeping do not obstruct evaluation. “The right tree” depends on the consumer, but every tree should make its retained invariants explicit.
Parentheses illustrate what the AST keeps and discards. The individual ( and ) tokens do not survive as leaf nodes. Their structural effect does. jlox represents that effect with a Grouping node containing the inner expression. Other implementations may return the inner node directly once grouping has forced the desired shape. Either way, punctuation has done its job: it changed ownership without becoming a runtime value.
The AST also solves an architectural ownership problem. The parser creates the tree, but the parser is not the only code that needs it. A debug printer wants to render the nesting. The interpreter wants to evaluate nodes. A resolver introduced later wants to walk variable expressions and record lexical distance. In a statically typed language, a type checker would want another traversal.
Stuffing all of those operations into the node classes would mix unrelated phases. jlox instead uses the Visitor pattern. Each node knows how to dispatch to the right visit method, while each operation lives in its own class. The tree classes remain a typed data model; the visitors provide parser-independent behavior.
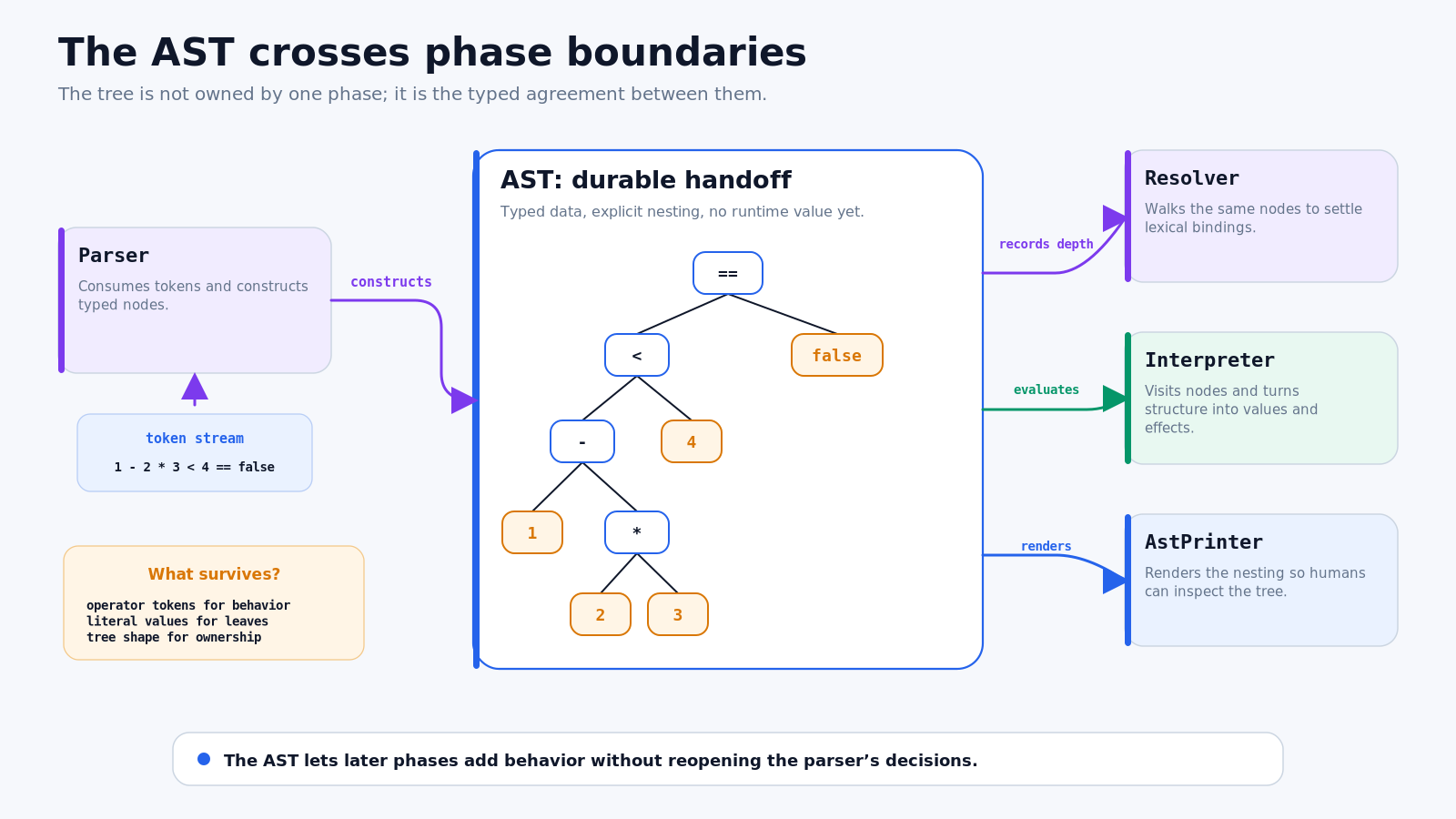
Figure 4. The AST is a durable agreement: the parser fixes structure once, and later passes consume that structure for different purposes.
This is the practical value of the handoff. The interpreter does not need to ask whether 2 * 3 should bind before subtraction. It receives a Binary(MINUS) node whose right child is already a Binary(STAR) node. The resolver does not need to reparse source slices. The printer does not need to infer nesting from operator precedence. One phase paid the ambiguity cost; all later phases reuse the result.
The Visitor pattern is sometimes explained as a catalog item. Here the causal reason is clearer: syntax node kinds are relatively stable during a pass, while operations over them keep accumulating. We want to add a new traversal without reopening every node class. Visitor turns “what operation are we running?” into a separate axis from “what kind of node is this?”
This clean handoff assumes the parser can return to a known state. Real source code is often incomplete, malformed, or half-typed.
6. A useful parser survives bad input
Consider a missing right parenthesis followed by a valid statement:
print (1 + 2;
print 99;While parsing the grouping expression, the parser successfully reads 1 + 2. It then calls consume(RIGHT_PAREN, ...). The next token is a semicolon, so the expected grammar production cannot complete.
A weak parser has two bad options. It can crash and expose an implementation exception, or it can keep calling grammar methods in a corrupted state and produce a cascade of misleading errors. jlox chooses panic-mode recovery: report one precise error, abandon the damaged production, move to a likely boundary, and resume from there.
The local control-flow mechanism is a tiny ParseError exception. Throwing it unwinds the recursive-descent call frames that represented the half-finished primary(), unary(), factor(), term(), and outer statement parse. Catching it at a statement or declaration boundary restores the parser to a rule from which a fresh statement can begin.
The token stream still needs to be realigned. Synchronization discards input until it sees evidence of a boundary:
private void synchronize() {
advance();
while (!isAtEnd()) {
if (previous().type == SEMICOLON) return;
switch (peek().type) {
case CLASS: case FUN: case VAR: case FOR:
case IF: case WHILE: case PRINT: case RETURN:
return;
}
advance();
}
}The method is intentionally heuristic. A semicolon probably ended the bad statement. A leading keyword such as print, var, or if probably starts the next one. “Probably” is enough because recovery is already best effort: the parser has reported the original error at the token where its expectation failed.
For the example, the parser has consumed the malformed statement through 2 and is looking at ; when it reports “Expect ’)’ after expression.” Recovery consumes that semicolon, recognizes the boundary, and leaves the second print ready for normal parsing. A single run can therefore diagnose the first statement without sacrificing the rest of the file.
Chapter 6 introduces the recovery machinery while the parser still accepts only one expression, so there is not yet much to resume. Once statements are parsed as a sequence, the same mechanism becomes visibly useful: catch at the declaration boundary, synchronize the tokens, and continue.
Two distinctions keep the design honest.
First, panic-mode recovery is parser behavior. An unexpected character such as @ is a scanner error. The scanner consumes it, reports it, and continues scanning; it does not throw ParseError or synchronize on statement keywords.
Second, continuing to parse does not mean executing damaged code. Reporting a syntax error sets hadError. The front end may continue gathering diagnostics, but the interpreter refuses to run the resulting program. Recovery improves feedback; it does not pretend an invalid tree is safe.
A good recovery strategy is not one that reconstructs the user’s intention perfectly. That would require solving a much harder problem. It is one that bounds the damage: one malformed region should not destroy the entire parse session or manufacture dozens of secondary complaints.
Even imperfect input now produces bounded errors instead of tearing down the whole front end. We can return to the line that started the story.
7. The line has become a program
Replay the opening line in three representations.
Source text
print 1 - 2 * 3 < 4 == false;It preserves spelling and character order, but not boundaries or hierarchy.
Token sequence
PRINT NUMBER(1) MINUS NUMBER(2) STAR NUMBER(3)
LESS NUMBER(4) EQUAL_EQUAL FALSE SEMICOLON EOFIt preserves boundaries, token kinds, literal payloads, and locations, but remains flat.
AST
PrintStmt(
Binary(
Binary(
Binary(1, -, Binary(2, *, 3)),
<,
4),
==,
false))It preserves the parser’s chosen ownership. The exact opening question now has an exact answer:
The
factor()grammar layer constructsBinary(2, STAR, 3)beforeterm()can complete the subtraction node.
That moment first places 2 * 3 under the right side of subtraction. Everything before it prepared the evidence. The scanner ensured 2, *, and 3 were separate, correctly typed tokens. The precedence grammar constrained the legal nesting. Recursive descent turned the rule relationship into calls. The AST retained the result after those calls returned.
There is still no printed false and no runtime effect. The AST contains evaluation order, but it has not evaluated anything. Literal(2) is syntax that can produce the value 2; it is not yet a value flowing through the interpreter. The line is executable structure, suspended immediately before execution.
Source map
The book remains the primary source for this episode:
- Chapter 2, “A Map of the Territory” — the front-end path from source code through scanning and parsing.
- Chapter 4, “Scanning” —
Scanner.java,Token.java,TokenType.java,scanTokens(),match(),peek(),peekNext(), maximal munch, and literal conversion. - Chapter 5, “Representing Code” —
Expr.java,GenerateAst.java,AstPrinter.java, AST node families, and the Visitor pattern. - Chapter 6, “Parsing Expressions” — ambiguity, the precedence ladder, recursive descent,
ParseError, panic mode, and synchronization.
Useful implementation entry points:
java/com/craftinginterpreters/lox/Scanner.javajava/com/craftinginterpreters/lox/Parser.javajava/com/craftinginterpreters/lox/Expr.javajava/com/craftinginterpreters/lox/AstPrinter.java
The presentation rhythm—start with a concrete failure of the shallow mental model, replace it with a sharper one, then follow exact implementation state—was inspired by Luna Shi’s source-dive series. The argument, examples, diagrams, and prose here are original to this episode.
Bridge to Episode II
The tree is ready, but inert. Episode II begins when the interpreter visits the first leaf, turns Literal(1) from syntax into a runtime value, and starts propagating values upward through the structure the parser just built.