Self-Harness:会改进自己的 harness
Self-Harness:会改进自己的 harness
TLDR:这篇文章的持久贡献不是无限制的自我改进,而是证据驱动的 harness 版本控制:固定模型和评估器,挖掘失败轨迹,对模型周围的 harness 提出有限编辑,并只提升能通过回归测试的改动。
核心判断
这是一篇很强的系统论文,但它最好的想法并不像标题所暗示的那么浪漫。真正的价值并不是开放式意义上的“自我完善的智能体”。真正的价值在于它将智能体工具视为显式的、可编辑的、版本化的、可测试的软件对象。
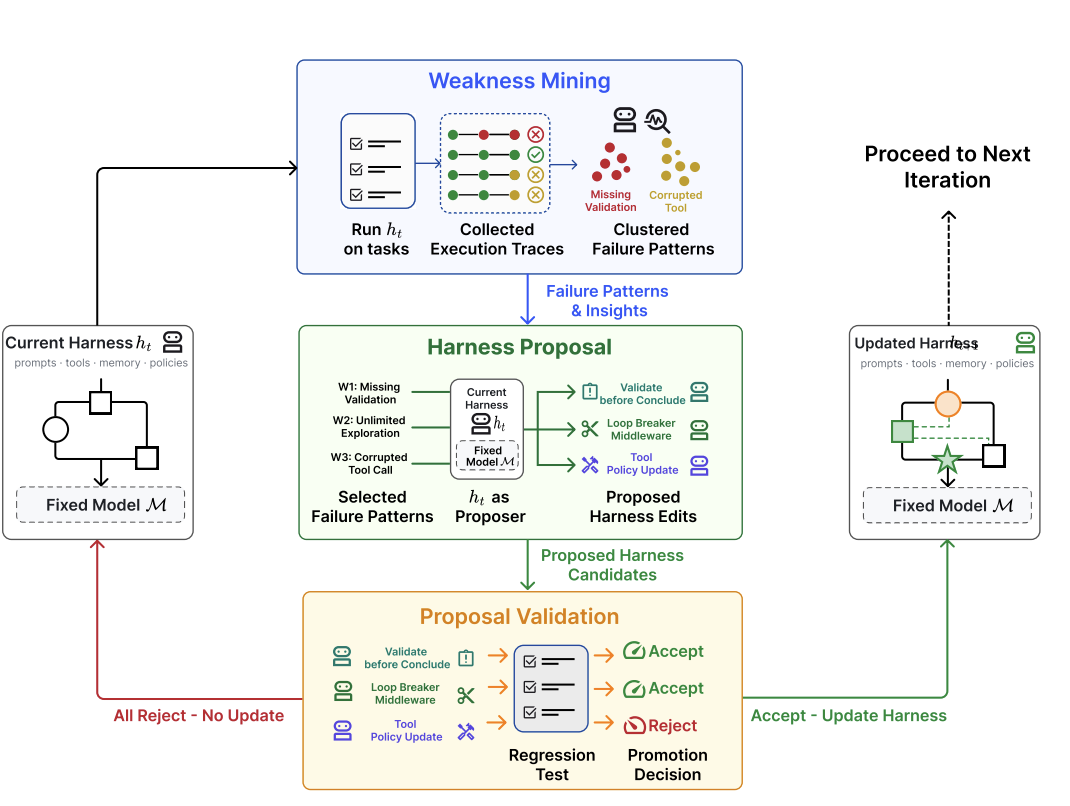
这篇论文的中心举措简单而重要:保持基础模型固定,评估器固定,并让模型根据自己的失败执行轨迹,对周围的 harness 提出有边界的修改。这是一个干净的实验视角,可以把“模型变强了”和“模型周围的 harness 变好了”分开看。 (arXiv)
最危险的问题是:论文里的 holdout split 并不是最终未触及的测试集。holdout 轨迹不会给提议者看,但 holdout 分数会被 promotion gate 使用。因此,结果证明的是带验证门控的 harness 调整,还不是广泛泛化或开放式自我改进。 (arXiv)
1. 动机:痛点是真实的,但“自我创造”的说法太重
这篇文章从一个非常现实的智能体工程问题开始:LLM 智能体不仅仅由基础模型决定。它们还被模型周围的工具塑形:系统提示、工具、运行时机制、验证规则、编排逻辑和恢复策略。同一个模型放在不同 harness 里,表现可能完全不同;适合一个模型的 harness,也未必适合另一个模型。 (arXiv)
这个框架是对的。在生产智能体系统中,许多故障并不是“模型不会推理”。它们是 harness 失败:智能体忘记创建必要产物,不断重试同一个坏命令,无法验证最终状态,在 shell 调用之间丢失环境变化,或者没有弄清验证器到底检查什么就报告成功。
作者的判断也对:靠人工调 harness 很难扩展。新模型有不同的工具使用习惯、错误模式、上下文敏感性和恢复行为。如果每个新模型都要手动调一套 harness,智能体工程就会变成跑步机。 (arXiv)
但论文里关于“自我创造”的说法比实际机制更重。self-harness 并不是一个可以自由重写自己的模型。它是一个在精心设计的改进循环内运行的固定模型,有结构化的轨迹挖掘、声明式可编辑表面、回归测试和外部验收规则。这仍然很有价值,只是它更接近严格的自动化 harness 维护,而不是递归自我改进。
2. 贡献:核心是把 harness 当成有状态工程对象
如果我只能保留这篇文章中的一项贡献,我会保留这一点:harness 应被视为有状态的工程对象。
这篇论文把工具定义为围绕固定语言模型的非参数 harness:指令、工具、内存、状态管理机制,以及模型观察任务、调用工具、检查产物和生成输出时遵循的协议。模型权重不会改变。变化的只有一系列 harness 版本。 (arXiv)
这就是彻底的概念转变。论文不是把 prompt engineering 当成一堆技巧,而是在说:定义可编辑表面,收集行为证据,提出有边界的编辑,测试这些编辑,然后把通过测试的编辑提升到下一个 harness 版本中。这也让它和普通反思、基于记忆的自我提升拉开了距离。类似 Reflexion 的方法通常存储反馈、记忆或响应策略。Self-Harness 改变的是未来智能体行为所依赖的声明式框架。它也不同于外部智能体设计搜索,因为它用同一个目标模型作为提议者,而不是依赖更强的外部优化器。 (arXiv)
这篇论文更准确的名字可能是:证据驱动的 harness 版本控制。“self-harness”更醒目,但更深的想法不是智能体突然变得自主,而是 harness 编辑变成了可验证的状态转换。
3. 方法:关键的见解是将故障转化为受限的软件补丁
这个方法分为三个阶段:弱点挖掘、harness 提案和提案验证。这种结构是这篇文章最有力的工程贡献。 (arXiv)
第一,弱点挖掘在当前工具下运行固定模型,并收集带有验证者结果的执行跟踪。失败的运行不会被视为孤立的轶事。它们由基于验证者的失败签名聚集:验证者拒绝了什么,智能体端的哪些行为导致了拒绝,以及似乎涉及哪些可重用机制。这很重要,因为两个任务都可能因超时而失败,同时需要非常不同的 harness 修复。 (arXiv)
第二,Harness Proposal 要求同一个模型生成几个不同的、最小的候选编辑。提议者可以看到当前 harness、可编辑表面、结构化故障模式、应保留的通过行为,以及之前尝试编辑的摘要。每个提案都必须针对具体故障机制,并把它映射到特定的可编辑 harness 表面。 (arXiv)
第三,提案验证将每个候选编辑视为新的 harness 变体。它评估当前 harness 和候选 harness 在训练划分与 holdout 划分上的表现。只有当候选编辑至少改善一个划分,并且不让另一个划分退化时,才会被接受。这是这篇论文比“让模型重写自己的提示”demo 更严肃的关键原因。提议者讲得有道理还不够,编辑必须通过回归测试。 (arXiv)
这个方法真正强的地方,是把模糊的智能体建议转换成可执行的 harness 修改。“小心一点”是不够的。“尽早创建所需的输出产物”、“停止重复执行同一个失败命令”、“解决问题前先验证依赖导入”或“工具调用过多后强制重定向”,才是 harness 级干预。
但这种优势也暴露了依赖性:Self-Harness 需要好的评估器、有用的轨迹、稳定的验证器、精心选择的可编辑表面,以及能把失败转换成可复用策略的基准。没有这些基础设施,“自我完善”很容易退回到看似合理的 prompt 重写。
4. 结果:最有力的证据是模型相关的编辑多样性,而不仅仅是通过率增益
实验跑在 Terminal-Bench-2.0 上,这是一个带确定性验证器的容器化终端任务基准。作者使用固定的 64 例子集,排除了依赖不稳定外部 Web 资源或多模态输入的任务。他们测试了三种模型后端:MiniMax M2.5、Qwen3.5-35B-A3B 和 GLM-5。比较时,模型、解码设置、预算、工具、基准环境和评估器都保持固定;唯一允许改变的是 harness。 (arXiv)
这些数字显然是积极的。在训练任务上,MiniMax M2.5 从 40.5% 提高到 61.9%,Qwen3.5 从 23.8% 提高到 38.1%,GLM-5 从 42.9% 提高到 57.1%。在 holdout 任务上,相应增益是 43.0% 到 50.0%、15.1% 到 36.0%、47.7% 到 57.0%。 (arXiv)
这些收益有意义,因为论文控制住了主要混淆项:基础模型没有变,改进来自 harness。这正是智能体系统论文应该经常提供的证据。
但最好的证据不是条形图。最好的证据是,不同模型保留的编辑是不同的。
对于 MiniMax M2.5,被接受的编辑会促使智能体更早创建所需产物、使用正确的内容标签,并在长时间工具循环后重定向。evolved run 从 42.2% 提高到 53.9%。 (arXiv)
对于 Qwen3.5,保留下来的编辑强调依赖预检查、缺失产物恢复、重试规则,以及由工具错误触发的中间件。evolved run 从 20.3% 提高到 36.7%。 (arXiv)
对于 GLM-5,编辑重点是跨 shell 会话持久化环境变化,以及更快地从探索转向实现和测试。harness 效率从 46.1% 提高到 57.0%。 (arXiv)
模型特异性是这里最重要的部分。如果最终结果只是“添加一个更长的通用提示,告诉每个模型多做验证”,这篇论文会弱很多。相反,编辑对应的是不同的观察到的故障模式:MiniMax 获得产物和循环规则,Qwen 获得工具错误恢复和重试控制,GLM 获得环境持久性和实现压力。 (arXiv)
我仍然想看到更强的廉价基线。例如:采用人工编写的通用清单 - 尽早创建产物,避免重复失败命令,验证最终文件,保留 shell 状态 - 并把它应用到所有模型上。没有这个基线,我们只知道 self-harness 胜过最小初始 harness,还不知道收益里有多少来自真正的模型相关发现,有多少只是重新发现标准智能体工程卫生。
5. 局限:promotion gate 带来了评估泄漏
最重要的限制不是基准太小,虽然它确实很小。真正的问题是,holdout 划分参与了候选升级。
论文谨慎地说,holdout 轨迹和失败证据不会给提议者看。确实如此。但算法仍然根据 holdout 划分评估候选 harness,并且只有在 holdout 性能不回归时才接受候选。换句话说,holdout 划分不是最终测试集,而是自动 promotion gate 使用的验证集。 (arXiv)
这不会让论文失效。工程上它反而更安全:这道门可以防止明显回归。但它削弱了泛化主张。更干净的设计需要三次划分:训练划分用于轨迹挖掘,验证划分用于升级,从未触及的最终测试划分用于报告。
第二个限制是范围。Terminal-Bench-2.0 是终端智能体的有用基准,但这篇文章只评估了 64 个案例子集,并排除了不稳定的 Web 和多模态任务。这对控制噪音是合理的,但也缩小了结论范围。对于验证器丰富、以产物为中心、基于终端的任务,结果最强。目前还没有证据表明 self-harness 对开放式研究、浏览、产品工作流或高风险运营智能体同样有效。 (arXiv)
第三个限制是通过率不回归是一个较弱的安全标准。作者直接承认这一点:接受的编辑可能反映特定于基准的失败模式,协议取决于验证者和跟踪质量,并且更高风险的 harness 更改将需要比通过率非回归更强的门。 (arXiv)
所以正确的解释不是“智能体现在可以自我提高”。正确的解释是:当故障可观察、验证器稳定、可编辑表面受限、候选编辑经过回归测试时,固定模型可以帮助改进自身的 harness。这已经很有价值了,但它和无限制自我改进不是一回事。
最后三句话
- 从这篇文章中学到的最有价值的东西:智能体工具应该被视为版本化、可编辑、可审计、回归测试的状态,而不是一次性的 prompt engineering。
- 这篇论文最可疑的一点:它的“自我完善”框架太强,因为系统严重依赖外部评估基础设施,并且把 holdout 划分用作 promotion gate,而不是最终未触及测试。 (arXiv)
- 它为未来研究指出的方向:构建真正的 harness 学习管道,严格分离训练/验证/测试,与强大的通用人工 harness 比较,并从特定于基准的产物修复,走向更广泛、更安全的智能体行为优化。