Self-Harness: Harnesses That Improve Themselves
Self-Harness: Harnesses That Improve Themselves
TLDR: The paper’s durable contribution is not open-ended self-improvement. It is evidence-driven harness versioning: keep the model and evaluator fixed, mine failed traces, propose bounded edits to the scaffold around the model, and promote only changes that survive regression tests.
Core Judgment
This is a strong systems paper, but its best idea is less romantic than the title suggests. The real value is not “self-improving agents” in the open-ended sense. The real value is that it treats an agent harness as an explicit, editable, versioned, testable software object.
The paper’s central move is simple and important: keep the base model fixed, keep the evaluator fixed, and let the model propose bounded changes to the surrounding harness based on its own failed execution traces. That is a clean experimental lens for separating “the model got better” from “the scaffold around the model got better.” (arXiv)
The most dangerous issue is this: the paper’s “held-out” split is not a final untouched test set. The held-out traces are not shown to the proposer, but held-out scores are used by the promotion gate. So the result proves validation-gated harness tuning, not yet broad generalization or open-ended self-improvement. (arXiv)
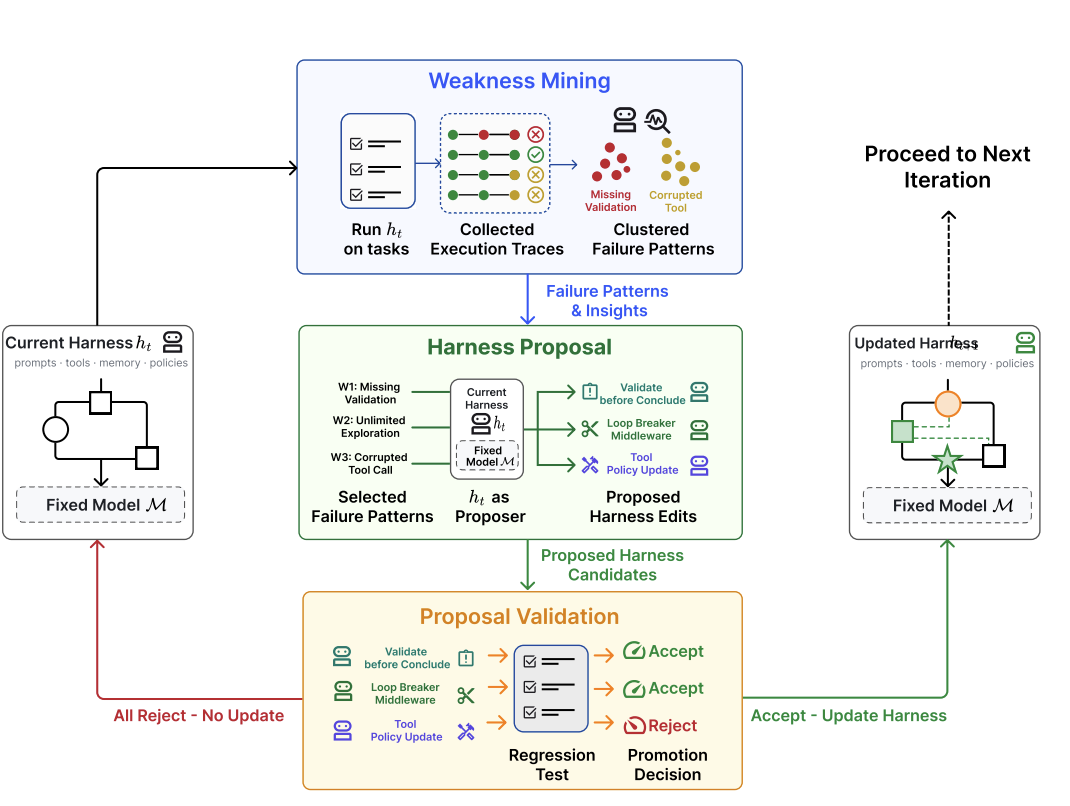
1. Motivation: the pain point is real, but “self-creation” is too loud
The paper starts from a very real agent-engineering problem: LLM agents are not shaped by the base model alone. They are shaped by the harness around the model: system prompts, tools, runtime mechanisms, verification rules, orchestration logic, and recovery policies. The same model can behave very differently under different harnesses, and a harness that works for one model may be suboptimal for another. (arXiv)
This is exactly the right framing. In production agent systems, many failures are not “the model cannot reason” failures. They are harness failures: the agent forgets to create the required artifact, keeps retrying the same broken command, fails to verify the final state, loses environment changes across shell calls, or reports success without checking the thing the verifier will actually inspect.
The authors are also right that human harness engineering does not scale cleanly. New models have different tool-use habits, error modes, context sensitivities, and recovery behaviors. If every new model needs a hand-tuned harness, agent engineering becomes a treadmill. (arXiv)
But the paper’s self-creation language is heavier than the actual mechanism. Self-Harness is not a model freely rewriting itself. It is a fixed model operating inside a carefully designed improvement loop, with structured trace mining, declared editable surfaces, regression tests, and an external acceptance rule. That is still valuable. It is just closer to disciplined automated harness maintenance than to recursive self-improvement.
2. Contribution: the core contribution is “harness-as-state,” not “self-improvement”
If I could keep only one contribution from this paper, I would keep this one: a harness should be treated as a stateful engineering object.
The paper defines a harness as the non-parametric scaffold around a fixed language model: instructions, tools, memory, state-management mechanisms, and the protocol through which the model observes tasks, calls tools, checks artifacts, and produces outputs. The model weights do not change. Only the harness changes across a lineage of versions. (arXiv)
That is the clean conceptual shift. Instead of thinking “prompt engineering is a bag of tricks,” this paper says: define the editable surfaces, collect behavioral evidence, propose a bounded edit, test it, and only then promote it into the next harness version.
This also makes the paper meaningfully different from ordinary reflection or memory-based self-improvement. Reflexion-like methods usually store feedback, memories, or response strategies. Self-Harness changes the declared scaffold that governs future agent behavior. It is also different from external agent-design search, because the same target model is used as the proposer rather than relying on a stronger outside optimizer. (arXiv)
The better name for the paper might be: evidence-driven harness versioning. “Self-Harness” is catchier, but the deeper idea is not that the agent becomes autonomous. It is that harness edits become empirical state transitions.
3. Method: the key insight is turning failures into constrained software patches
The method has three stages: Weakness Mining, Harness Proposal, and Proposal Validation. This structure is the paper’s strongest engineering contribution. (arXiv)
First, Weakness Mining runs the fixed model under the current harness and collects execution traces with verifier outcomes. Failed runs are not treated as isolated anecdotes. They are clustered by verifier-grounded failure signatures: what the verifier rejected, what agent-side behavior contributed to that rejection, and what reusable mechanism appears to be involved. This matters because two tasks can both fail by timeout while needing very different harness fixes. (arXiv)
Second, Harness Proposal asks the same model to generate several distinct, minimal candidate edits. The proposer sees the current harness, editable surfaces, structured failure patterns, passing behaviors that should be preserved, and summaries of previous attempted edits. Each proposal must target a concrete failure mechanism and map it to a specific editable harness surface. (arXiv)
Third, Proposal Validation treats every candidate edit as a new harness variant. It evaluates both the current harness and the candidate harness on held-in and held-out splits. A candidate is accepted only if it improves at least one split and does not degrade the other. This is the key reason the paper is more serious than a “let the model rewrite its prompt” demo. The proposer’s rationale is not enough. The edit has to survive regression testing. (arXiv)
The method’s real strength is that it converts vague agent advice into executable harness changes. “Be careful” is not enough. “Create the required output artifact early,” “stop exact command retries,” “verify dependency imports before solving,” or “redirect after too many tool calls” are harness-level interventions.
But this strength also exposes the dependency: Self-Harness needs a good evaluator, useful traces, stable verifiers, well-chosen editable surfaces, and a benchmark where failures can be converted into reusable policies. Without that infrastructure, “self-improvement” collapses back into plausible-sounding prompt rewriting.
4. Result: the strongest evidence is model-specific edit diversity, not just the pass-rate gain
The experiments are run on Terminal-Bench-2.0, a benchmark of containerized terminal tasks with deterministic verifiers. The authors use a fixed 64-case subset, excluding tasks that depend on unstable external web resources or multimodal inputs. They test three model backends: MiniMax M2.5, Qwen3.5-35B-A3B, and GLM-5. Across comparisons, the model, decoding setup, budget, tools, benchmark environment, and evaluator are held fixed; only the harness is allowed to vary. (arXiv)
The numbers are clearly positive. On held-out tasks, MiniMax M2.5 improves from 40.5% to 61.9%, Qwen3.5 improves from 23.8% to 38.1%, and GLM-5 improves from 42.9% to 57.1%. On held-in tasks, the corresponding gains are 43.0% to 50.0%, 15.1% to 36.0%, and 47.7% to 57.0%. (arXiv)
These gains are meaningful because the paper controls the main confound: the base model is not changing. The improvement comes from the harness. That is exactly the kind of evidence agent-systems papers should provide more often.
But the best evidence is not the bar chart. The best evidence is that the retained edits are different across models.
For MiniMax M2.5, the accepted edits push the agent to create required artifacts earlier, use correct content tags, and redirect after prolonged tool loops. The evolution run improves from 42.2% to 53.9%. (arXiv)
For Qwen3.5, the retained edits emphasize dependency prechecking, missing-artifact recovery, retry discipline, and tool-error-triggered middleware. The evolution run starts at 20.3% and reaches 36.7%. (arXiv)
For GLM-5, the edits focus on persistent environment changes across shell sessions and moving faster from exploration to implementation and testing. The harness improves from 46.1% to 57.0%. (arXiv)
This model-specificity is the important part. If the final result were just “add a longer generic prompt telling every model to verify more,” the paper would be much weaker. Instead, the edits correspond to different observed pathologies: MiniMax gets artifact and loop discipline, Qwen gets tool-error recovery and retry control, and GLM gets environment persistence and implementation pressure. (arXiv)
What I still miss is a stronger cheap baseline. For example: take a human-written generic checklist — create artifacts early, avoid repeated failed commands, verify final files, preserve shell state — and apply it to all models. Without that baseline, we know Self-Harness beats a minimal initial harness. We do not yet know how much of the gain comes from genuinely model-specific discovery versus rediscovering standard agent-engineering hygiene.
5. Limitation: the fatal weakness is evaluation leakage through the promotion gate
The most important limitation is not that the benchmark is too small, although it is small. The most important limitation is that the held-out split is used for candidate promotion.
The paper is careful to say that held-out trajectories and failure evidence are not shown to the proposer. That is true. But the algorithm still evaluates candidate harnesses on the held-out split and accepts candidates only when held-out performance does not regress. In other words, the held-out split is not a final test set. It is a validation set used by the automatic promotion gate. (arXiv)
This does not invalidate the paper. It actually makes the engineering safer: the gate prevents obvious regressions. But it weakens the generalization claim. A clean design would need a third split: held-in for trace mining, validation for promotion, and a never-touched final test split for reporting.
The second limitation is scope. Terminal-Bench-2.0 is a useful benchmark for terminal agents, but the paper evaluates only a 64-case subset and excludes unstable web and multimodal tasks. That is reasonable for controlling noise, but it also narrows the claim. The result is strongest for verifier-rich, artifact-centric, terminal-based tasks. It is not yet evidence that Self-Harness will work equally well for open-ended research, browsing, product workflows, or high-stakes operational agents. (arXiv)
The third limitation is that pass-rate non-regression is a weak safety criterion. The authors acknowledge this directly: accepted edits may reflect benchmark-specific failure patterns, the protocol depends on verifier and trace quality, and higher-stakes harness changes would require stronger gates than pass-rate non-regression. (arXiv)
So the right interpretation is not “agents can now improve themselves.” The right interpretation is: when failures are observable, verifiers are stable, editable surfaces are constrained, and candidate edits are regression-tested, a fixed model can help improve its own scaffold.
That is already valuable. It is just not the same as open-ended self-improvement.
Final three sentences
- The most valuable thing to learn from this paper: agent harnesses should be treated as versioned, editable, auditable, regression-tested state, not as one-off prompt engineering.
- The most suspicious thing about this paper: its “self-improvement” framing is too strong, because the system depends heavily on external evaluation infrastructure and uses the held-out split as a promotion gate rather than a final untouched test. (arXiv)
- The direction it suggests for future research: build a real harness-learning pipeline with train/validation/test separation, compare against strong generic human-written harnesses, and move from benchmark-specific artifact repair toward broader, safer agent behavior optimization.