Anthropic 博客:harness 工程与上下文工程
一堂分享课
在这些 Anthropic 工程帖子中,主题不是“让模型更努力地思考”。
主题是:
长智能体任务需要运行时,而不仅仅是提示。
上下文可能会发生变化。评测器可以赞扬糟糕的工作。沙箱可能会泄露权限。工具可以暴露凭据。交接可能会失去真正的目标。有用的工作是 harness 工程。
上下文重置不是忘记
长任务会随着上下文的填充而降低。一些模型还表现出一种情境焦虑:一旦他们感觉到窗口快满了,他们就开始过早结束。
上下文重置是运行时的答案:
old agent context
-> structured handoff
-> fresh agent
-> continuation from compressed state目标不是抛弃历史。就是把历史压缩成一个更好的工作入口点。
这就是区别:
raw history = everything that happened
handoff = what the next agent needs to continue评测器需要标准
评测器只会问“这好吗?”会漂移。
更好的评测器会提出具体的原则:
Does this follow the design rules?
Does it satisfy the task constraints?
Does the page actually work?
Does the output provide evidence?
What failed the rubric?对于前端或可视化产物,评测器不应只读文本。它应该使用工具:打开页面、交互、检查截图、检查布局,并对每个标准评分。
循环变为:
planner -> generator -> tool-using evaluator -> revised generatorharness 产生的反馈是模型本身无法可靠地产生的。
托管智能体分裂大脑、双手和记忆
托管智能体架构非常有用,因为它分离了容易模糊的角色。
| 组件 | 拥有 | 不应该拥有 |
|---|---|---|
| 会议 | 仅附加事件日志、审核、恢复 | 上下文选择策略 |
| Harness / 大脑 | 智能体循环、模型调用、工具路由、上下文工程 | 长期凭证或沙箱资源 |
| 模型 | 推理、规划、工具选择 | 直接基础设施接入 |
| 沙箱/手 | 代码执行、文件编辑、命令 | 主智能体状态或全局凭据 |
| 工具智能体 | 外部服务调用 | 将 token 暴露给模型或沙箱 |
| 凭证库 | 秘密 | 生成的代码或原始上下文 |
我想保留的一句话是:
会话不是上下文。
会话是持久的历史。上下文是根据该历史记录构建的运行时视图。
安全边界
安全故事也是一个运行时故事。模型、工具和沙箱不应全部获得相同的权限。
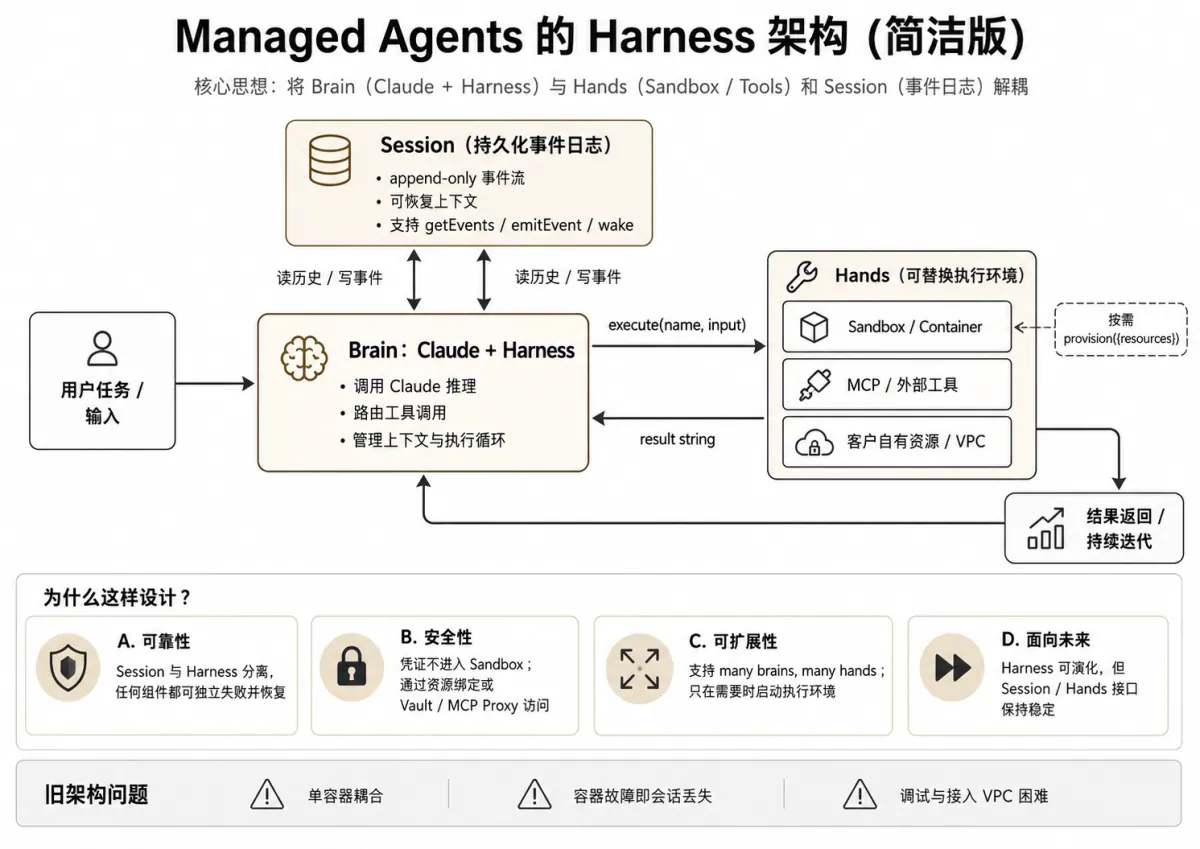
外部服务凭证应位于智能体和保管库后面。智能体可以请求采取行动;智能体使用限定范围的凭据执行;模型仅收到它需要的结果。
这可以防止生成的脚本、不受信任的网页或意外的日志转储继承广泛的 OAuth 令牌。
我会重用的模式
对于长期智能体:
1. Keep a durable event log.
2. Build context views from that log.
3. Reset context through structured handoff.
4. Use tool-enabled evaluators.
5. Separate brain, hands, and credentials.
6. Treat sandbox provisioning as a runtime resource.
7. Design logs and tool outputs for the model that will read them.我的收获
harness 工程是运行时智能体对齐的实用形式。
它决定模型看到什么、可以做什么、如何获得反馈、如何恢复以及永远不会收到什么权限。提示很重要,但持久的杠杆作用是围绕模型的循环。