MiniMax Sparse Attention:教长上下文模型使用索引
MiniMax 稀疏注意力:教授长上下文模型使用索引
TLDR:MiniMax Sparse Attention 将长上下文视为可搜索记忆,而不是一堵平坦的 token 墙。轻量级索引分支选择最相关的键值块,主分支仍然对这些选定块使用精确的 softmax 注意力。
长上下文语言模型承诺了一个简单的魔术:将整个代码库、一份长研究报告、一段网络浏览轨迹或一段长达数小时的对话放入提示中,然后让模型立即对所有这些进行推理。这个承诺很有吸引力,因为许多实际任务并不短。软件智能体需要 repo 历史记录。研究助理需要数十份文件。私人助理需要记忆。多模式智能体需要长视频和屏幕轨迹。
但标准 Transformer 有一个令人不舒服的习惯:上下文越长,注意力越贵。在全因果注意力里,每个新 token 都要和所有历史 token 比较。这很强大,但到了百万 token 规模,就像要求读者在写下一句话之前重新读完整个图书馆。
论文 MiniMax Sparse Attention 提出了一个实际问题:模型能否保留 softmax 注意力的大部分好处,同时只关注更少的 token?它的答案是 MSA,一种围绕轻量级可学习索引器构建的块稀疏注意力机制。中心隐喻很简单:
长上下文模型不应该以昂贵的注意力来扫描每个单词。它应该首先使用廉价索引来查找最相关的块,然后将注意力集中在这些块上。
这个想法听起来很明显。困难的部分是使其在 GPU 上可训练、稳定且快速。
问题:长上下文不仅仅是一个更大的窗口
上下文窗口通常用最大长度描述:32K、128K、1M token。但更大的窗口只有在模型负担得起时才有用。
主要有两个推理阶段:
- 预填充:模型读取提示并构建键值缓存。
- 解码:模型逐个生成输出 token,反复查询缓存。全注意力会同时伤害这两个阶段。预填充时,模型必须处理巨大的提示;解码时,每个新生成的 token 都可能要参与大量历史记录。分组查询注意力(GQA)减少了键值头数量,让推理更便宜,但它没有消除基本的长上下文问题:模型仍然在整个序列中查找。
稀疏注意力试图改变这个问题。它不再问“所有历史 token 里哪些重要?”,而是问“应该允许这个 query 检查哪一小组历史 token?”
危险在于,糟糕的稀疏规则会让模型变盲。滑动窗口速度很快,但主要看到附近文本。固定全局模式可预测,却无法适应内容。逐 token 学习的路由器很灵活,但对高效 GPU 执行来说通常太不规则。
MSA 选择中间路径:学习选择,但以块粒度;特定于组的路由,但与 GQA 结构保持一致。
核心思想:一个廉价的索引分支加上一个精确的主分支
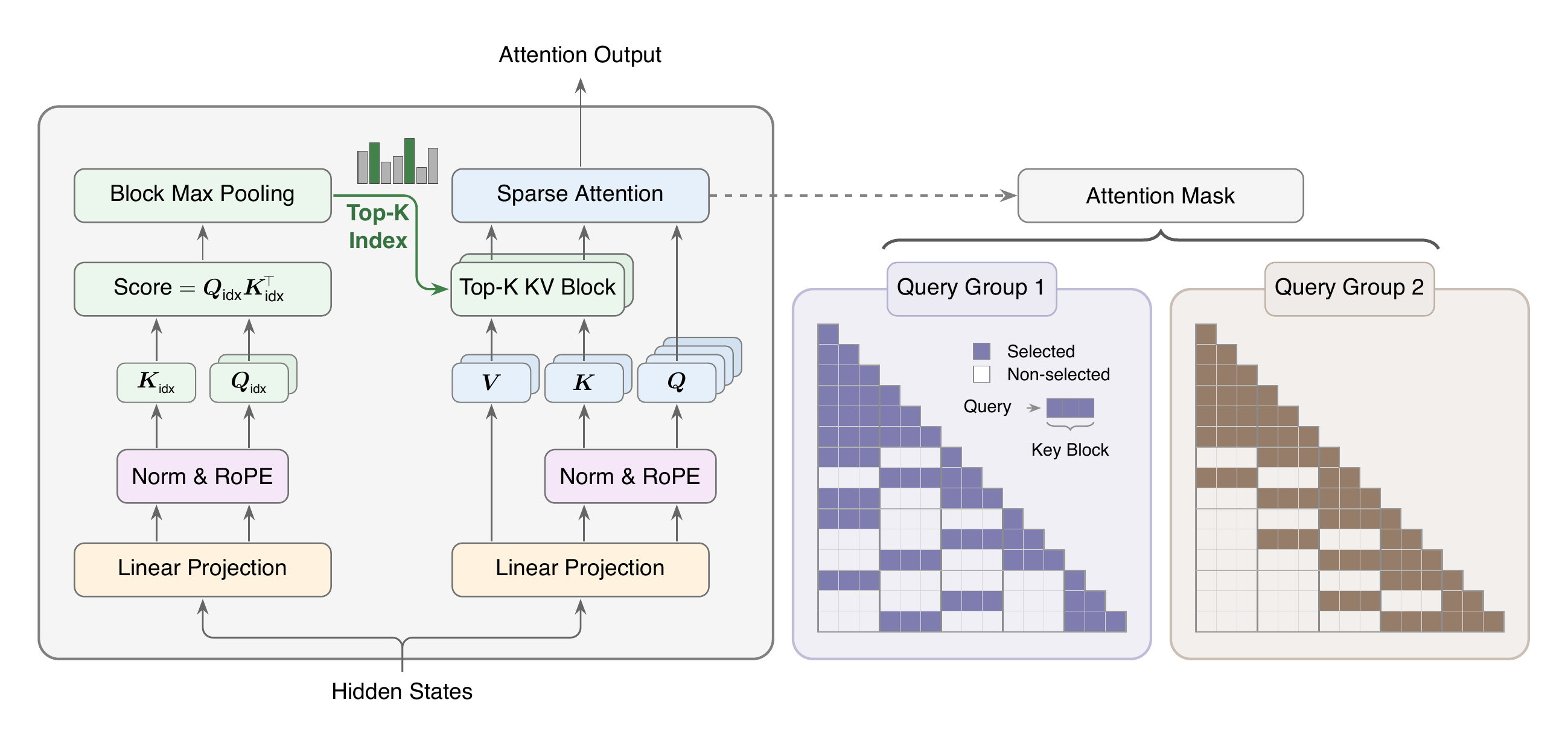
图 1:MSA 添加了一个轻量级索引分支,用于选择 Top-K 键值块。然后,主分支只对选定块运行稀疏 softmax 注意力。来源:论文 HTML 渲染中的图 1。
MSA 保留了熟悉的注意力管道,但将工作分为两个分支。
索引分支像侦察兵。它以低成本查看因果上下文,并对键值块评分。块是一段连续 token。索引器不是逐个选择 token,而是选择块,这样内存访问更规则。
主分支像读者。一旦索引器选出少量块,主分支就会对这些块内的 token 执行标准缩放点积 softmax 注意力。这一点很重要:MSA 没有用新的近似替代 softmax 注意力。它只是限制了 softmax 注意力能看到的 token 集合。一个有用的类比是带目录的书:目录不是书的论证,而是找到正确章节的廉价方法。MSA 的 Index Branch 扮演目录角色;主分支仍然仔细阅读。
为什么要屏蔽和 GQA 群组?
要理解为什么 MSA 选择块而不是任意 token,从 GPU 的角度思考会有所帮助。GPU 喜欢规则计算:大块、连续内存、可预测的矩阵乘法。为每个 query head 随机选择单独 token 的路由器,也许能节省理论 FLOP,但可能制造分散的内存读取和无法高效运行的小操作。
块是一种妥协。选择整个块不如选择单个令牌精确,但它可以保持键值内存连续。一旦选择了一个块,内核就可以一起处理许多令牌。
MSA 还在 GQA 组 级别进行选择。在 GQA 中,多个查询头共享一个键值头。 MSA 使用此分组:共享相同键值头的查询头也共享选定的块集。不同的 GQA 组仍然可以选择不同的块。
这个设计有一个很好的平衡:
- 它比所有头共享的一种全局稀疏模式更具表现力。
- 它比每个查询头选择完全独立的令牌集更加硬件友好。
- 它与许多现代LLM已经使用的结构相匹配。
结果是内容自适应稀疏模式仍然具有足够的规律性以有效实现。
索引分支如何选择区块
对于每个 query token 和每个 GQA 组,索引分支创建一个轻量级 query,并将其与上下文中的轻量级 key 比较。它先得到 token 级分数,再把这些分数合并成块级分数。论文使用最大池化:只要块内有任何 token 看起来高度相关,整个块就会成为候选。然后索引器选择 Top-K 块。即使学习到的分数较低,最新的局部块也始终会被包含。这种局部保证很重要,因为附近 token 通常对语法、短程连贯性和训练稳定性关键。
选定的块成为主分支的注意力掩模。如果当前查询正在长代码文件中写入,则本地块可能包含直接周围的函数体;另一个选定的块可能包含更早的类定义;另一个可能包含导入的助手;大多数不相关的块都会被跳过。
这是关键转变:长上下文变成了可搜索记忆,而不是每个注意力头都必须平等扫描的平坦 token 墙。
训练挑战:Top-K 选择不会自行训练
优雅的架构背后有一个严重训练问题:Top-K 选择是离散的。块要么被选中,要么没被选中。这个决定不会像普通连续操作那样提供平滑梯度。
如果唯一训练信号是下一个 token 预测,索引分支就很难可靠学会应该选择哪些块。这就像要求图书馆员改进目录,却不告诉他专家读者实际使用了哪些书架。
MSA 通过辅助 KL 对齐损失 解决这个问题。训练期间,主分支会在选定 token 上产生注意力分布。索引分支也会生成这些 token 的分布。KL 损失训练索引分支去匹配主分支的注意力模式。
用简单的语言来说:昂贵的读者教会廉价的索引器什么是相关性。
这篇论文添加了两种很容易被忽视但对这个方法关键的稳定剂。
第一,KL 梯度与主干分离。否则,模型可能通过让主分支注意力更容易被索引分支模仿来降低 KL 损失,而不是让索引分支变好。分离梯度能让辅助损失专注于训练索引器。第二,索引器需要预热。在训练或转换早期,随机索引器会选择较差的块,让主分支缺少有用上下文。MSA 一开始让模型使用全注意力,同时训练索引分支模仿全注意力模式。只有完成这种预热之后,稀疏注意力才接管。
这些细节赋予 MSA 很大的实用性。该架构说“使用索引”。训练秘诀解释了索引如何变得有用。
系统教训:必须针对硬件塑造稀疏的注意力
稀疏算法并不一定是快速算法。许多稀疏方法在 FLOPs 图表上看起来很出色,但在挂钟时间上却令人失望,因为 GPU 不喜欢不规则的内存访问、微小的矩阵乘法和负载不平衡。
MSA 将内核设计视为方法的一部分,而不是事后的想法。
一项优化是免 softmax 的 Top-K 选择。由于 softmax 保留排序,索引器在选择最高分块之前不需要计算完整 softmax。它可以直接使用原始分数,避免不必要的求幂和归一化。
另一个是KV-外部稀疏注意力。简单的实现可能会循环查询并收集每个查询选择的块。相反,MSA 围绕选定的键值块组织计算并收集需要每个块的查询。这提高了重用性:当许多查询选择同一块时,该块可以加载一次并用于许多计算。
内核还必须处理“热”块。一些块,例如第一块或当前局部块,可能被许多 query 选择。MSA 会仔细安排这些工作,避免某个热门块成为瓶颈。
这是更广泛的教训:只有当稀疏模式和 GPU 执行路径一起设计时,稀疏注意力才会成为产品就绪的加速。
实验表明什么
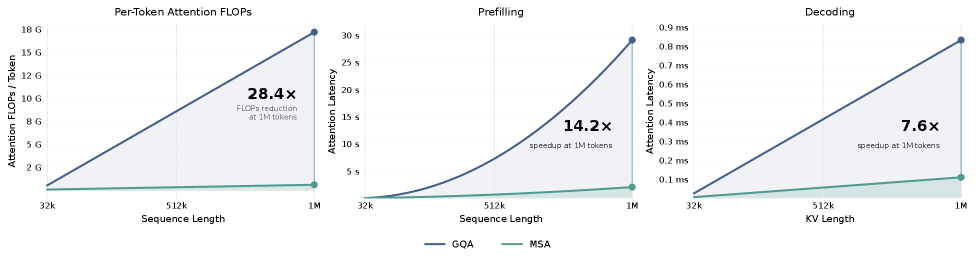
图 2:论文报告称,MSA 的优势会随上下文长度增加而增长。在 1M 上下文中,H800 上每个 token 的注意力 FLOP 降低了 28.4 倍,预填充速度提升 14.2 倍,解码速度提升 7.6 倍。来源:论文 HTML 渲染中的图 4。
这篇论文在 109B 参数 Mixture-of-Experts 模型上评估 MSA,每个 token 大约激活 6B 参数,并且使用原生多模态训练。这很重要:MSA 不只是放在小玩具机制上测试。
主要比较是针对 Full-Attention / GQA 基线。论文研究了两条路径:
- MSA-PT:从头开始使用 MSA 进行训练。
- MSA-CPT:从全注意力检查点开始,用 MSA 替换注意力,然后继续预训练。
报告的训练曲线很接近:与全注意力运行相比,稀疏预训练没有表现出明显的语言建模损失退化。基准表也不是一个干净的“MSA 无处不在”的故事,这是一个好兆头。相反,结果更加实际:MSA 保持广泛的竞争力,同时从长远来看变得更加便宜。
效率结果是最清晰的部分。在 1M 上下文中,论文报告称,H800 上每个 token 的注意力计算量减少了 28.4 倍,预填充速度提高 14.2 倍,解码挂钟速度提高 7.6 倍。正如预期,运行时加速小于 FLOP 降幅,因为路由、收集、Top-K 选择和负载均衡仍然需要时间。但趋势才是最重要的:随着上下文增长,密集注意力会继续关注完整历史,而 MSA 让主要注意力预算保持相对固定。
如何解读其意义
MSA 不应被解读为“长上下文的最终答案”。它可以更好地理解为可能变得更常见的设计模式的有力示例。
设计模式分为三部分:
- 在重要的地方保持精确的 softmax 注意力。 除非必要,否则不要丢弃 Transformer 中最强的部分。
- 使用学习选择器来决定重要的地方。 固定窗口对于许多长上下文任务来说过于僵化。
- 使选择器对硬件友好。 GPU 无法有效执行的稀疏模式主要是理论上的胜利。仍然存在权衡。索引分支仍然必须对上下文进行评分。选定的块预算可能会错过某些任务中的证据。加速取决于专门的内核。但这篇论文的贡献并不是含糊地声称稀疏注意力可以有所帮助。它给出了一个具体的方案:GQA 对齐的块选择、KL 监督的索引训练、预热、梯度分离、局部块强制和内核协同设计。
这个配方很重要,因为长上下文 LLM 正在从演示走向生产工作负载。在演示中,模型只需要接受一百万个 token;在生产中,它必须足够便宜地处理这些 token,才能服务许多用户、许多文档和许多智能体步骤。
小结
MiniMax Sparse Attention 将长上下文重新构建为 Transformer 内部的索引问题。
全注意力把过去视为一个平坦序列,其中每个 token 都是昂贵交互的候选者。MSA 把过去变成块,让一个小的可学习分支选择最有希望的块,再让主注意力机制仔细读取这些块。
最重要的教训不仅仅是“让注意力变得稀疏”。这个教训更加尖锐:
长上下文模型需要知道去哪里寻找,并且选择去哪里寻找的机制必须是可训练的、稳定的,并且适合运行它的硬件。
这就是 MSA 有趣的原因。它不仅仅是一个新的注意力面具。它是一个内置于注意力层的小型搜索引擎。
参考文献
- Xunhao Lai 等人,MiniMax Sparse Attention,arXiv:2606.13392,2026:https://arxiv.org/abs/2606.13392
- 用于图形的 arXiv HTML 渲染:https://arxiv.org/html/2606.13392v1
- MiniMax-AI MSA 内核 repo:https://github.com/MiniMax-AI/MSA