MiniMax Sparse Attention: Teaching Long-Context Models to Use an Index
MiniMax Sparse Attention: Teaching Long-Context Models to Use an Index
TLDR: MiniMax Sparse Attention treats long context as searchable memory rather than a flat wall of tokens. A lightweight learned index branch selects the most relevant key-value blocks, and the main branch still uses exact softmax attention over those selected blocks.
Long-context language models promise a simple magic trick: place a whole codebase, a long research report, a web-browsing trace, or a multi-hour conversation into the prompt, and let the model reason over all of it at once. The promise is attractive because many real tasks are not short. Software agents need repository history. Research assistants need dozens of documents. Personal assistants need memory. Multimodal agents need long video and screen traces.
But the standard Transformer has an uncomfortable habit: when the context grows, attention becomes expensive very quickly. In full causal attention, each new token compares itself with every earlier token. That is powerful, but at million-token scale it starts to look like asking a reader to reread the whole library before writing each next sentence.
The paper MiniMax Sparse Attention asks a practical question: can a model keep most of the benefits of softmax attention while paying attention to far fewer tokens? Its answer is MSA, a block-sparse attention mechanism built around a lightweight learned indexer. The central metaphor is simple:
A long-context model should not scan every word with expensive attention. It should first use a cheap index to find the most relevant blocks, then spend exact attention on those blocks.
That idea sounds obvious. The hard part is making it trainable, stable, and fast on GPUs.
The problem: long context is not just a bigger window
A context window is often described by its maximum length: 32K, 128K, 1M tokens. But a larger window is only useful if the model can afford to use it.
There are two main inference phases:
- Prefill: the model reads the prompt and builds the key-value cache.
- Decode: the model generates output tokens one by one, repeatedly consulting that cache.
Full attention hurts both phases. During prefill, the model must process a huge prompt. During decode, every generated token may need to attend over a huge history. Grouped Query Attention, or GQA, reduces the number of key-value heads and makes inference cheaper, but it does not remove the basic long-context problem: the model is still looking across the whole sequence.
Sparse attention tries to change the question. Instead of asking “which of all previous tokens matter?”, it asks “which smaller set of previous tokens should this query be allowed to inspect?”
The danger is that a bad sparse rule can make the model blind. A sliding window is fast, but it mostly sees nearby text. A fixed global pattern is predictable, but it cannot adapt to the content. A per-token learned router is flexible, but often too irregular for efficient GPU execution.
MSA chooses a middle path: learned selection, but at block granularity; group-specific routing, but aligned with GQA structure.
The core idea: a cheap index branch plus an exact main branch
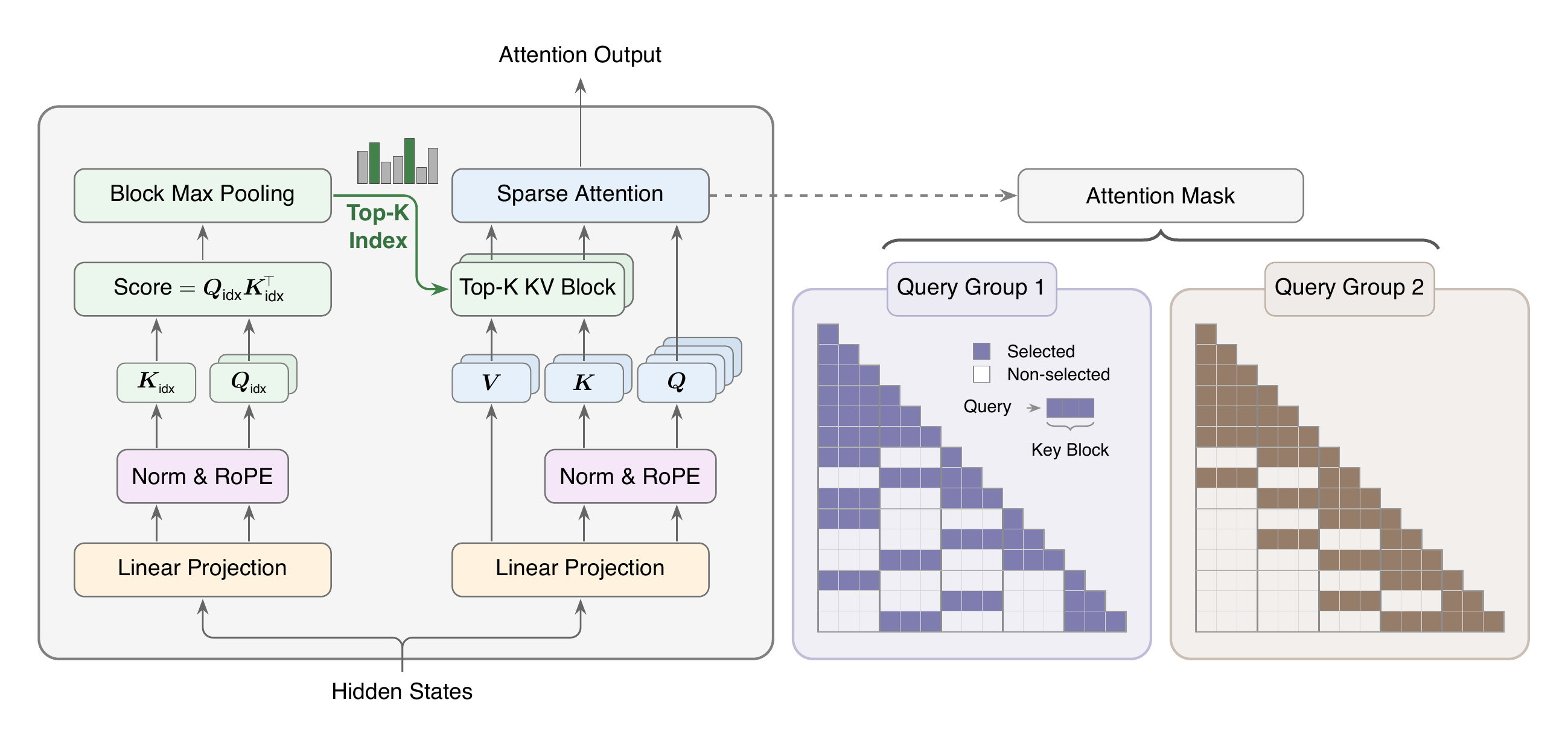
Figure 1. MSA adds a lightweight Index Branch that selects Top-K key-value blocks. The Main Branch then runs sparse softmax attention only over those selected blocks. Source: Figure 1 from the paper HTML rendering.
MSA keeps the familiar attention pipeline, but splits the work into two branches.
The Index Branch is the scout. It looks over the causal context cheaply and scores key-value blocks. A block is a contiguous chunk of tokens. Instead of selecting individual tokens one by one, the indexer selects blocks, which makes memory access more regular.
The Main Branch is the reader. Once the indexer has selected a small number of blocks, the main branch performs standard scaled dot-product softmax attention over the tokens inside those blocks. This point matters: MSA is not replacing softmax attention with a new approximation. It is restricting the set of tokens that softmax attention sees.
A useful analogy is a book with a table of contents. The table of contents is not the argument of the book. It is a cheap way to find the right chapters. MSA’s Index Branch plays the role of the table of contents; the Main Branch still does the careful reading.
Why blocks and GQA groups?
To understand why MSA selects blocks rather than arbitrary tokens, it helps to think from the GPU’s point of view. GPUs are happiest when computation is regular: large tiles, contiguous memory, predictable matrix multiplications. A router that picks random individual tokens for every query head may save theoretical FLOPs, but it can create scattered memory reads and small operations that do not run efficiently.
Blocks are a compromise. Selecting a whole block is less precise than selecting a single token, but it keeps key-value memory contiguous. Once a block is selected, the kernel can process many tokens together.
MSA also makes selections at the level of GQA groups. In GQA, several query heads share one key-value head. MSA uses this grouping: query heads that share the same key-value head also share the selected block set. Different GQA groups can still choose different blocks.
This design has a nice balance:
- It is more expressive than one global sparse pattern shared by all heads.
- It is more hardware-friendly than every query head choosing a completely separate token set.
- It matches the structure already used by many modern LLMs.
The result is a content-adaptive sparse pattern that still has enough regularity to be implemented efficiently.
How the Index Branch chooses blocks
For each query token and each GQA group, the Index Branch creates a lightweight query and compares it against lightweight keys from the context. It first gets token-level scores, then pools those scores into block-level scores. The paper uses max pooling: if any token inside a block looks very relevant, the whole block becomes a candidate.
Then the indexer selects the Top-K blocks. The most recent local block is always included, even if the learned score is low. This local guarantee is important because nearby tokens are often essential for syntax, short-range coherence, and training stability.
The selected blocks become an attention mask for the Main Branch. If the current query is writing inside a long code file, the local block might contain the immediate surrounding function body; another selected block might contain a class definition far earlier; another might contain an imported helper; most unrelated blocks are skipped.
This is the key shift: long context becomes searchable memory, not a flat wall of tokens that every attention head must scan equally.
The training challenge: Top-K selection does not train itself
The elegant architecture hides a serious training problem. Top-K selection is discrete. A block is selected or not selected. That decision does not provide a smooth gradient in the usual way.
If the only training signal were next-token prediction, the Index Branch would not reliably learn which blocks should have been selected. It would be like asking a librarian to improve the catalog without ever showing which shelves expert readers actually used.
MSA solves this with an auxiliary KL alignment loss. During training, the Main Branch produces an attention distribution over the selected tokens. The Index Branch also produces a distribution over those tokens. The KL loss trains the Index Branch to match the Main Branch’s attention pattern.
In plain language: the expensive reader teaches the cheap indexer what relevance looks like.
The paper adds two stabilizers that are easy to overlook but central to the method.
First, the KL gradient is detached from the backbone. Without this, the model could reduce the KL loss by making the Main Branch’s attention easier for the Index Branch to imitate, rather than by making the Index Branch better. Detaching the gradient keeps the auxiliary loss focused on training the indexer.
Second, the indexer is warmed up. Early in training or conversion, a random indexer would choose poor blocks, starving the Main Branch of useful context. MSA initially lets the model use full attention while training the Index Branch to imitate full-attention patterns. Only after this warmup does sparse attention take over.
These details give MSA much of its practical character. The architecture says “use an index.” The training recipe explains how the index learns to be useful.
The systems lesson: sparse attention must be shaped for the hardware
A sparse algorithm is not automatically a fast algorithm. Many sparse methods look excellent on a FLOPs chart but disappoint in wall-clock time because GPUs dislike irregular memory access, tiny matrix multiplications, and load imbalance.
MSA treats kernel design as part of the method rather than an afterthought.
One optimization is exp-free Top-K selection. Since softmax preserves ordering, the indexer does not need to compute a full softmax before selecting the largest blocks. It can select using raw scores and avoid unnecessary exponentiation and normalization.
Another is KV-outer sparse attention. A naive implementation might loop over queries and gather the blocks each query selected. MSA instead organizes computation around selected key-value blocks and gathers the queries that need each block. This improves reuse: when many queries select the same block, that block can be loaded once and used for many computations.
The kernel also has to handle “hot” blocks. Some blocks, such as the first block or the current local block, may be selected by many queries. MSA schedules this work carefully to avoid one popular block becoming a bottleneck.
This is the broader lesson: sparse attention only becomes a product-ready speedup when the sparse pattern and the GPU execution path are designed together.
What the experiments show
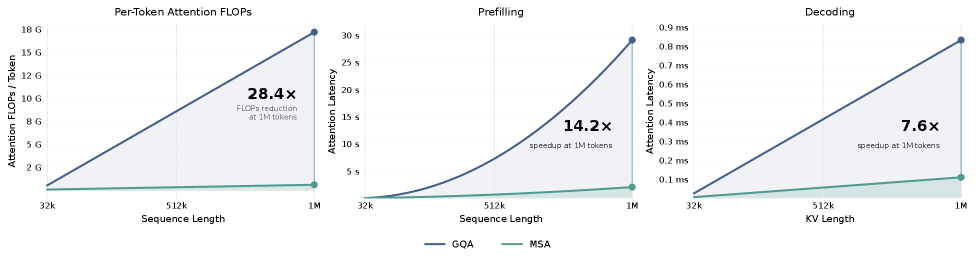
Figure 2. The paper reports that MSA’s advantage grows with context length. At 1M context, it reports 28.4× lower per-token attention FLOPs, 14.2× faster prefill, and 7.6× faster decoding on H800. Source: Figure 4 from the paper HTML rendering.
The paper evaluates MSA on a 109B-parameter Mixture-of-Experts model with about 6B active parameters per token and native multimodal training. This is important: MSA is not only tested as a small toy mechanism.
The main comparison is against a Full-Attention / GQA baseline. The paper studies two paths:
- MSA-PT: train with MSA from scratch.
- MSA-CPT: start from a full-attention checkpoint, replace attention with MSA, then continue pretraining.
The reported training curves are close: sparse pretraining does not show obvious language-modeling loss degradation compared with the full-attention run. The benchmark table is also not a clean “MSA wins everywhere” story, and that is a good sign. Instead, the result is more practical: MSA stays broadly competitive while becoming much cheaper at long context.
The efficiency results are the clearest part. At 1M context, the paper reports a 28.4× reduction in per-token attention compute, plus 14.2× prefill and 7.6× decoding wall-clock speedups on H800. Runtime speedups are smaller than FLOPs reductions, as expected, because routing, gathering, Top-K selection, and load balancing still cost time. But the trend is what matters: as the context grows, dense attention keeps paying for the full history, while MSA keeps the main attention budget relatively fixed.
How to read the significance
MSA should not be read as “the final answer to long context.” It is better understood as a strong example of a design pattern that is likely to become more common.
The design pattern has three parts:
- Keep exact softmax attention where it matters. Do not throw away the strongest part of the Transformer unless necessary.
- Use a learned selector to decide where it matters. Fixed windows are too rigid for many long-context tasks.
- Make the selector hardware-friendly. A sparse pattern that GPUs cannot execute efficiently is mostly a theoretical win.
There are still trade-offs. The Index Branch must still score the context. The selected-block budget may miss evidence in some tasks. The speedups depend on specialized kernels. But the paper’s contribution is not a vague claim that sparse attention can help. It gives a concrete recipe: GQA-aligned block selection, KL-supervised index training, warmup, gradient detach, local-block forcing, and kernel co-design.
That recipe matters because long-context LLMs are moving from demos to production workloads. In a demo, a model only needs to accept a million tokens. In production, it must process those tokens cheaply enough to serve many users, many documents, and many agent steps.
Takeaway
MiniMax Sparse Attention reframes long context as an indexing problem inside the Transformer.
Full attention treats the past as a flat sequence where every token is a candidate for expensive interaction. MSA turns the past into blocks, asks a small learned branch to choose the most promising ones, and then lets the main attention mechanism read those blocks carefully.
The most important lesson is not simply “make attention sparse.” The lesson is sharper:
Long-context models need to know where to look, and the mechanism that chooses where to look must be trainable, stable, and shaped for the hardware that runs it.
That is why MSA is interesting. It is not just a new attention mask. It is a small search engine built into the attention layer.
References
- Xunhao Lai et al., MiniMax Sparse Attention, arXiv:2606.13392, 2026: https://arxiv.org/abs/2606.13392
- arXiv HTML rendering used for figures: https://arxiv.org/html/2606.13392v1
- MiniMax-AI MSA kernel repository: https://github.com/MiniMax-AI/MSA