Crafting Interpreters(I):当源码开始拥有结构
Crafting Interpreters(I):当源码开始拥有结构
一串字符如何获得边界、层级与求值顺序
print 1 - 2 * 3 < 4 == false;人读到这行代码时,几乎不会迟疑。我们天然地把 2 * 3 看作一个整体,知道减法先于比较完成,而相等判断位于最外层。可当实现刚收到文件时,它并没有这些知识。它面对的只是一串平铺的字符:乘法没有特权,操作数之间没有父子关系,源码里也没有一棵隐形的树替机器安排运行顺序。
先把问题收紧到一个能追踪的瞬间:
究竟是哪一个阶段,第一次把
2 * 3放进减法的右侧?
完整生命周期可以先压成一行:
characters → tokens → AST → evaluation但每个箭头解决的是不同的不确定性。扫描器决定“哪些字符属于同一个词法单元”;解析器决定“这些单元如何嵌套”;AST 把这次结构选择保存下来,使后续阶段不必重新猜测;真正的求值则要等到这些工作全部结束之后。
读完后,你应该能把开头这一行 Lox 从字符缓冲区一路追到 token,再追到 AST,并准确说明 maximal munch、lookahead、precedence、associativity、recursive descent 与 panic-mode recovery 分别在哪一步介入。
这个系列之后会反复追问:“n 现在在哪里?”第一篇先停在更早的地方:一个变量能够被绑定、存储、捕获或保活之前,实现首先得学会把源码变成结构。
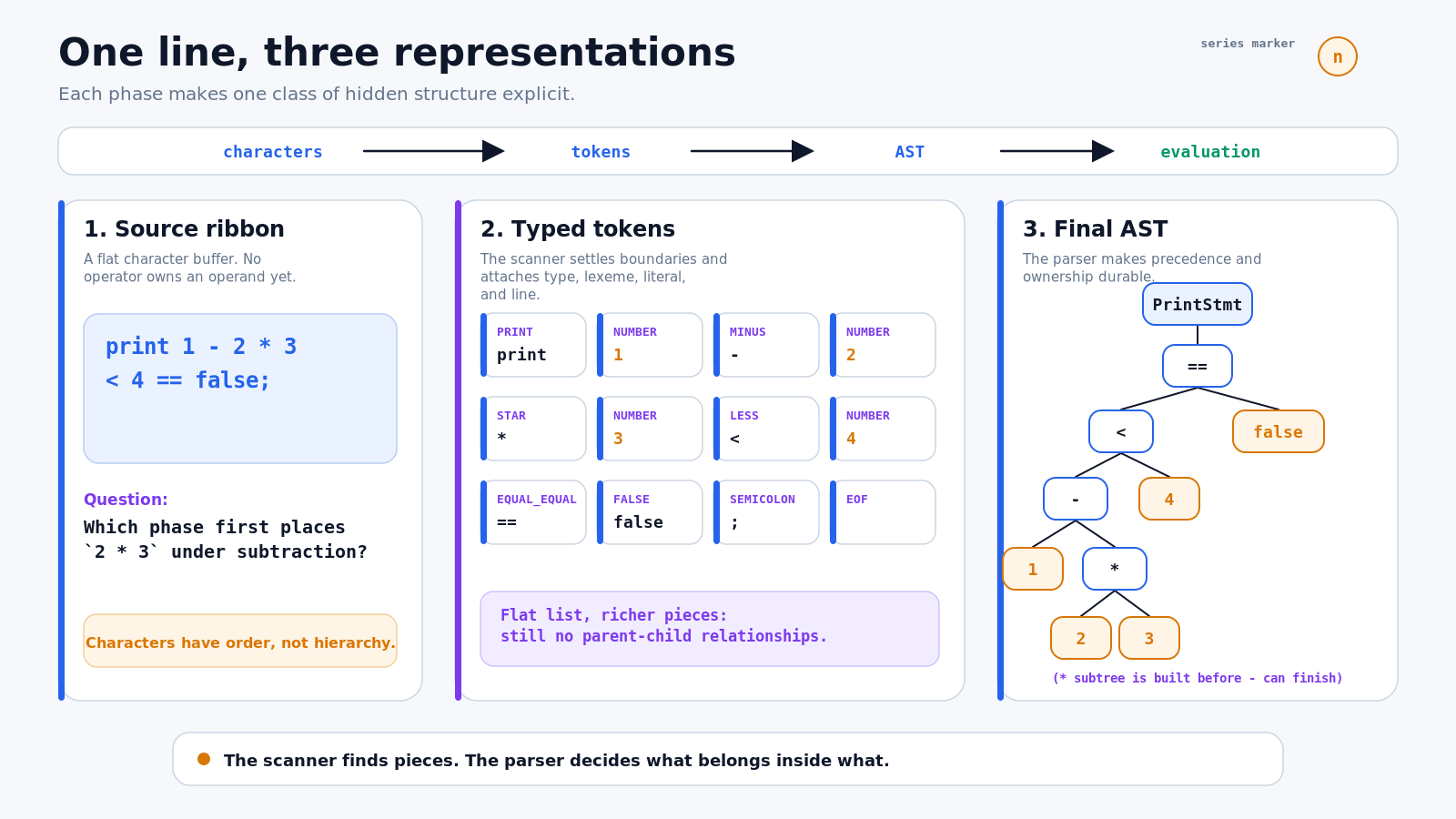
图 1:扫描器显式化 token 边界;解析器显式化归属关系与求值顺序。
1. 程序抵达时,仍然是平的
把 jlox 冻结在扫描器读取第一个字符之前。整个源文件只是一个 Java String。扫描器只用三个整数记录位置:
start指向当前 lexeme 的第一个字符;current指向已经消费部分之后的位置;line记录当前行号,供错误信息使用。
这三个字段看起来朴素,因为扫描器此时并不试图理解表达式。它只是在一条线性输入上反复完成同一个小动作:
token lexeme 起点
→ 消费足够多的字符
→ 判断 lexeme 类型
→ 产生一个 token外层循环把这笔交易写得很清楚:
List<Token> scanTokens() {
while (!isAtEnd()) {
start = current;
scanToken();
}
tokens.add(new Token(EOF, "", null, line));
return tokens;
}处理开头一行的第一次循环时,start == current == 0。scanToken() 调用 advance(),先消费字符 p。p 可以是标识符的开头,于是扫描器在下一个字符仍为字母、数字或 _ 时继续前进。它依次消费 r、i、n、t,在空格之前停下。
到这个时刻,源码切片才第一次获得明确边界:
source[start..current) = "print"扫描器随后拿完整 lexeme 去关键字表查询,发现它是保留字,于是发出一个类型为 PRINT、lexeme 为 print 的 token。下一轮才处理空格:start 移到空格,advance() 消费它,但因为空白对 Lox 解析器没有语义,扫描器不产生 token。
这是第一层结构增量:五个字符变成了一个有类型的单元。扫描器仍不知道 print 后面包含表达式,也完全不知道乘法应该先算。它只做两件事:确定边界,给边界内的内容命名。
现在,扫描器已经能给源码分块;但下一个边界,有时要取决于尚未消费的字符。
2. 边界本身就是语言策略
扫描器表面上像一个膨胀的 switch,真正的语言设计却藏在边界条件里。看三组小测试:
or
orchid
! =
!=
123.45
123.第一组引出 maximal munch(最长匹配)。如果扫描器在看到 orchid 的前两个字符时立刻发出关键字 or,剩余字符就会被撕成毫无意义的碎片。Lox 采用最长匹配原则:当多个词法规则都能匹配当前位置时,消费字符最多的规则获胜。
所以,关键字判断必须发生在标识符扫描完成之后,而不是扫描过程中。扫描器先完整消费 orchid,再查关键字表。or 命中,成为 OR;orchid 未命中,成为 IDENTIFIER。顺序不能反:先确定边界,再分类。
第二组需要一个字符的 lookahead。扫描器刚消费 ! 时,还不能确定它是 BANG 还是 BANG_EQUAL。只有下一个字符确实为 = 时,才把它一起消费:
private boolean match(char expected) {
if (isAtEnd()) return false;
if (source.charAt(current) != expected) return false;
current++;
return true;
}
private char peekNext() {
if (current + 1 >= source.length()) return '\0';
return source.charAt(current + 1);
}对 !=,match('=') 成功,两个字符组成一个 token。对 ! =,下一个字符是空格,匹配失败,扫描器先发出 BANG;后续循环再发出 EQUAL。这里的空格不是纯排版,它阻止两个字符共享同一个 lexeme。
数字测试需要两个字符的 lookahead。扫描器已经消费 123 后遇到点号,只有点号后面仍是数字时,它才属于当前数字:
peek() == '.' && isDigit(peekNext())因此,123.45 会成为一个 NUMBER token,并携带数值 123.45。而 123. 不满足条件:点号之后没有数字。扫描器先发出 NUMBER("123"),下一轮再单独发出 DOT(".")。换句话说,按照 Lox 的规则,尾随点号不会悄悄并入浮点字面量。
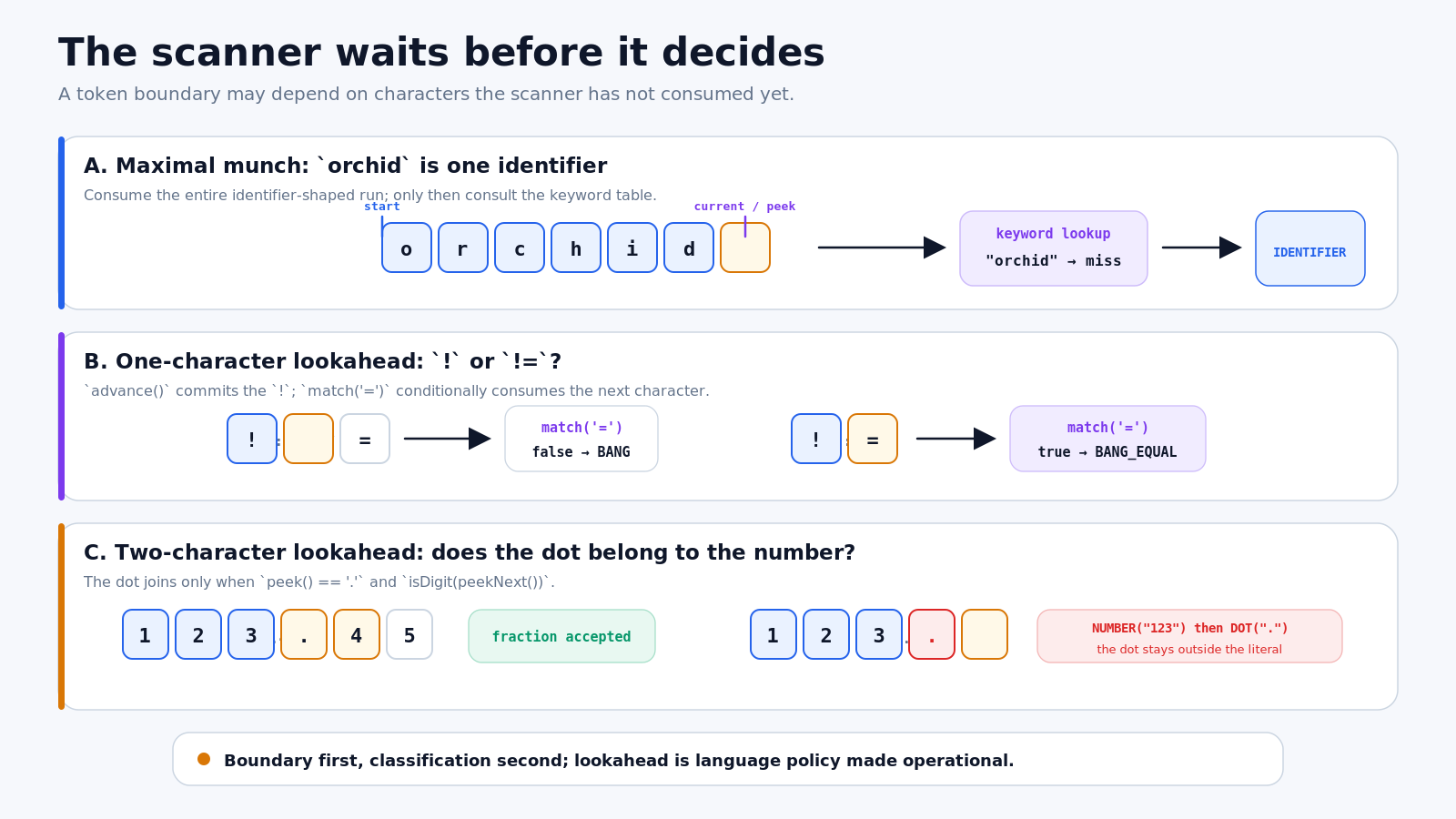
图 2:扫描器有时必须等待。最长匹配先完成候选 lexeme,lookahead 再判断下一个字符能否加入。
每个 token 至少携带四类信息:
- type:如
NUMBER、STAR、PRINT,后续阶段不必反复比较字符串; - lexeme:源码中的原始切片,便于错误定位,也保留操作符实际拼写;
- literal value:数字与字符串会在扫描阶段转换成更适合运行时使用的值;布尔值和
nil在扫描阶段仍是关键字,解析器之后再创建对应的 literal 节点; - source location:
jlox保存行号,生产级工具通常还会保存偏移、列号和长度。
Token 对象本身也是阶段契约。扫描器一旦发出 NUMBER,解析器就不再需要知道它来自手写 digit loop、正则表达式还是生成的状态机;它只消费统一 token 流。反过来,扫描器也无需知道这个数字之后会成为减法左操作数、函数参数还是字段初始值。好的阶段边界,不只是增加信息,也会主动丢掉不属于自己的责任。
位置信息同样不是事后粘贴的装饰。在 jlox 中,解析器发现右括号缺失时,扫描器其实已经完成整个文件的 tokenization 并抵达 EOF。让每个 token 自带位置,解析器才能直接指回相关 lexeme,而不必从 AST 反推源码偏移。结构与诊断能力是在同一条流水线上一起准备的。
到了这里,再谈理论才有用。Lox 的词法规则构成 regular language:一个有限状态过程,加上很少量的 lookahead,就足以识别所有 lexeme。因此手写扫描器可以单向穿过源码,不需要构造树,也不需要记住任意深度的嵌套。括号可以无限嵌套,但扫描器只负责认出单个 ( 与 );匹配哪一对括号,是解析器的工作。
扫描结束后,开头那一行变成:
PRINT NUMBER(1) MINUS NUMBER(2) STAR NUMBER(3)
LESS NUMBER(4) EQUAL_EQUAL FALSE SEMICOLON EOF边界已经确定,列表也比原始字符串丰富得多,但它仍然是平的。列表里没有任何信息说明 STAR 应该拥有左右两个数字。
词法分析消除了一类不确定性,同时暴露出下一类:同一串 token,仍然可能对应不止一棵树。
3. 同一串 token,桌面上却摆着两个程序
把开头一行缩到算术核心:
1 - 2 * 3无论应该怎样求值,扫描器给出的五个有效 token 都完全相同:
NUMBER(1) MINUS NUMBER(2) STAR NUMBER(3)现在可以画出两棵候选树。
第一棵树把减法放在乘法下面:
*
/ \
- 3
/ \
1 2它表达的是 (1 - 2) * 3,结果为 -3。
第二棵树把乘法放在减法右侧:
-
/ \
1 *
/ \
2 3它表达的是 1 - (2 * 3),结果为 -5。
两棵树都恰好消费每个 token 一次。如果我们只知道“二元表达式由左操作数、操作符和右操作数组成”,两者都说得通。差别不在词汇,而在归属关系:谁是谁的子节点,哪个子表达式先闭合。
这就是最有用的 grammar ambiguity:一个输入允许多个合法结构解释,而不同结构会产生不同运行结果。因此,解析器的任务不只是判断 token 序列是否合法。它还必须按照 Lox 的优先级与结合性,选出唯一一棵树。
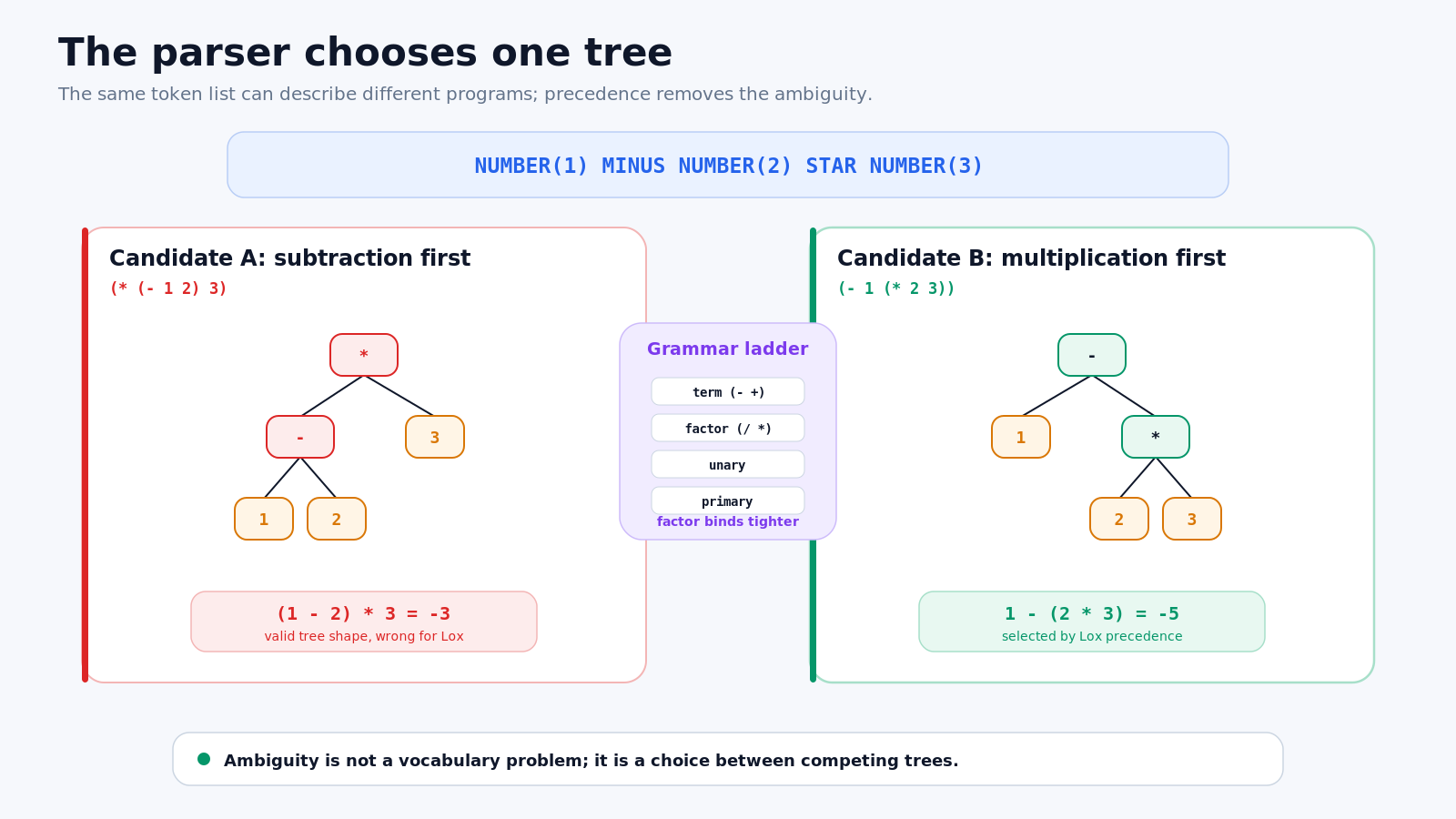
图 3:当两棵树给出不同结果时,歧义不再抽象。Lox 选择先乘后减。
**Precedence(优先级)**决定不同操作符混合出现时,哪一种绑定得更紧。* 的优先级高于 -,所以乘法子树必须在减法表达式内部形成。
**Associativity(结合性)**决定同一优先级的操作符连续出现时如何分组。Lox 的算术、比较和相等操作符是左结合的,因此 10 - 3 - 2 等价于 (10 - 3) - 2。一元操作符是右结合的,因此 !!false 从右侧嵌套。
扫描器无法替解析器做这些决定,也不应该做。它不知道 - 的右侧是否正在等待一个完整 factor,更不应让词法边界依赖周围语法上下文。否则,两个本来边界清晰的阶段会纠缠在一起。
解析器需要一套新的 grammar:它的形状本身,应当让正确的树比错误的树更容易被构造出来。
4. Grammar 把优先级变成树形
Lox 通过把表达式拆成一条优先级阶梯来消除歧义。由低到高,当前需要的规则是:
expression → equality ;
equality → comparison ( ( "!=" | "==" ) comparison )* ;
comparison → term ( ( ">" | ">=" | "<" | "<=" ) term )* ;
term → factor ( ( "-" | "+" ) factor )* ;
factor → unary ( ( "/" | "*" ) unary )* ;
unary → ( "!" | "-" ) unary | primary ;
primary → NUMBER | STRING | "true" | "false" | "nil"
| "(" expression ")" ;关键关系是:低优先级规则会调用下一层更紧的规则来解析每个操作数。term() 在 - 两侧并不解析任意 expression,而是要求 factor() 返回完整操作数;factor() 又要求 unary()。因此,乘法有机会在控制权返回减法层之前先闭合。
Recursive descent(递归下降)几乎逐字把 grammar 翻译成方法。term() 与 factor() 的形状高度相似:
private Expr term() {
Expr expr = factor();
while (match(MINUS, PLUS)) {
Token operator = previous();
Expr right = factor();
expr = new Expr.Binary(expr, operator, right);
}
return expr;
}
private Expr factor() {
Expr expr = unary();
while (match(SLASH, STAR)) {
Token operator = previous();
Expr right = unary();
expr = new Expr.Binary(expr, operator, right);
}
return expr;
}这里采用循环,不只是编码风格。乘法规则也可以自然地写成 factor → factor ("/" | "*") unary | unary,但它是 left-recursive:factor() 一进入就会在尚未消费任何 token 时再次调用 factor(),随后无限递归。改写成“先解析一个 unary,再重复零次或多次操作符与操作数”后,接受的表达式语言没有变化,但解析器每次循环前都保证已经取得进展。
这是编译器实现里很重要的一条判断:grammar 描述语言,但同一个语言可以有多种等价 grammar;不同解析策略对 grammar 形状有不同要求。去除左递归并没有改变 Lox 的语义,只是选择了一种能自然映射到递归下降控制流的写法。
循环还承担第二项工作:构造左结合结构。每发现一个新操作符,新的 Binary 都把当前已经累积的树 expr 放在左侧:
1 - 2 - 3
第一次:Binary(1, -, 2)
第二次:Binary(previousTree, -, 3)
结果: ((1 - 2) - 3)现在只追踪 1 - 2 * 3 所需的调用。
expression() 调用 equality(),后者调用 comparison(),再进入 term()。term() 下的第一个 factor() 解析 primary literal 1 并返回。term() 看到 -,消费操作符,然后要求另一个 factor() 提供右操作数。
第二个 factor() 先解析 2,随后看到 *。因为 * 属于 factor 层,factor() 消费它,再解析 3,立刻构造:
Binary(Literal(2), STAR, Literal(3))只有当这棵子树完整形成后,factor() 才返回 term()。减法层收到的右操作数已经不是单独的 2,而是整棵乘法树,于是它构造:
Binary(Literal(1), MINUS, Binary(2, STAR, 3))这就是决定性时刻。不是扫描器“赋予乘法优先权”,而是 term() 与 factor() 之间的调用关系表达了优先级,解析器则通过先分配乘法节点,把规则变成了具体结构。
继续处理开头完整表达式,最终层级为:
PrintStmt
└── Binary ==
├── Binary <
│ ├── Binary -
│ │ ├── Literal 1
│ │ └── Binary *
│ │ ├── Literal 2
│ │ └── Literal 3
│ └── Literal 4
└── Literal false乘法位于最深处;减法包住乘法;比较再包住减法;相等判断成为最外层 expression。print 是 expression 外的 statement 壳。书中在表达式解析之后不久才正式加入 statement 解析,但这不会改变壳内的优先级故事。
递归下降经常被当作一个算法名来记。更有用的视角是把它看成状态轨迹:每个正在工作的 grammar rule 都对应 Java 调用栈上的一个 frame;向下调用,是把一个更小、更紧的问题交给下一层;方法返回,是把已经完成的子树交还给调用者。调用栈暂时保存“解析器正在什么地方”,AST 则保存最终、持久的决定。
解析器已经选定一棵树。后续阶段需要的是这次选择的稳定表示,而不是重新播放解析器的调用栈。
5. AST 成为阶段之间的交接面
解析结束后,解析器的调用栈会消失;刚才选定的结构不能随之消失。负责把它持久化的表示就是 abstract syntax tree,简称 AST。
“Abstract” 很重要。完整 parse tree 可以保留每一次 grammar production 和每个标点 token;AST 只保留后续阶段真正需要的差异,丢掉识别过程中使用的大量脚手架。这篇文章涉及的 expression 子集,主要由四类节点承载:
Literal:保存1、"hello"、false这样的原子内容;Unary:保存一个操作符 token 和一个操作数;Binary:保存左 expression、操作符 token、右 expression;Grouping:保存显式括号内部的 expression。
一个二元节点简单得近乎刻意:
static class Binary extends Expr {
Binary(Expr left, Token operator, Expr right) {
this.left = left;
this.operator = operator;
this.right = right;
}
final Expr left;
final Token operator;
final Expr right;
}这些字段直接暴露解析器的决定。left 与 right 不再只是 token 列表中相邻的元素,而是明确的子节点引用。操作符 token 被保留下来,因为后续阶段要根据其 type 选择行为,也可能用它的位置信息报告错误。
同样值得注意的是节点没有保存什么:它不保留扫描器的 start 与 current,不记录当初证明这棵树合理的优先级数字,也不指回创建它的 parser 方法。这些都只是构造期状态。树一旦存在,嵌套本身就是证据。正因为 AST 会选择性遗忘临时状态,它才是有用的中间表示,而不是解析器调用轨迹的序列化版本。
不同消费者需要的树也不同。Formatter 往往关心原始 token、空白和注释,因此会保留更丰富的 concrete syntax tree;解释器则更希望结构紧凑,让无关标点与 parser bookkeeping 不妨碍求值。不存在脱离用途的“唯一正确树”,但每一种树都应明确自己保留了哪些不变量。
括号最能说明 AST 保留什么、丢掉什么。单独的 ( 与 ) 不会作为叶节点继续存在,但它们造成的结构效果会留下来。jlox 用一个包含内部 expression 的 Grouping 节点保留这种效果;有些实现会在括号完成分组后直接返回内部节点。两种做法都说明同一件事:标点已经改变了归属关系,却不会自己变成运行时值。
AST 还解决了一个架构上的所有权问题。解析器创建树,但树并不只属于解析器。调试打印器要展示嵌套;解释器要执行节点;后续的 resolver 要遍历变量表达式并记录 lexical distance;如果是静态类型语言,type checker 也需要再走一遍。
若把这些操作都塞进节点类,多个阶段会混在一起。jlox 使用 Visitor pattern:每个节点只负责把访问分派到正确方法,每一种操作则独立存在于自己的 visitor 类中。节点保持为有类型的数据模型,行为由不同 pass 提供。
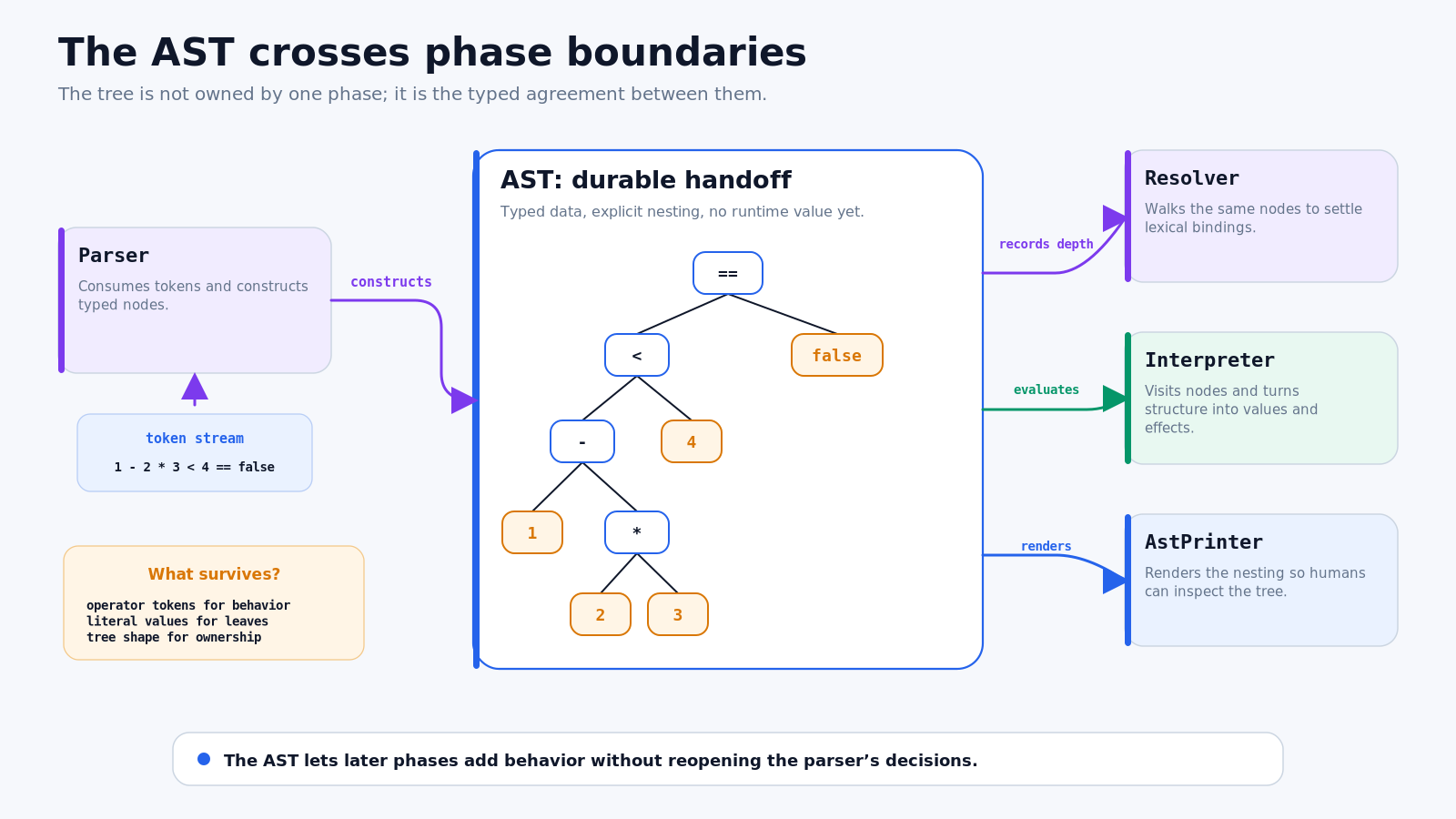
图 4:AST 是一份持久协议。解析器只决定一次结构,后续 pass 各自消费同一棵树。
这正是交接面的价值。解释器无需再次询问 2 * 3 是否应该先于减法,它收到的就是一个 Binary(MINUS),其右子节点已经是 Binary(STAR)。Resolver 不需要重新切分源码;打印器不需要根据优先级重新推测嵌套。一个阶段支付了消除歧义的成本,所有后续阶段复用结果。
Visitor 有时被解释成一个孤立的设计模式条目,这里可以看见它的因果来源:在某个阶段内,syntax node 的种类相对稳定,而“要对节点做什么”会不断增加。我们希望加入新遍历时,不必重新打开每个节点类。Visitor 把“当前执行哪一种操作”和“当前是哪一种节点”分成两条独立轴线。
这份干净交接默认解析器能够回到已知状态;真实用户却会输入不完整、错误甚至只写了一半的程序。
6. 有用的解析器,必须能从坏输入里活下来
看一个缺失右括号、但后面仍有合法语句的例子:
print (1 + 2;
print 99;解析 grouping expression 时,解析器顺利读完 1 + 2,随后调用 consume(RIGHT_PAREN, ...)。眼前 token 却是分号,当前 production 无法完成。
一个脆弱的解析器往往走向两个极端:要么直接崩溃,把实现异常暴露给用户;要么带着已经错乱的状态继续调用 grammar 方法,制造一连串误导性错误。jlox 选择 panic-mode recovery:准确报告第一个错误,放弃损坏的 production,移动到一个可能的边界,再从那里恢复。
局部控制流依靠一个很小的 ParseError 异常。抛出它,会展开那些代表未完成 primary()、unary()、factor()、term() 以及外层 statement 的递归下降调用帧。等异常在 statement 或 declaration 边界被捕获时,解析器已经回到一个可以重新开始语句的规则层级。
但 token 流也要重新对齐。Synchronization 会丢弃输入,直到看到边界迹象:
private void synchronize() {
advance();
while (!isAtEnd()) {
if (previous().type == SEMICOLON) return;
switch (peek().type) {
case CLASS: case FUN: case VAR: case FOR:
case IF: case WHILE: case PRINT: case RETURN:
return;
}
advance();
}
}这个方法刻意采用启发式判断。分号“很可能”结束了坏语句;print、var、if 等关键字“很可能”开始下一条语句。这里“很可能”已经足够,因为错误恢复本来就是 best effort:最初那个错误已经在违反期待的 token 处被精确报告。
在示例中,解析器已经消费坏语句中的 1 + 2,看到 ; 时报告“Expect ’)’ after expression.”。恢复逻辑消费这个分号,识别出语句边界,并把第二个 print 留给正常解析。于是一次运行既能诊断第一条坏语句,又不会牺牲文件剩余部分。
第 6 章加入恢复机制时,解析器还只处理一个 expression,因此当时几乎没有后续内容可恢复。等 statement 被解析成序列,同一套机制才真正显出价值:在 declaration 边界捕获异常,同步 token,然后继续。
还要保持两个边界清晰。
第一,panic mode 属于 parser。像 @ 这样的非法字符属于 scanner error。扫描器会消费它、报告它、继续扫描,但不会抛 ParseError,也不会根据 statement 关键字做同步。
第二,继续解析不等于执行坏代码。语法错误会把 hadError 设为真。前端可以继续收集更多诊断,但解释器不会运行受损程序。Recovery 改善的是反馈质量,不是把无效 AST 假装成安全输入。
好的恢复策略并不要求完美重建用户意图,那是更困难的问题。它只需要限制破坏半径:一处坏区域不应摧毁整个 parse session,更不应凭空制造几十条级联错误。
现在,即使输入有缺陷,错误也会被控制在有限范围内。我们可以回到故事开头的那行代码。
7. 这一行终于成为了程序
把开头一行重新放在三种表示中观察。
Source text
print 1 - 2 * 3 < 4 == false;它保留拼写和字符顺序,却没有边界与层级。
Token sequence
PRINT NUMBER(1) MINUS NUMBER(2) STAR NUMBER(3)
LESS NUMBER(4) EQUAL_EQUAL FALSE SEMICOLON EOF它保留边界、token 类型、部分 literal payload 与位置,但仍然平铺。
AST
PrintStmt(
Binary(
Binary(
Binary(1, -, Binary(2, *, 3)),
<,
4),
==,
false))它保存了解析器选定的归属关系。开头的问题终于可以得到精确答案:
factor()grammar layer 先构造Binary(2, STAR, 3),随后term()才能完成减法节点。
就是这个时刻,2 * 3 第一次被放进减法右侧。在此之前,各阶段只是在准备证据:扫描器保证 2、*、3 是边界正确、类型正确的 token;优先级 grammar 限定可接受的嵌套;递归下降把规则关系变成方法调用;AST 则在调用结束后保留结果。
此时还没有输出,也没有运行时副作用。AST 已经包含求值顺序,却尚未求出任何值。Literal(2) 是“能够产生值 2 的语法”,而不是已经在解释器中流动的 runtime value。整行代码已经变成可执行结构,但仍悬停在执行前一刻。
Source map
本篇以书为第一手来源:
- 第 2 章 “A Map of the Territory”:从 source code 经 scanning、parsing 进入前端的整体路径;
- 第 4 章 “Scanning”:
Scanner.java、Token.java、TokenType.java、scanTokens()、match()、peek()、peekNext()、maximal munch 与 literal conversion; - 第 5 章 “Representing Code”:
Expr.java、GenerateAst.java、AstPrinter.java、AST 节点族与 Visitor pattern; - 第 6 章 “Parsing Expressions”:ambiguity、优先级阶梯、recursive descent、
ParseError、panic mode 与 synchronization。
推荐从以下实现入口继续阅读:
java/com/craftinginterpreters/lox/Scanner.javajava/com/craftinginterpreters/lox/Parser.javajava/com/craftinginterpreters/lox/Expr.javajava/com/craftinginterpreters/lox/AstPrinter.java
这篇文章在呈现节奏上参考了 Luna Shi 的 source-dive 系列:从一个具体失效的浅层心智模型出发,换成更准确的模型,再沿精确实现状态推进。这篇文章论证、例子、图与文字均为本篇原创。
通往 Episode II
树已经准备好,却仍然静止。第二篇从解释器访问第一个叶节点开始:它把 Literal(1) 从语法转换成 runtime value,并让值沿着解析器刚刚构造的结构向上流动。