Codex 源码阅读(VI):上下文工程
Codex 源码讲解(六):Context Engineering
AGENTS.md、Skills 和 Compaction 如何组成模型真正的工作上下文。
一种很常见但很危险的理解是:Codex 只是“把 repo 内容塞进 prompt”。
这个说法太粗,也解释不了 Codex 真正在做的事。Codex 的上下文不是一条越来越长的大字符串,而是一组运行时结构:项目规则有作用域,Skills 有触发条件,线程历史有账本,Compaction 有替换语义,初始上下文在基线变化后还能重新注入。
这个差别只有在任务变长之后才会真正显现。
想象一个真实请求:
“Fix the checkout timeout, keep the payments migration rules intact, run the failing test, and continue from the work we already did above.”
这不是一次性 prompt 能解决的问题。Codex 需要知道 services/payments 目录有本地规则;需要记住用户刚刚纠正过 staging feature flag;需要读日志、跑命令、调用工具,也可能要加载某个专门的 skill;还要在长对话快要超过上下文窗口时继续往下做。如果只是把所有内容硬塞进 prompt,系统要么忘掉关键规则,要么被旧工具输出挤爆,要么在最需要继续时把当前任务压缩没了。
Codex 的 context engineering,就是为了让这种任务能活下来。
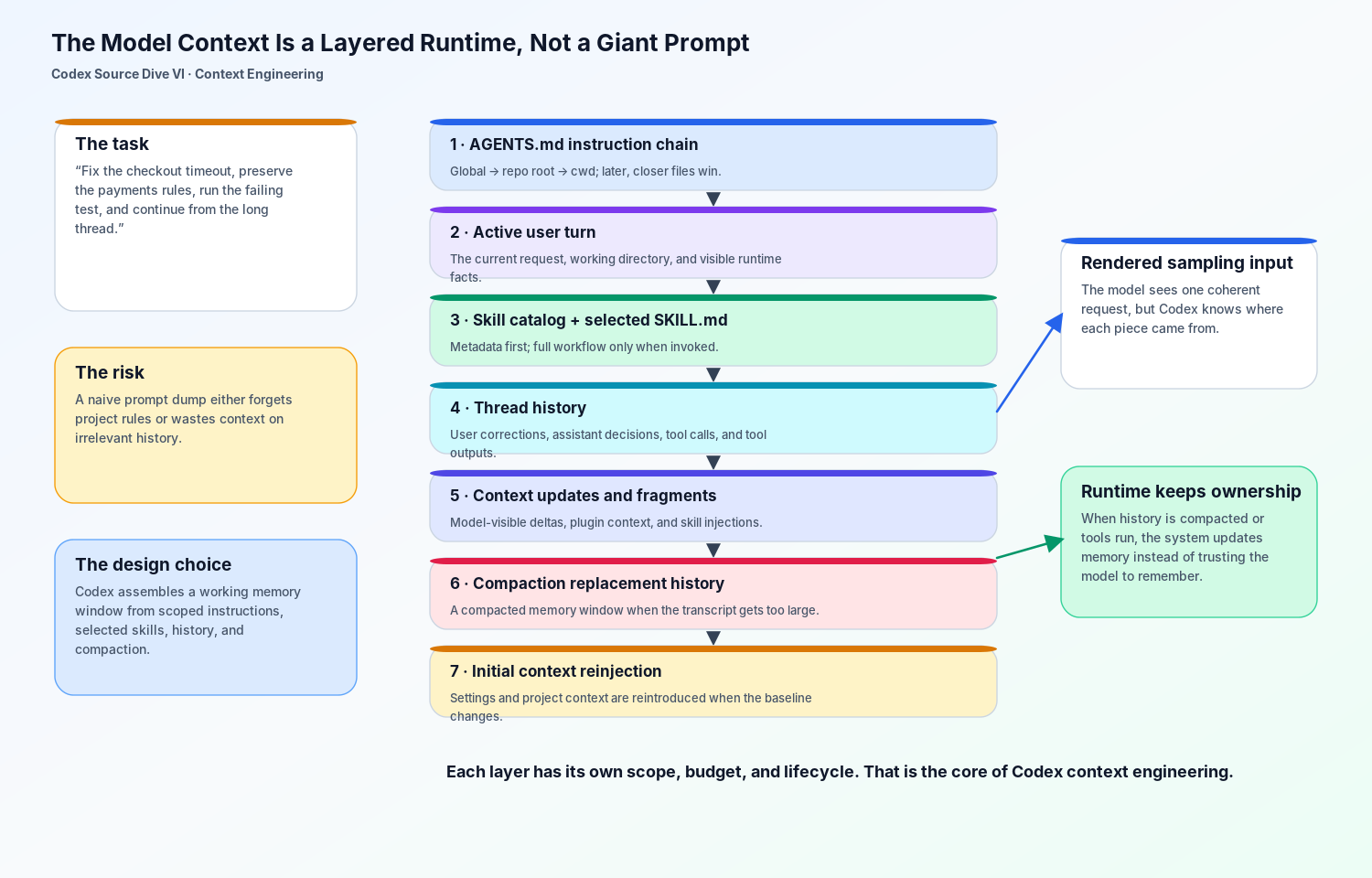
1. 故事在模型开口之前就开始了
checkout bug 发生在 services/payments。在模型输出第一条命令之前,Codex 已经先组装了一条项目指令链。
这不是“顺手读几个文档”的习惯,而是有明确作用域的机制。Codex 会在工作前读取 AGENTS.md。它先读 Codex home 里的全局规则,再从项目根目录一路走到当前工作目录。越靠近当前目录的指令越晚进入合并结果,因此可以覆盖更上层、更宽泛的规则。
对 payments 任务来说,这条链可能长这样:
~/.codex/AGENTS.md
repo/AGENTS.md
repo/services/AGENTS.md
repo/services/payments/AGENTS.override.md全局文件可以说“尽量小 diff,结束时汇报测试结果”;repo 根目录可以说“使用 pnpm,不要编辑生成文件”;payments 目录可以说“跑 make test-payments,不要轮换 staging keys”。最后进入模型上下文的不是一团无法区分来源的规则,而是一条有层级、有优先级的 instruction spine。
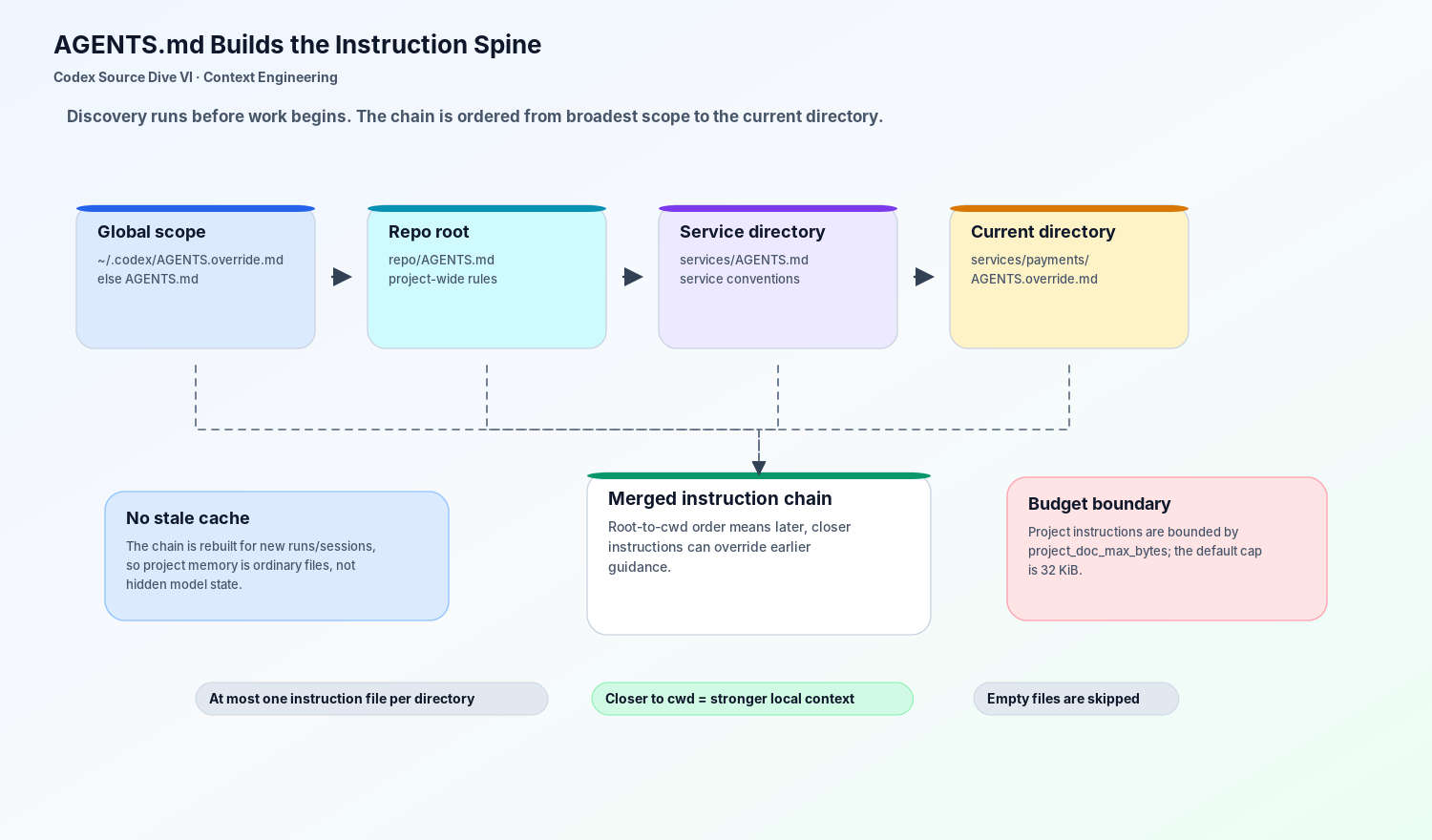
这里有两个细节值得单独拎出来。
第一,Codex 在每个目录最多选择一个指令文件。它会优先看 override 文件,再看标准 AGENTS.md,最后才看配置里的 fallback 名称。这样每个目录只有一个清晰的规则入口,不会出现同一层多个文件互相打架。
第二,项目指令会受到 project_doc_max_bytes 限制,默认上限是 32 KiB。这不是无关紧要的保护。它意味着 Codex 不会允许“项目记忆”无限吞掉模型上下文。如果团队把 AGENTS.md 写成一本书,Codex 会把它当成上下文预算问题,而不是免费的长期记忆。
最重要的是:项目记忆仍然是外部、可编辑、可审查的文件。新 session 或新 run 开始时,指令链会重新从文件构建,而不是藏在某种无法清理的模型记忆里。repo 规则仍是普通 repo 资产,只是被 Codex 赋予了运行时语义。
2. Skills 不是常驻指令,而是等待触发的工作流
有了 AGENTS.md 之后,下一个诱惑是把所有有用流程都塞进 prompt:怎么 debug CI,怎么排查性能回归,怎么做 migration,怎么 review PR。短期看很方便,长期看 prompt 会变成杂物间。
Codex Skills 解决的是另一个问题。一个 skill 可以打包指令、资源和可选脚本,但 Codex 不会一开始就加载所有完整的 SKILL.md。它先给模型一个很小的目录:skill 的名字、描述和路径。只有当 Codex 判断某个 skill 相关时,完整内容才会被读取。
这就是 progressive disclosure。
在 checkout 任务里,Codex 一开始可能只知道存在一个 payments-migration skill,并且它适用于支付 schema 相关变更。如果用户显式调用它,或者当前任务匹配它的描述,Codex 才会加载完整工作流。在那之前,这个 skill 是“可发现的”,但不会占用大量上下文。
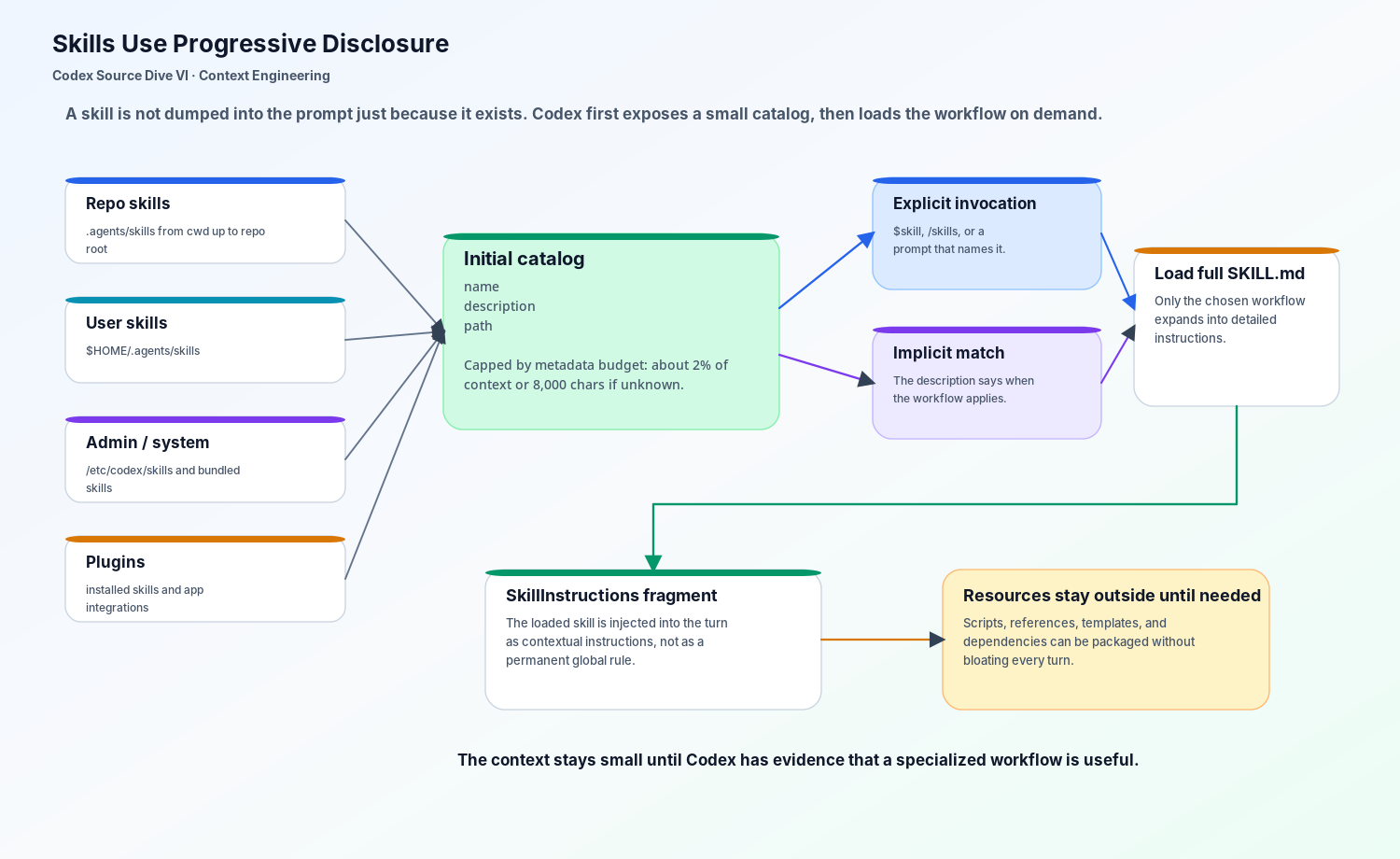
这是一个很明确的设计判断:专业知识应该先可发现,再按需加载。
源码路径也印证了这个判断。turn 构造阶段会先 build skills and plugins;用户输入里的显式 skill mention 会被收集;skill 描述也可以触发隐式调用。如果某个 skill 被选中,它的说明会作为 contextual user fragment 注入当前 turn。这说明 skill 不是全局政策,而是任务需要时才进入上下文的工作流。
预算约束同样重要。初始 skill 列表会被限制在模型上下文窗口的大约 2%,如果窗口未知则是 8,000 字符。这个限制迫使 skill description 写得足够短、足够准。skill 描述不是营销文案,而是路由元数据。
这也是为什么 AGENTS.md 和 Skills 不应该混用。
AGENTS.md 适合放长期项目规则:测试命令、代码风格、生成文件警告、本地约定、repo 特有的危险操作。Skills 适合放可复用流程:如何 debug GitHub Actions,如何做 release audit,如何安全迁移一个服务。把这两者混在一起,最后得到的不是更聪明的 agent,而是一堆永久指令。
3. Thread history 是运行时账本,不是聊天记录转储
Codex 开始工作后,上下文会不断变化。它读文件、跑测试、得到用户纠正、收到工具返回的 stack trace、改变下一步调查方向。这里面有些信息应该进入下一次采样,有些应该被归一化,有些最终应该被压缩。
这就是 thread history 的意义。
源码里的 context manager 保存了 conversation items、token 信息、history version,以及一个 reference context item。最后这个字段很容易被忽略。它是模型可见 context updates 的 diff 基线。如果 Codex 能和上一次基线做 diff,就可以发送增量;如果基线不存在,下一次 regular turn 就可以触发更完整的上下文重新注入。
换句话说,history 不是“上方聊天记录”。它是运行时账本。
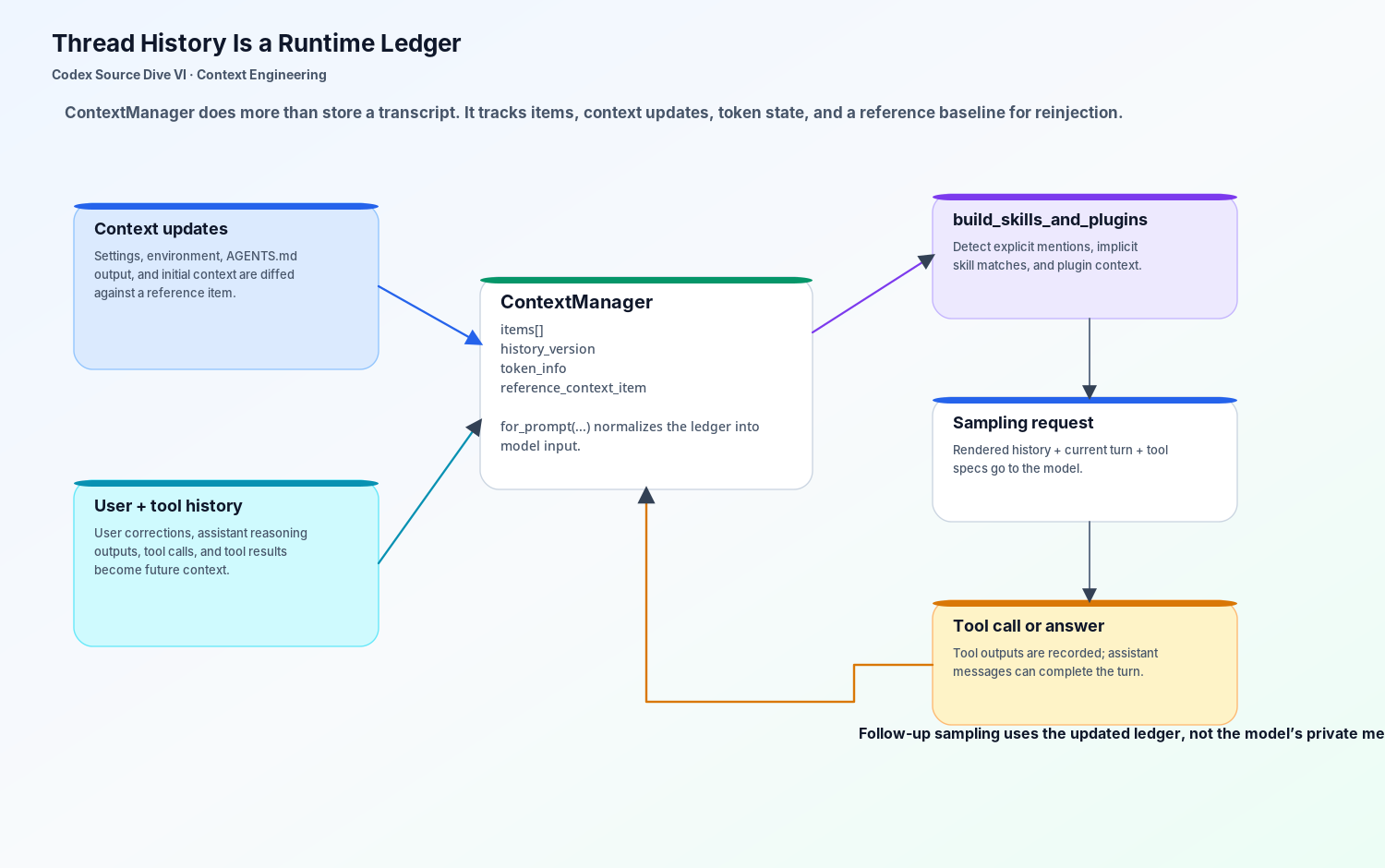
在一个工具密集型任务里,这个账本能让 Codex 不丢线索。假设第一次测试因为 timeout 失败。Codex 读 adapter,跑更窄的测试,得到另一个错误。用户说:“Use the staging flag; the local flag is misleading.” 这个纠正会变成未来上下文。下一次工具调用不是单纯依赖模型对这句话的私人记忆,而是依赖运行时管理的 history items。
run_turn 循环会继续采样和执行。如果模型请求工具调用,Codex 会执行工具并记录结果;如果模型返回 assistant message,并且没有 pending work,turn 才能结束。在这些步骤之间,prompt 会从受管理的 history、当前 turn 状态、工具 specs、skill injections 和 context updates 里重新构建。
这也是为什么 context engineering 和 tool runtime 不能分开看。一个工具结果如果没有进入受管理的 history,就只是一次观察;如果它以正确位置进入 history,就变成了 agent 的工作记忆。
4. Compaction 不是“写个更好的总结”,而是替换上下文窗口
长时间 agent 工作里,真正难的不是写总结,而是决定这个总结替换什么。
官方 API compaction 的语义非常明确:compaction 是为了在缩小上下文的同时保留后续 turn 所需的状态。server-side compaction 可以产生一个 compaction item,并通过 response chaining 继续携带;standalone compaction 会返回一个新的 compacted context window,后续应该把它当作 canonical context。
Codex 本地 compaction 的思想也是一样的:目标不是在聊天记录末尾追加一段“Summary”,而是构建一个 replacement history。
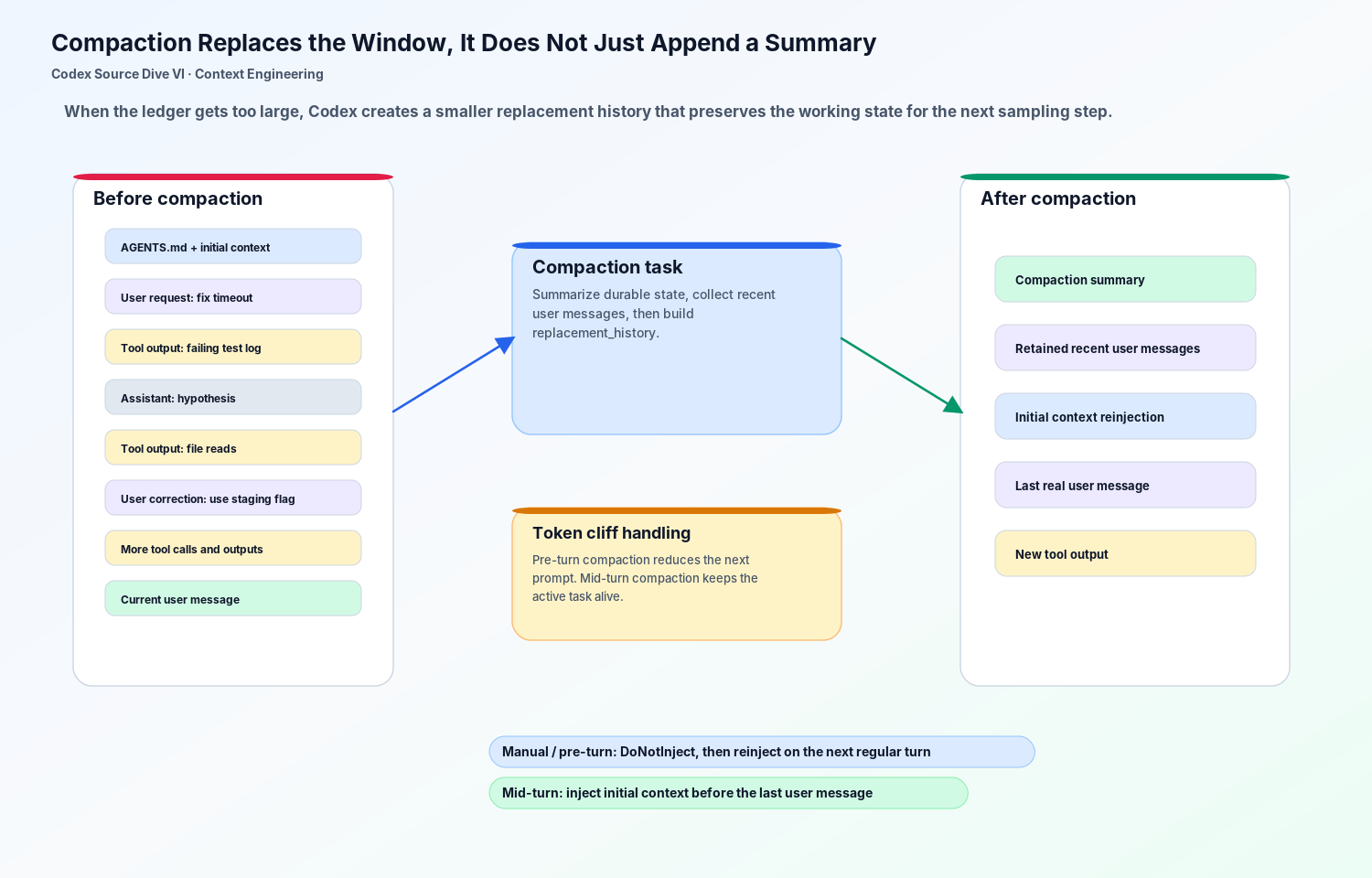
一个很长的 payments debugging 线程可能包含几千行工具输出。绝大多数内容都不应该原样保留。真正需要保留的是 durable state:
- bug 在 timeout adapter,而不是 retry scheduler;
- 用户纠正过 staging feature flag;
make test-payments TEST=checkout_timeout是窄验证命令;- 生成的 SDK 文件不能编辑;
- 上一次 patch 改了 adapter,但还没有通过完整 service test。
Compaction 要保留这些状态,同时丢掉高 token 噪音。
源码里有两个 placement 规则尤其重要。
对于 manual 或 pre-turn compaction,Codex 可以用 summary 替换历史,并且不立刻注入初始上下文。下一次 regular turn 会在需要时重新注入相关初始上下文。
对于 mid-turn compaction,Codex 不能等到下一轮。当前任务还在执行中。如果模型刚刚产生工具调用,而且还需要 follow-up sampling,runtime 可能会在 turn 中间压缩。此时初始上下文需要被插入到最后一个真实用户消息之前,这样模型仍然能在正确位置看到当前请求。
这个细节很小,却正好说明 compaction 必须属于 runtime。模型可以写总结,但 runtime 决定总结如何变成 history。
5. 长任务能继续,是因为上下文有生命周期
回到 checkout bug。
模型已经读了 adapter,打了一个小 patch,跑了窄测试,收到失败结果,现在需要继续检查 fixture。token 使用量接近可用上限。一个简单 agent 可能会失败、盲目截断,或者让用户重新开始。Codex 还有另一种选择:压缩当前工作记忆,然后继续这个 turn。
生命周期大致是这样:
AGENTS.md chain
↓
skill catalog and selected skills
↓
thread history + tool results
↓
pre-sampling or mid-turn compaction
↓
replacement_history + initial context reinjection
↓
next sampling request这里最要紧的词是 “next sampling request”。上下文系统不是只准备第一条 prompt,而是在循环里不断准备每一次 prompt。
这也解释了为什么 AGENTS.md、Skills 和 Compaction 应该放在同一篇里讲。它们解决的是同一个 runtime 问题的不同失败模式:
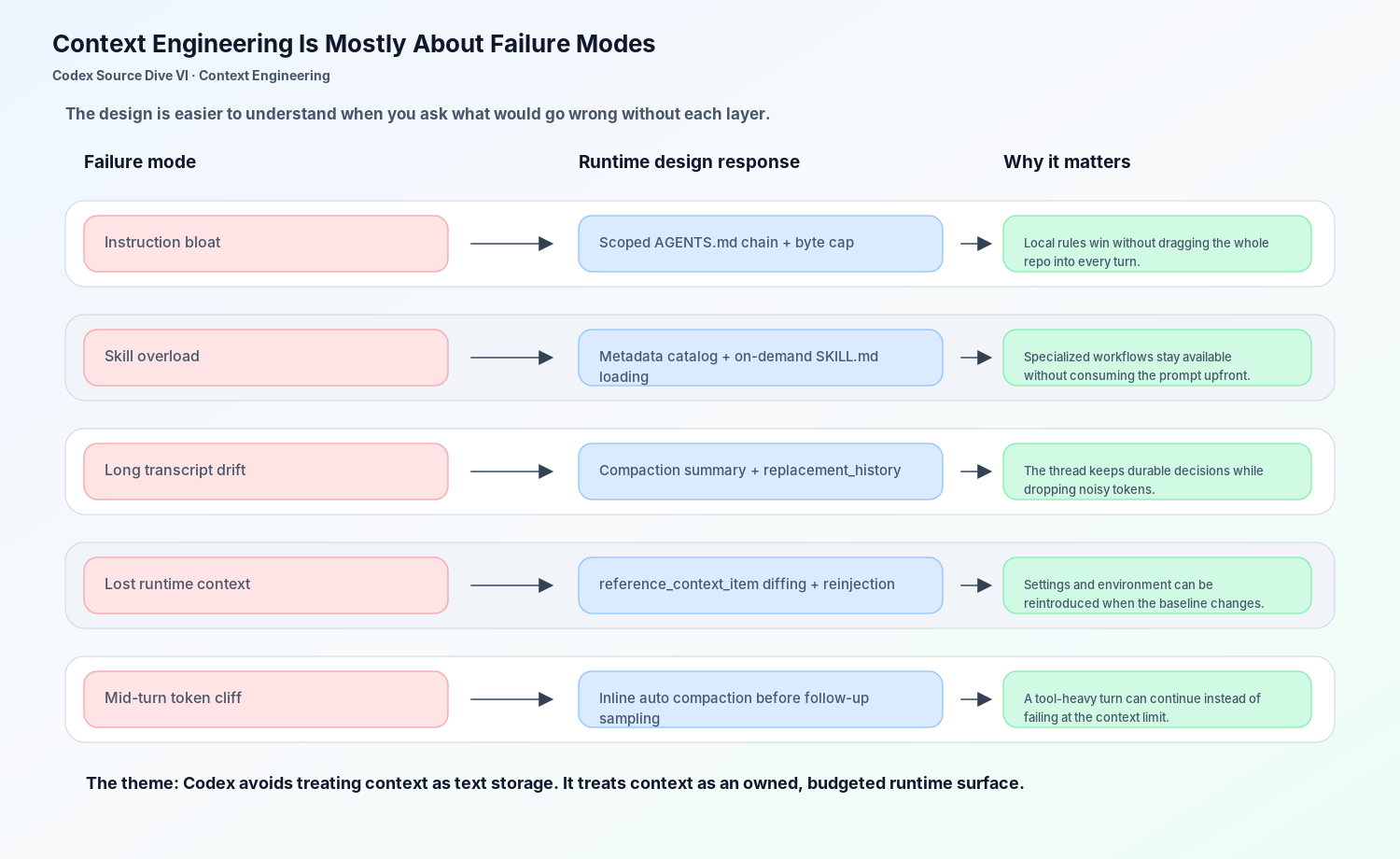
AGENTS.md 防止本地项目规则被忘掉。Skills 防止专业工作流变成永久 prompt bloat。Thread history 把工具观察和用户纠正变成持久状态。Compaction 防止长任务被自己的 transcript 压垮。Initial context reinjection 防止压缩后或基线变化后丢失模型仍然需要的 runtime facts。
这些机制单独看都不惊艳。放在一起,才组成模型真正的工作上下文。
6. 对 agent 工程的启发
关于 agent 设计,最常见的建议是“给模型正确上下文”。这句话没错,但太空。
Codex 给出的版本更锋利:
上下文应该有归属。 项目规则属于文件,skill metadata 属于 skill index,工具输出属于 thread history,摘要属于 compaction item,runtime settings 属于 context updates。
上下文应该有作用域。 全局指令不应该假装成本地指令;repo-root 规则不应该无条件覆盖 payments 目录的例外;release-audit workflow 不应该进入每一个 coding turn。
上下文应该有预算。 系统应该限制项目文档、限制 skill metadata、归一化 history、压缩长 transcript,而不是假设 prompt 越大行为越好。
上下文应该有生命周期。 有些上下文在 turn 之前加载,有些在 turn 中被发现,有些在工具结果之后被记录,有些会被总结并替换旧历史,有些只有在基线变化后才重新注入。
更深的教训是:context engineering 不是“拿一个更大的剪贴板做 prompt engineering”。它是一个 agent 在读取、行动、被纠正、继续执行过程中的状态管理。
当 Codex 修 checkout timeout 时,真正值得注意的不是它能不能编辑一个文件,而是模型能不能在一个由 runtime 组装、分层、限额、压缩、恢复的上下文窗口里持续工作。
这才是真正的上下文。