Codex Source Dive (VI): Context Engineering
Codex Source Dive (VI): Context Engineering
How AGENTS.md, Skills, and Compaction build the model’s real working context.
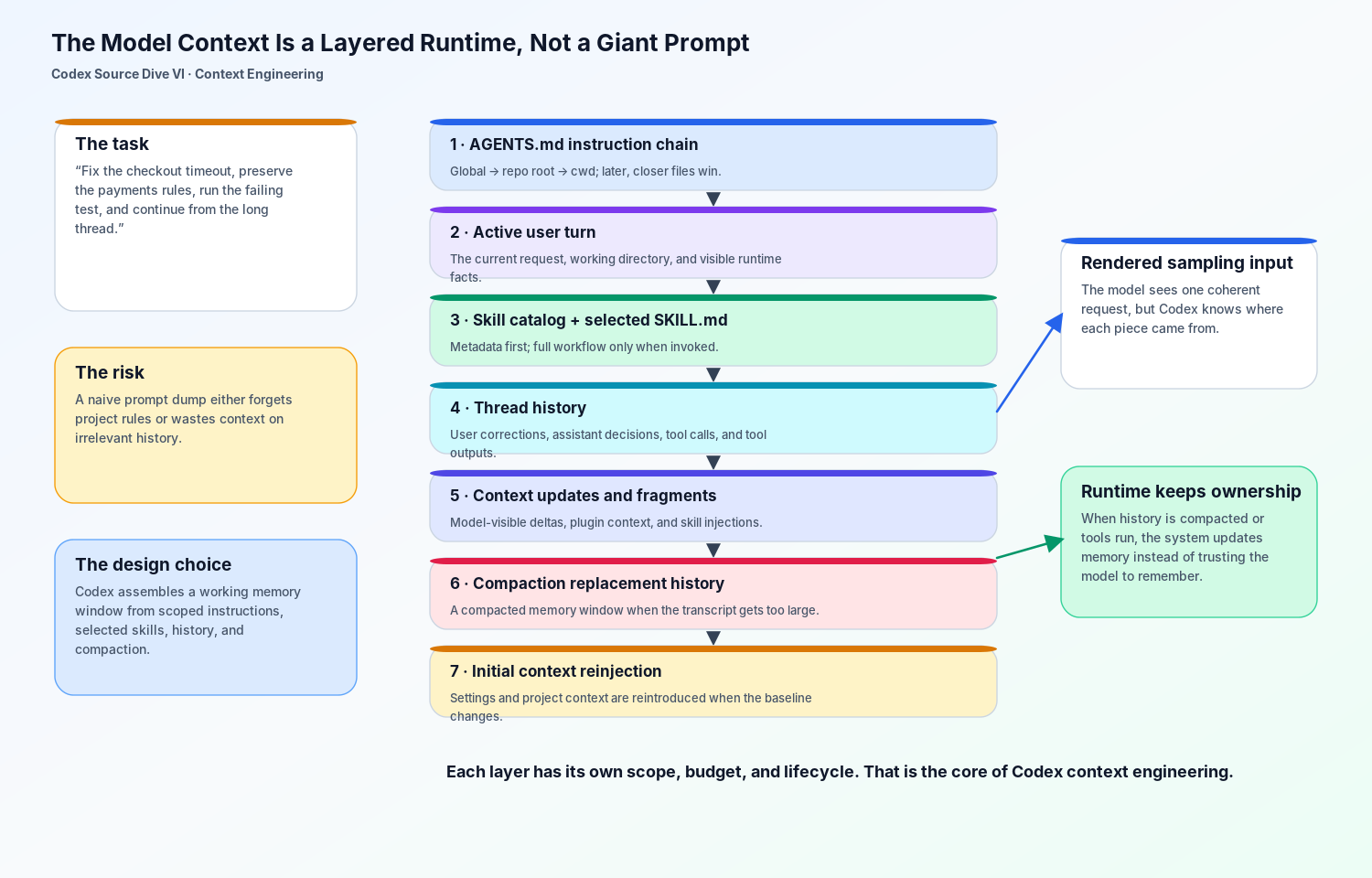
TLDR: Codex does not simply shove a repository into the prompt. It gives context separate owners, budgets, scopes, and replacement rules, so project instructions, skills, thread history, compaction, and runtime settings can keep a long-running task coherent.
A tempting way to describe Codex is to say that it “puts the repo into the prompt.” That is also the fastest way to misunderstand it.
The more interesting design is almost the opposite. Codex does not treat context as a giant string. It treats context as a runtime surface: project instructions have scope, skills have activation rules, thread history has a ledger, compaction has replacement semantics, and initial context can be reinjected when the baseline changes.
That distinction matters when the task stops being a demo.
Imagine a real request:
“Fix the checkout timeout, keep the payments migration rules intact, run the failing test, and continue from the work we already did above.”
This is not a one-shot prompt problem. Codex has to remember that services/payments has local rules. It has to keep the user’s correction that staging uses a different feature flag. It has to read logs, run commands, call tools, perhaps invoke a skill, and then keep going after the thread becomes too long. If it simply stuffed everything into a single prompt, the system would either drop important rules, waste context on old tool output, or compact away the active task at exactly the wrong moment.
The point of Codex context engineering is to make that request survivable.
1. The story starts before the model speaks
The checkout bug begins inside services/payments. Before the model writes a command, Codex has already assembled a project instruction chain.
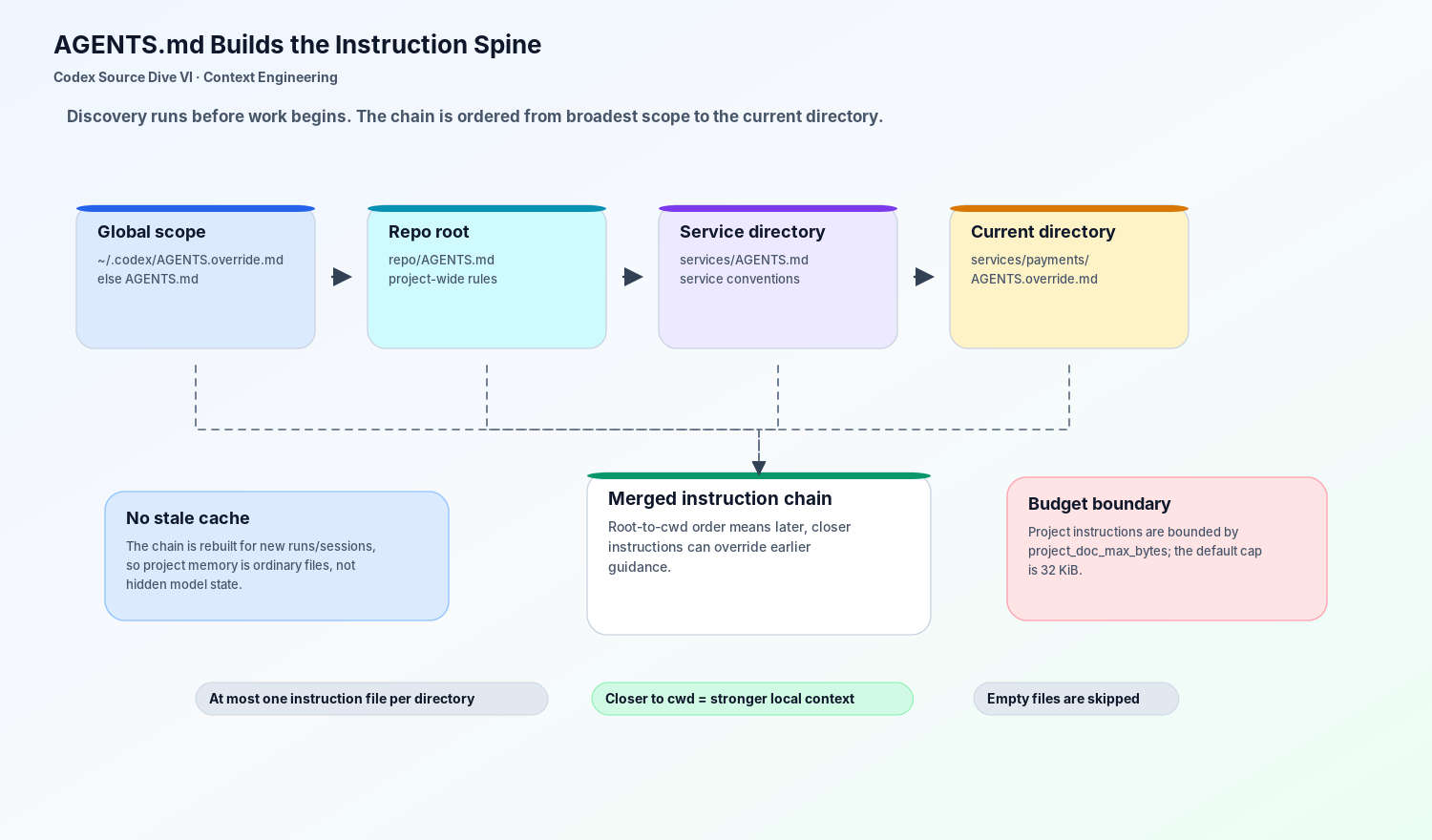
That chain is not a vague “read some docs” convention. The official behavior is scoped. Codex reads AGENTS.md before doing work. It starts with global guidance from the Codex home directory, then walks the project from the root down to the current working directory. The closer an instruction file is to the current directory, the later it appears in the merged chain, so it can override broader guidance.
For the payments task, the chain may look like this:
~/.codex/AGENTS.md
repo/AGENTS.md
repo/services/AGENTS.md
repo/services/payments/AGENTS.override.mdThe global file might say “prefer small diffs and always report tests.” The repo root might say “use pnpm and do not edit generated files.” The payments directory might say “run make test-payments and never rotate staging keys.” The final context is not one undifferentiated policy blob; it is a scoped instruction spine.
Two details make this design practical.
First, Codex chooses at most one instruction file per directory. It checks override files first, then standard AGENTS.md, then configured fallback names. This keeps each directory’s policy surface clear instead of letting several local files fight each other.
Second, project instructions are bounded by project_doc_max_bytes, whose default is 32 KiB. That cap is not cosmetic. It is a refusal to let “project memory” silently consume the whole model context. If a team writes a novel inside AGENTS.md, Codex treats that as a context budget problem, not as free memory.
The most important consequence is that project memory stays external and editable. When the session starts again, the instruction chain is rebuilt from files. There is no mysterious hidden memory to clear. The repo’s rules are ordinary repository artifacts with runtime semantics.
2. Skills are not instructions; they are latent workflows
After AGENTS.md, the next temptation is to dump every useful workflow into the prompt: how to debug CI, how to inspect a perf regression, how to write a migration, how to review a PR. That works until the prompt becomes a junk drawer.
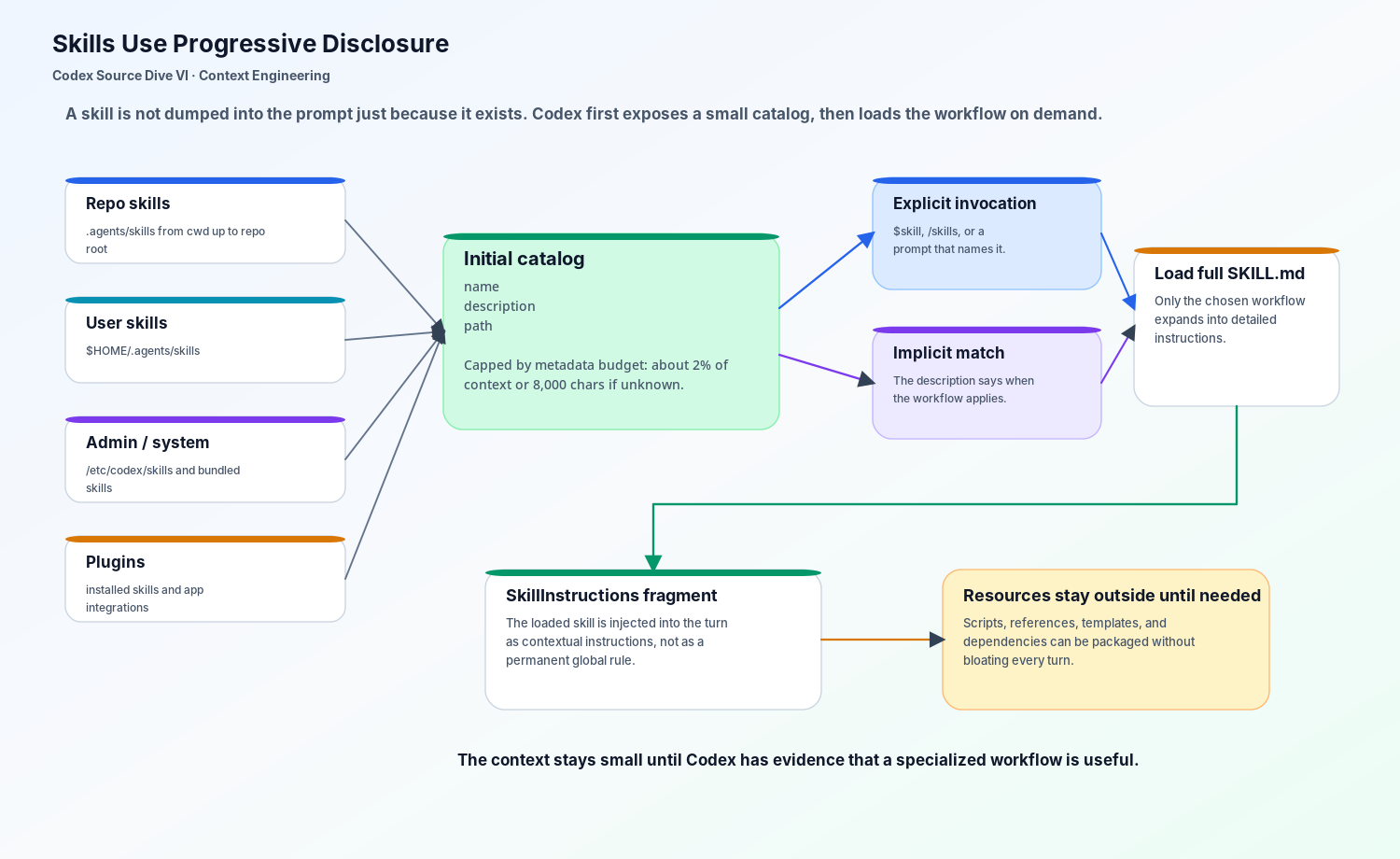
Codex Skills solve a different problem. A skill can package instructions, resources, and optional scripts, but Codex does not load every full SKILL.md upfront. It starts with a small catalog: name, description, and path. The full skill content is loaded only when Codex decides the skill is relevant.
That is progressive disclosure.
For the checkout task, Codex may initially know only that a payments-migration skill exists and that it applies to payment schema changes. If the user explicitly invokes it, or if the current request matches the skill description, Codex can load the full workflow. Until then, the skill is available but not bloating the prompt.
This is a strong design choice. It says: specialized knowledge should be discoverable before it is loaded.
The source shape reinforces that idea. The turn path builds skills and plugins before the sampling request. Explicit skill mentions are collected from the user’s input. Implicit invocation can be detected from skill descriptions. If a skill is selected, its instructions are injected as contextual user fragments for that turn. That means a skill is not the same thing as global policy. It is a workflow that enters the model context when the task earns it.
The budget rule is equally important. The initial skill list is capped at roughly 2% of the model context window, or 8,000 characters when the model window is unknown. That cap forces skill descriptions to be concise. A skill description is not marketing copy; it is routing metadata.
This is why skills and AGENTS.md should not be used for the same job.
AGENTS.md is for standing project rules: test commands, code style, generated-file warnings, local conventions, and repository-specific hazards. Skills are for reusable procedures: “how to debug a GitHub Actions failure,” “how to perform a release audit,” “how to migrate a service safely.” Confusing those two turns the context system into a pile of permanent instructions.
3. Thread history is a ledger, not a transcript dump
Once Codex starts working, context changes every few seconds. It reads files. It runs tests. The user corrects it. A tool returns a stack trace. The model decides to inspect a different module. Some of that should survive into the next sampling request, and some of it should be normalized or eventually compacted.
This is where thread history matters.
In the source, the context manager keeps a list of conversation items, token information, a history version, and a reference context item. That last field is easy to overlook. It is the baseline for model-visible context updates. If Codex can diff against a previous baseline, it can send deltas. If the baseline is missing, the next regular turn can force a fuller reinjection of context state.
In other words, history is not just “messages above the fold.” It is a runtime ledger.
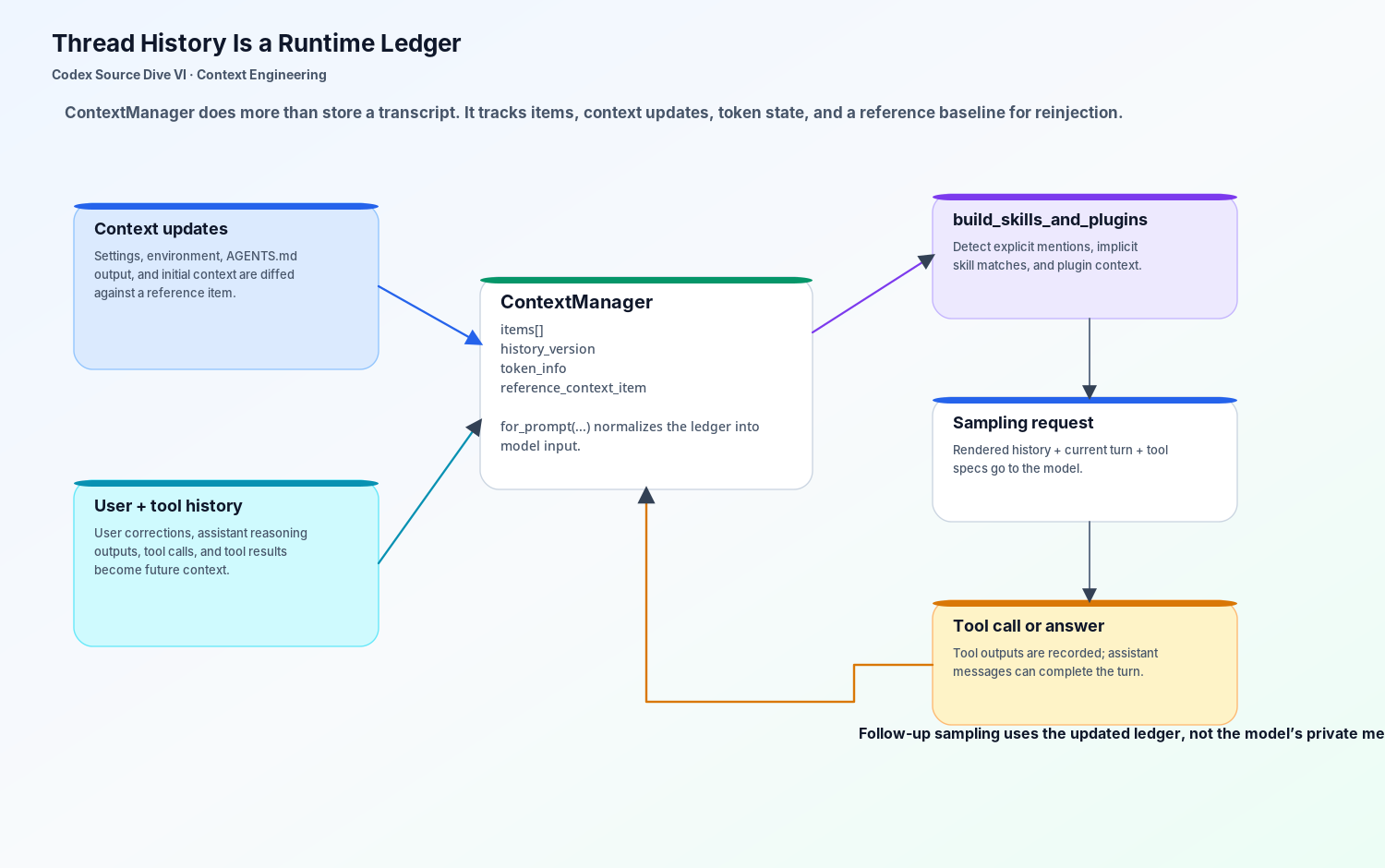
In a tool-heavy task, this ledger is what lets Codex keep its footing. Suppose the first test run fails with a timeout. Codex reads the adapter, runs a narrower test, gets a different error, and the user says, “Use the staging flag; the local flag is misleading.” That correction becomes future context. The next tool call is not based only on the model’s private memory of the sentence; it is based on rendered history items owned by the runtime.
The run_turn loop then keeps sampling and acting. When the model asks for a tool call, Codex executes the tool and records the result. If the model returns an assistant message and there is no pending work, the turn can finish. Between those points, the prompt is rebuilt from managed history, current turn state, tool specs, skill injections, and context updates.
That is why context engineering and tool runtime are inseparable. A tool result that does not become managed history is just an observation. A tool result that becomes a well-placed history item becomes part of the agent’s working memory.
4. Compaction is replacement, not a nicer summary
The hardest part of long-running agent work is not writing a summary. It is deciding what the summary replaces.
The official API compaction model makes this explicit: compaction reduces context size while preserving state for subsequent turns. Server-side compaction can produce a compaction item that is carried forward through response chaining. Standalone compaction returns a new compacted context window that should be used as the canonical next context.
Codex’s local compaction logic follows the same deeper idea. The goal is not to append a paragraph called “Summary” at the end of the transcript. The goal is to build a replacement history.
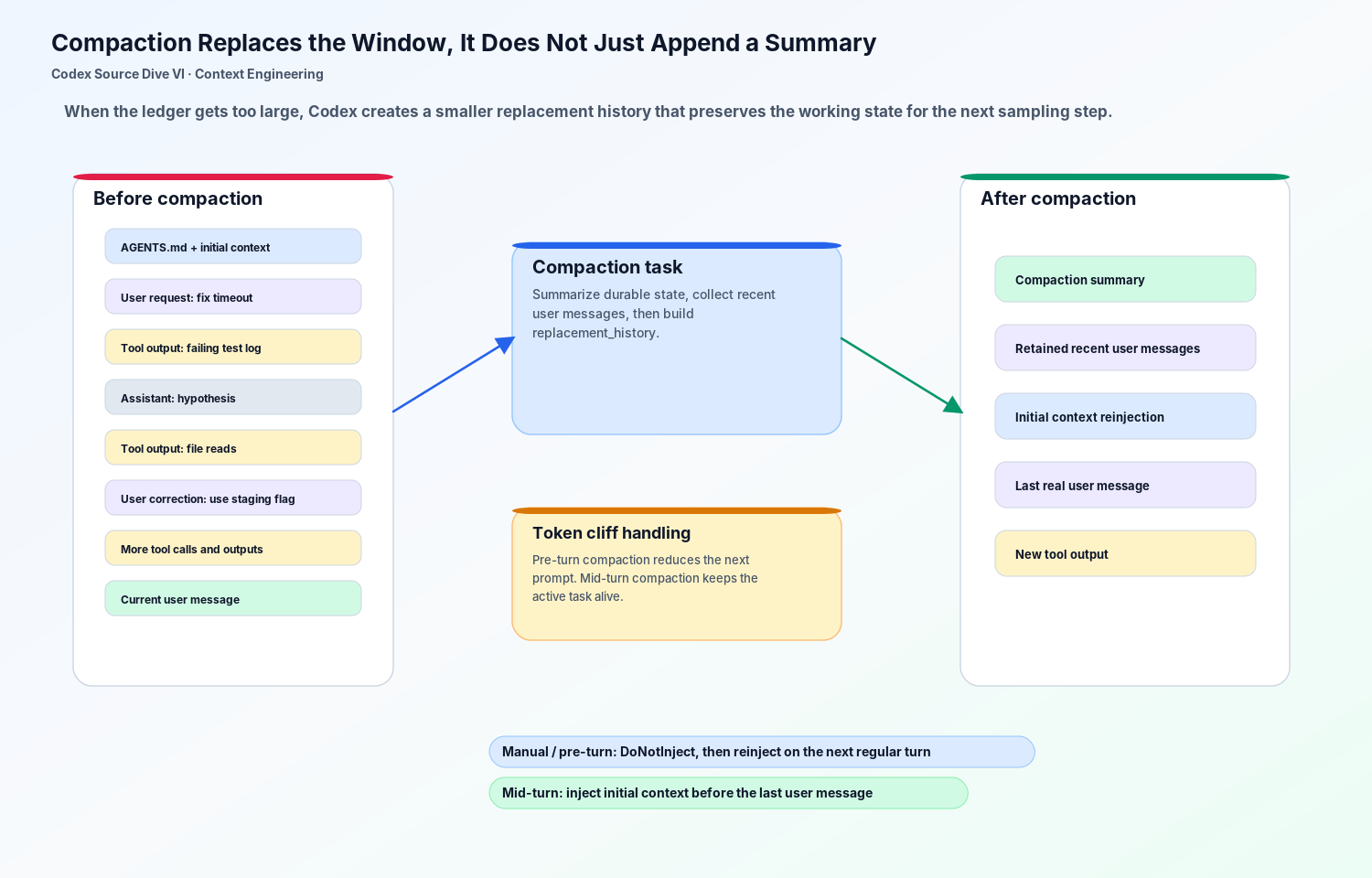
A long payment debugging thread might contain thousands of lines of tool output. Most of that should not survive verbatim. What must survive is the durable state:
- the bug is in the timeout adapter, not the retry scheduler;
- the user corrected the staging feature flag;
make test-payments TEST=checkout_timeoutis the narrow verification command;- generated SDK files should not be edited;
- the last attempted patch changed the adapter but has not passed the full service test.
Compaction tries to preserve that state while dropping token-heavy noise.
The source has two especially important placement rules.
For manual or pre-turn compaction, Codex can replace history with the summary and avoid immediately injecting the initial context. The next regular turn will reinject the relevant initial context as needed.
For mid-turn compaction, Codex cannot wait for the next turn. The current task is already alive. If the model has just produced a tool call and still needs follow-up sampling, the runtime may compact inline. In that case, the initial context has to be inserted before the last real user message, so the model still sees the active request in the right position.
This is subtle, and it is exactly why compaction belongs inside the runtime. The model can write a summary, but the runtime decides how that summary becomes history.
5. The long turn survives because context has lifecycle
Return to the checkout bug.
The model has read the adapter, applied a small patch, run the narrow test, received a failure, and now needs to inspect a fixture. Token usage crosses the usable limit. A simplistic agent would fail, truncate blindly, or ask the user to restart. Codex has another option: compact the current working memory and continue the turn.
The lifecycle looks like this:
AGENTS.md chain
↓
skill catalog and selected skills
↓
thread history + tool results
↓
pre-sampling or mid-turn compaction
↓
replacement_history + initial context reinjection
↓
next sampling requestThe crucial phrase is “next sampling request.” The context system is not just preparing the first prompt. It is preparing every prompt in the loop.
That also explains why AGENTS.md, Skills, and Compaction belong in the same article. They solve different failure modes of the same runtime problem:
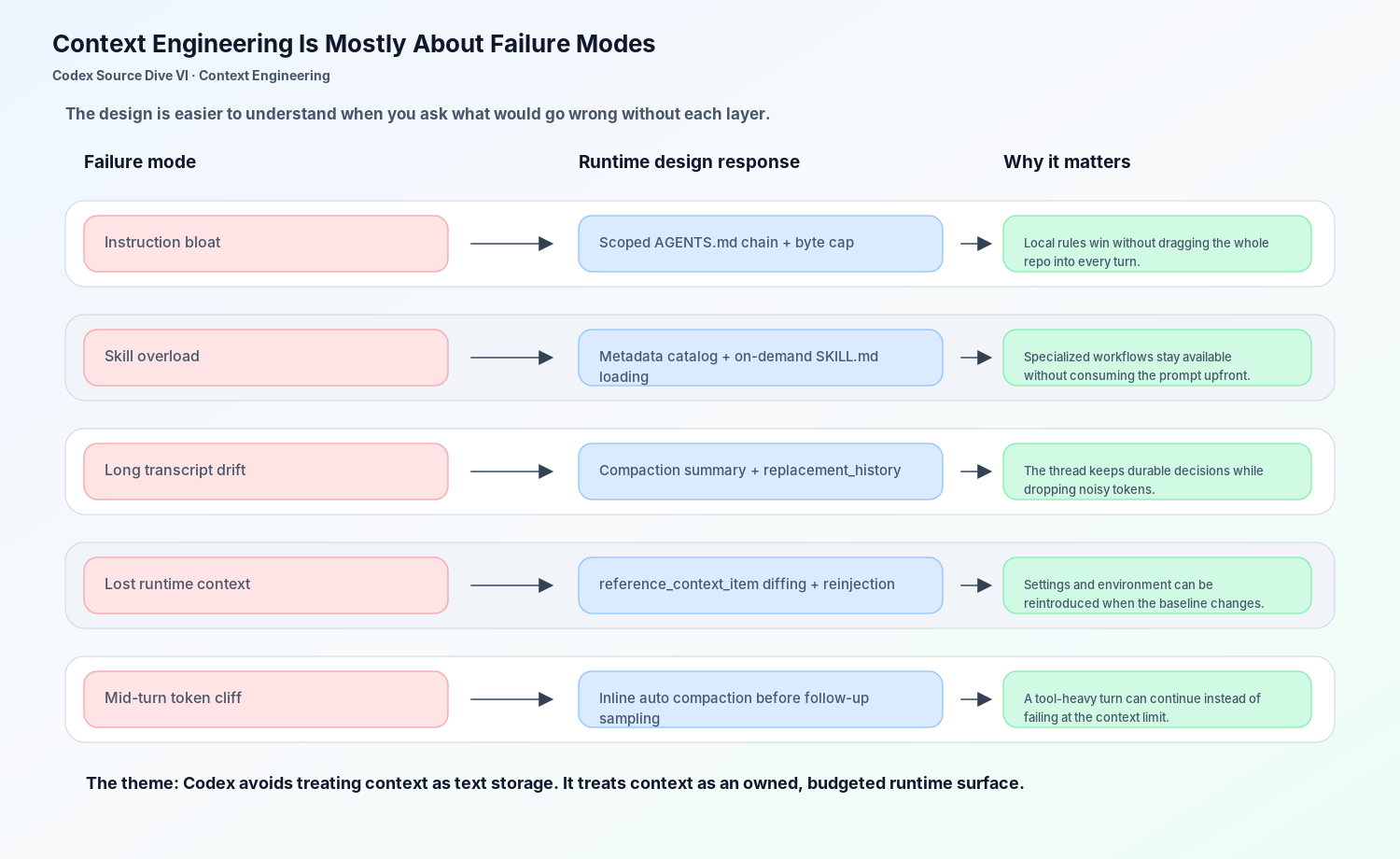
AGENTS.md prevents local project rules from being forgotten. Skills prevent specialized workflows from becoming permanent prompt bloat. Thread history turns tool observations and user corrections into durable state. Compaction prevents long work from collapsing under its own transcript. Initial context reinjection prevents a compacted or shifted history from losing the runtime facts that the model still needs.
None of these pieces is impressive alone. Together they form the model’s real working context.
6. What this teaches about agent engineering
The common advice for agent design is “give the model the right context.” That is true, but too vague to be useful.
Codex shows a sharper version:
Context should have ownership. Project rules belong to files. Skill metadata belongs to a skill index. Tool outputs belong to thread history. Summaries belong to compaction items. Runtime settings belong to context updates.
Context should have scope. Global instructions should not pretend to be local instructions. A repo-root rule should not override a payments-specific exception unless the instruction chain says it should. A release-audit workflow should not enter every coding turn.
Context should have budget. The system should cap project docs, cap skill metadata, normalize history, compact long transcripts, and avoid assuming that bigger prompt equals better behavior.
Context should have lifecycle. Some context is loaded before the turn. Some is discovered during the turn. Some is recorded after a tool result. Some is summarized and used to replace old history. Some is reinjected only when the baseline changes.
The deeper lesson is that context engineering is not prompt engineering with a larger clipboard. It is state management for an agent that reads, acts, gets corrected, and keeps going.
When Codex fixes the checkout timeout, the impressive part is not just that it can edit a file. It is that the model can operate inside a context window that has been assembled, scoped, budgeted, compacted, and restored by the runtime around it.
That is the real context.