SkillOpt: training the procedure outside the weights
The easy way to talk about agent skills is to call them prompts.
SkillOpt makes that feel wrong. A skill is closer to procedural memory: a small external artifact that tells an agent how to behave in a domain, what to check first, which mistakes to avoid, and what evidence counts.
The paper’s main move is simple but powerful: keep the target model frozen, then optimize the skill text from rollout evidence.
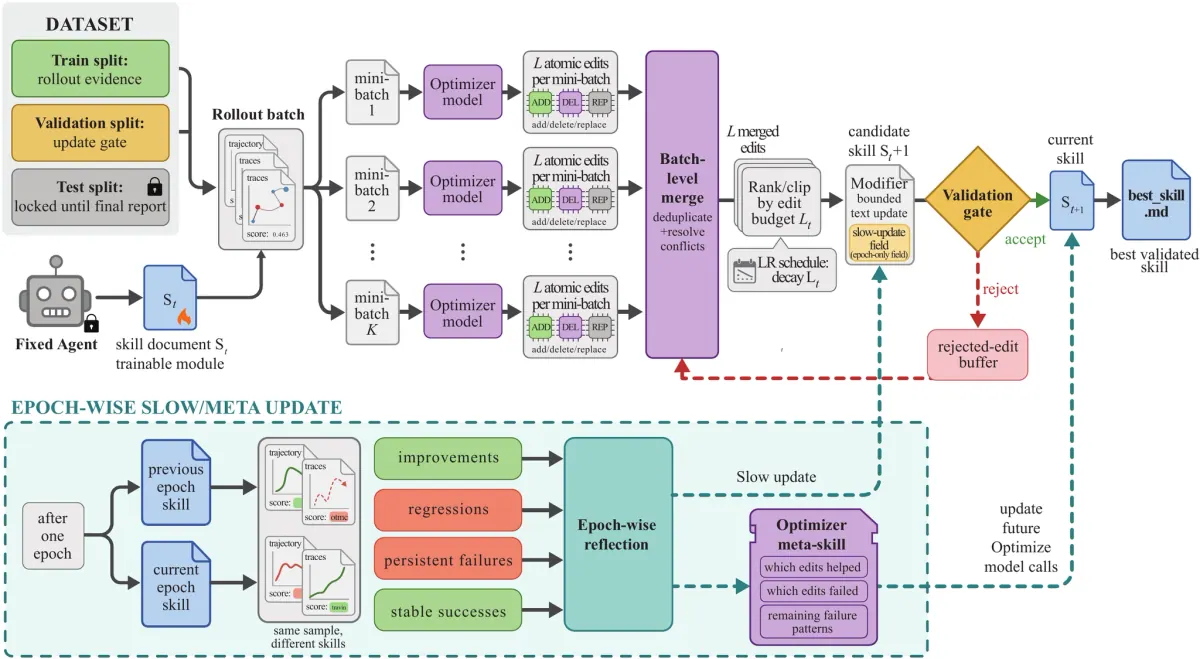
What is being trained
SkillOpt does not tune model weights. It trains a file.
That distinction matters. The deployable object is a compact best_skill.md, often small enough to inspect directly. At inference time, the optimizer disappears. The harness simply loads the trained skill and lets the target model use it.
This gives the method a nice engineering shape:
frozen model
+ current skill
+ task rollouts
+ scored outcomes
-> optimizer proposes edits
-> validation gate accepts or rejects
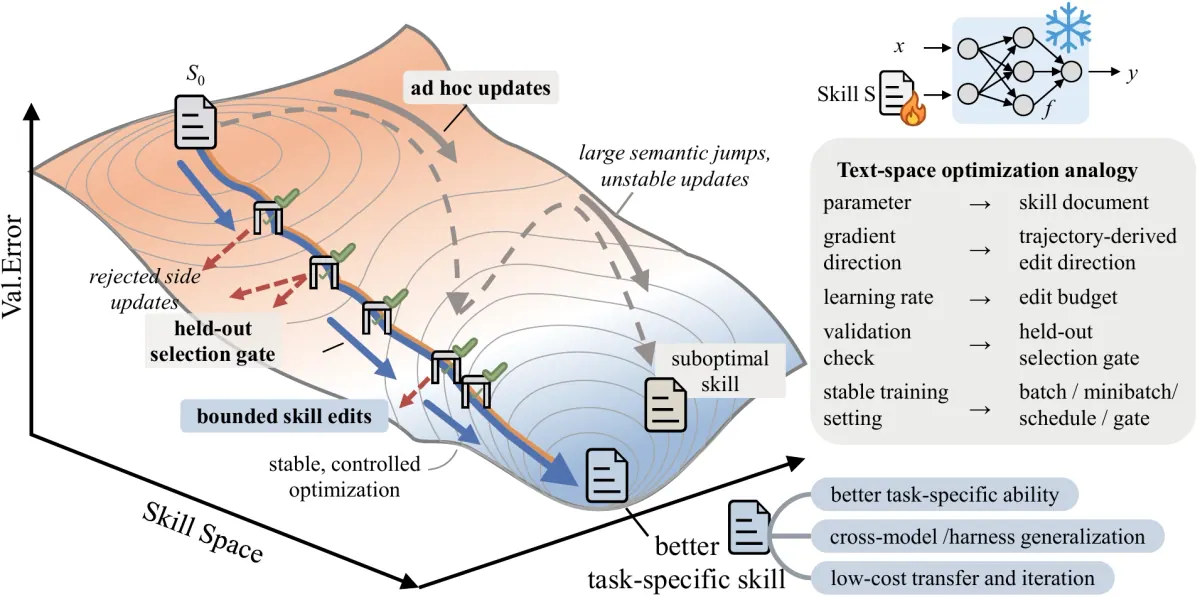
-> better skill artifactThe skill becomes a parameter in text space: readable, versionable, auditable, and portable across harnesses.
Why not just rewrite the prompt
The important detail is control. The optimizer is not asked to freely produce a new mega-prompt each round. It proposes bounded edits: add, delete, replace, merge, rank, or clip specific instructions.
The paper treats this like a textual learning rate. If each update can change too much, the skill becomes unstable. If it changes too little, it cannot learn. A good skill optimizer therefore needs the same discipline as any training loop:
- batches and minibatches;
- reflection over successes and failures;
- limited edit budgets;
- negative examples;
- slow updates for stable patterns;
- validation before deployment.
This is the part I like most. The paper turns “prompt improvement” from taste into an optimization protocol.
The validation gate is the center
The validation gate is what prevents the system from becoming an enthusiastic prompt rewriter.
A candidate skill must beat the current skill on a held-out selection split. A tie is not enough. Rejected edits are not thrown away as useless; they become negative feedback for future rounds.
That creates a useful asymmetry:
easy to propose
hard to acceptFor agent engineering, this is the right default. Text instructions are cheap to mutate and easy to overfit. The gate forces the system to prove that the change survives outside the rollout batch that inspired it.
What the learned skills contain
The most interesting learned rules are not magic phrases. They look like domain procedures.
For spreadsheet tasks, a useful skill might say: inspect workbook structure and formulas before writing static values. For QA tasks, it might say: bind the answer to exact table rows or fields before copying text. For coding tasks, it might say: reproduce the failing case before changing the implementation.
That is why “skill” is the right word. A skill compresses repeated practice:
failure trace -> rule -> reusable procedure -> validationIt is not a memory of one task. It is a maintained way of acting.
Why this matters
SkillOpt suggests a middle path between two expensive extremes:
- putting every improvement into model weights;
- writing a longer and longer system prompt by hand.
Many gains live in procedural constraints: what to inspect, what to avoid, how to verify, how to format, when to stop. Those gains can be stored in a small artifact outside the model.
That is exactly the pattern I want for personal blog writing too. A blog skill should not force every draft into one rigid template. It should preserve the reusable procedure: find the through-line, pick a loose format, write in English, use code/math only when they help, and QA the rendered page.
The broader lesson is that agents will need trainable artifacts around them, not only larger models inside them.