Beyond Individual Intelligence:LLM-based Multi-Agent Systems 的 LIFE 框架
论文笔记 / Notion 版
Paper: Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems
arXiv:
2605.14892项目仓库:
mira-ai-lab/awesome-mas-life阅读定位:这不是一篇提出新算法的论文,而是一篇把 LLM-based MAS 的研究版图重新组织成“可运行、可诊断、可演化”生命周期的 survey。
0. 一页 TL;DR
这篇文章最重要的观点是:LLM 多智能体系统不能只被理解为“多个 agent 协作”,而应该被理解为一个完整闭环:单体能力奠基 → 多智能体协作 → 失败归因 → 自我演化。
作者把这个闭环称为 LIFE progression:
| 阶段 | 含义 | 关键问题 |
|---|---|---|
| L — Lay the capability foundation | 单个 LLM agent 的基础能力 | 一个 agent 是否具备稳定的 reasoning / memory / planning / tool use? |
| I — Integrate agents through collaboration | 多 agent 的组织与协作 | agent 如何分工、通信、编排、交互? |
| F — Find faults through attribution | 多 agent 失败归因 | 系统失败时,错在哪个 agent、哪一步、哪条信息链? |
| E — Evolve through self-improvement | 系统自我演化 | 失败经验如何转化为 prompt、memory、topology、team composition 的改进? |
我的判断:这篇 survey 真正有价值的地方,是把“协作”之后的问题放到了中心位置。 许多 MAS 论文默认协作是正收益,但这篇文章强调:协作也会放大错误、增加归因难度,并且如果没有 attribution → evolution 的闭环,系统只能靠人工调 workflow。
1. 核心 Figure:LIFE Overview
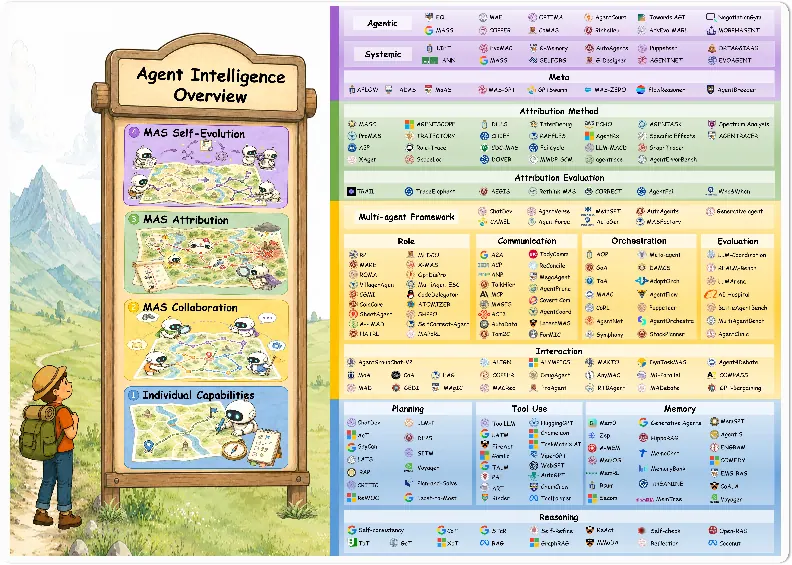
LIFE overview
图的读法:
-
左侧是单个 agent 的执行循环:观察、推理、记忆、规划、工具使用。
-
中间是多 agent 协作:角色、通信、编排、交互。
-
右侧是失败归因与系统演化:从 trace 中定位失败,再更新 agent 或系统结构。
-
这张图适合作为 Notion 首页图,因为它概括了论文主线:从 individual intelligence 走向 collective intelligence,不只是堆 agent,而是建立生命周期闭环。
2. Introduction:为什么要 Beyond Individual Intelligence?
2.1 论文提出的问题
过去两年,LLM agent 已经具备了越来越强的能力:
-
能进行多步 reasoning;
-
能使用 memory 维护历史上下文;
-
能 planning,把目标拆成子任务;
-
能 tool use,调用搜索、代码、API、浏览器、数据库等外部工具。
但单个 agent 在长程任务、跨角色任务、跨工具任务中仍然很脆弱。于是 MAS 成为自然方向:让 planner、executor、critic、researcher、coder、tester 等 agent 分工协作。
论文指出,MAS 的问题在于:协作带来能力提升,也带来错误传播。
一个 agent 的错误可能会被另一个 agent 当作事实继续使用;一个错误的 task decomposition 会让后续所有执行偏离;一个 tool call 的返回值如果没有被验证,可能会污染 shared memory。最终系统失败时,我们往往只看到 final answer wrong,却不知道根因在哪里。
2.2 论文的核心贡献
这篇文章的贡献可以概括为三点:
-
统一框架:用 LIFE 把 individual agent、collaboration、failure attribution、self-evolution 串成一个 operational lifecycle。
-
提出因果依赖关系:每个阶段不是孤立模块,而是相互约束。例如,缺少 trace 的协作系统无法做 attribution;归因不清的系统无法做可靠 evolution。
-
把失败归因放到 MAS 中心位置:这是很多 agent survey 没有充分强调的部分。论文认为,未来 MAS 的关键不是“更多 agent”,而是“能否诊断并修复自身”。
3. Section:Individual Intelligence
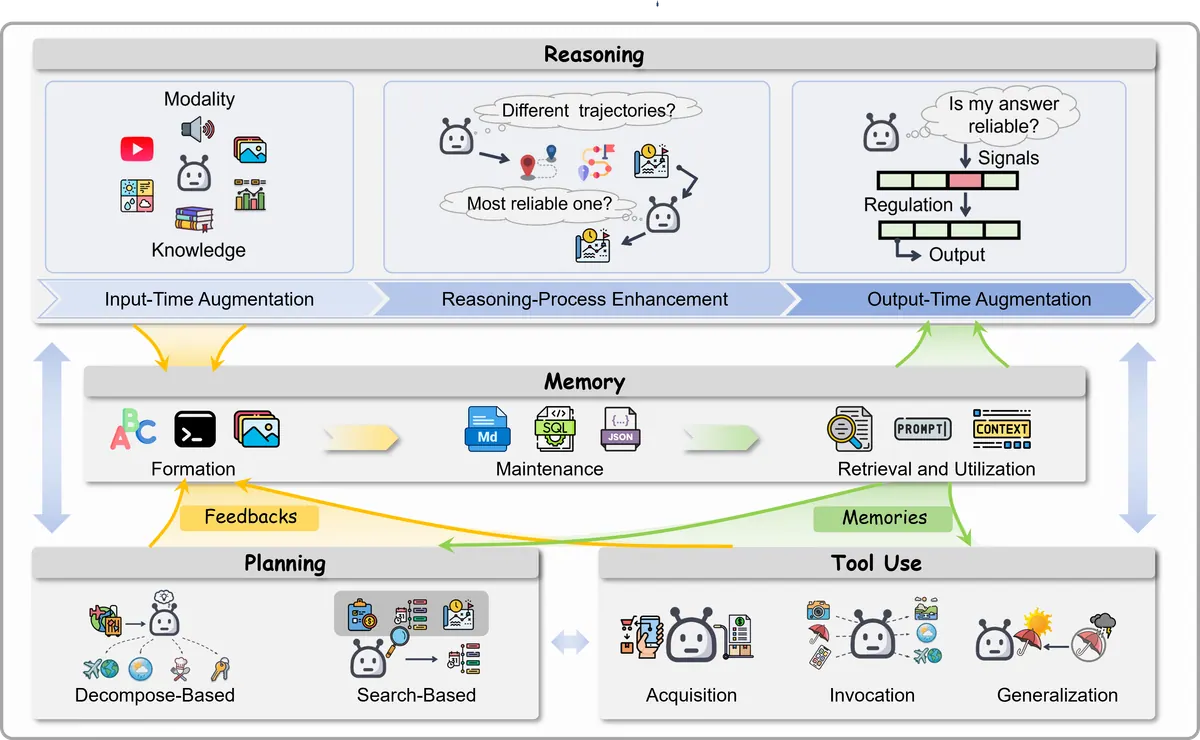
Individual agent capabilities
3.1 这一章的核心观点
单个 agent 是 MAS 的能力地基。多 agent 系统并不会自动消除单 agent 的弱点,反而会把这些弱点系统化。因此,论文先把单个 LLM agent 拆成四类核心模块:
-
Reasoning:如何推理与验证;
-
Memory:如何形成、维护、检索和使用记忆;
-
Planning:如何拆解目标并搜索行动路径;
-
Tool Use:如何学习、选择、调用和泛化工具。
这四个模块构成一个 agent 的基本闭环:
Observe → Retrieve Memory → Reason → Plan → Act / Tool Call → Observe Result → Update Memory3.2 Reasoning:从 CoT 到 search / verification
论文把 reasoning 技术大致分成三个阶段。
A. Input Augmentation
目标是在推理前补充更可靠的信息。
常见技术:
-
RAG:从外部知识库检索证据,再生成答案。
-
Self-RAG:让模型判断何时需要检索、检索内容是否有用、输出是否被证据支持。
-
Multimodal CoT / Visual Sketchpad:在视觉、图表、空间任务中生成中间视觉表示。
-
KG-RAG / Rule-Augmented Generation:把知识图谱、规则、结构化约束引入推理上下文。
代表论文:
-
Lewis et al., 2020 — Retrieval-Augmented Generation
-
Asai et al., 2024 — Self-RAG
-
Hu et al., 2024 — Visual Sketchpad
-
Besta et al., 2024 — Graph of Thoughts
B. Process Enhancement
目标不是只拿一个 chain,而是在推理过程中扩大搜索空间、验证中间步骤。
常见技术:
-
CoT / Zero-shot CoT:让模型显式展开中间推理。
-
Self-Consistency:采样多条 reasoning path,再投票或聚合。
-
Tree of Thoughts:把推理从线性 chain 扩展到 tree search。
-
Graph of Thoughts:允许多个 thought 合并、回溯、重用。
-
Reflexion / Self-Refine:模型对失败轨迹进行语言级反思并重试。
-
PRM / Process Reward Model:对每个推理步骤评分,而不是只评最终答案。
-
LATS / REST-MCTS:把 reasoning、acting、planning 统一到搜索框架里。
代表论文:
-
Wei et al., 2022 — Chain-of-Thought Prompting
-
Wang et al., 2023 — Self-Consistency
-
Yao et al., 2023 — Tree of Thoughts
-
Shinn et al., 2023 — Reflexion
-
Lightman et al., 2024 — Let’s Verify Step by Step
-
Zhou et al., 2024 — Language Agent Tree Search
C. Output Regulation
目标是降低幻觉、错误自信和不可靠输出。
常见技术:
-
FActScore / FacTool / FactCheck-GPT:事实核查。
-
SelfCheckGPT / semantic entropy:用采样一致性或语义不确定性判断 hallucination。
-
DoLa / CAD / contrastive decoding:通过解码策略减少无证据生成。
-
CoVe / RARR:先生成,再验证,再修正。
-
R-Tuning / abstention:让模型知道什么时候应该拒答或说不知道。
对 agent swarm 的启发:agent 的 reasoning 不应该只是一条 hidden chain,而应该变成可审计的 reasoning artifact。 多 agent 系统尤其需要中间产物,因为 failure attribution 必须依赖这些过程信息。
3.3 Memory:从被动存储到可演化记忆
论文把 memory 视为 agent 长期运行的核心能力。粗略可分为三类:
| 类型 | 作用 | 例子 |
|---|---|---|
| Semantic memory | 存事实、规则、知识 | 文档、API spec、知识图谱 |
| Episodic memory | 存具体执行经历 | 某次任务轨迹、错误案例 |
| Procedural memory | 存可复用技能 | 调试流程、搜索策略、工具调用模板 |
Memory 不是越多越好,核心问题是:
-
如何形成 memory?
-
如何判断什么值得保存?
-
如何压缩、合并、遗忘?
-
如何在当前任务中检索到真正有用的 memory?
-
memory 是否会引入 stale / wrong / irrelevant context?
代表技术:
-
hierarchical memory;
-
graph memory;
-
episodic-to-procedural skill distillation;
-
utility-driven memory maintenance;
-
retrieval + reflection + consolidation。
对 swarm 的启发:shared memory 很危险,必须区分 fact、belief、hypothesis、decision、artifact、tool observation。 否则错误会被写入公共上下文,并在多 agent 间传播。
3.4 Planning:从任务拆解到搜索式决策
Planning 连接目标与行动。论文把 planning 技术分成两类:
A. Decomposition
将复杂任务拆成更小的子任务。
代表技术:
-
Least-to-Most Prompting;
-
Plan-and-Solve;
-
Skeleton-of-Thought;
-
ADaPT;
-
SelfGoal。
B. Search
不只生成一个 plan,而是在候选 plan / action space 中搜索。
代表技术:
-
Tree of Thoughts / MCTS;
-
Reasoning as Planning with World Model;
-
REST-MCTS;
-
ToolChain;
-
AFlow:自动搜索 agentic workflow。
对 swarm 的启发:planner agent 的输出不能直接成为系统事实。它应该是一个可验证、可回滚、可修正的 plan artifact。
3.5 Tool Use:agent 与外部世界的接口
Tool use 让 LLM agent 从“文本生成器”变成“可行动系统”。论文将其拆成:
| 子问题 | 关注点 | 代表技术 |
|---|---|---|
| Acquisition | 如何学习工具能力 | Toolformer、GPT4Tools、APIGen、ToolLLM、Gorilla |
| Invocation | 如何选择和调用工具 | ReAct、CodeAct、ToolPlanner、WorkflowLLM |
| Generalization | 如何泛化到未见工具 | AnyTool、GenTool、BFCL |
对 swarm 的启发:tool call 必须被视为高风险节点。工具输入、工具输出、错误码、重试策略、调用 agent、依赖消息都应该进入 trace。
4. Section:Multi-Agent Collaboration
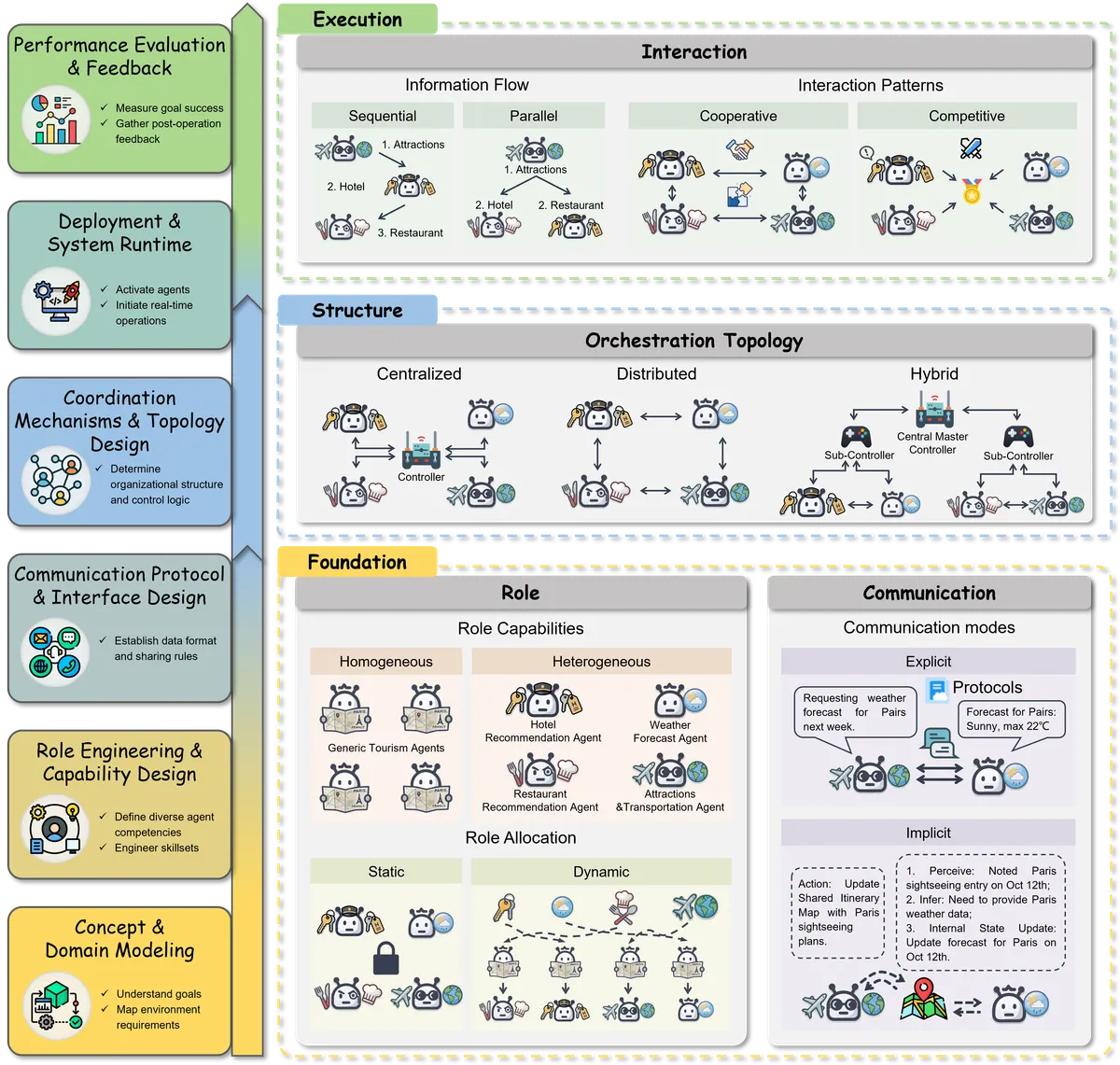
Multi-agent collaboration framework
4.1 这一章的核心观点
MAS 的协作不是简单地让多个 agent 轮流发言,而是一个组织设计问题。论文将协作机制拆成四个维度:
-
Role:谁负责什么?
-
Communication:信息如何流动?
-
Orchestration:系统如何调度和组织 agent?
-
Interaction:agent 在执行中如何相互作用?
4.2 Role:静态角色 vs 动态角色
常见做法
很多现有系统使用静态角色:
-
planner;
-
researcher;
-
coder;
-
reviewer;
-
critic;
-
executor;
-
manager / supervisor。
这种设计易控、易调试,适合结构化任务,如代码生成、数据分析、论文写作、客服流程。
代表系统:
-
ChatDev:软件开发中的 communicative agents。
-
MetaGPT:把软件公司流程编码成多 agent framework。
-
AutoGen:通过多 agent conversation 组织应用。
前沿方向
更前沿的方向是动态角色:
-
根据任务自动 recruit agent;
-
根据历史表现调整 agent 权重;
-
根据失败归因替换或重训角色;
-
允许 agent 自组织产生临时职责。
对 swarm 的启发:角色应该注册为 capability profile,而不是写死在 prompt 中。 每个 agent 应有能力、成本、可用工具、历史失败类型、适用任务等元数据。
4.3 Communication:显式通信 vs 隐式通信
显式通信
最主流方式是 natural language message 或 structured message。
优点:
-
可解释;
-
易调试;
-
易做人类审计;
-
适合跨模型、跨工具、跨系统协作。
问题:
-
token 成本高;
-
长对话信息冗余;
-
消息质量不稳定;
-
错误信息会被后续 agent 传播。
隐式通信
隐式通信通过 shared environment、shared state、artifact、blackboard 或行动结果来传递信息。
优点:
-
更高效;
-
更接近 distributed systems;
-
减少大量自然语言通信。
问题:
-
更难解释;
-
更难归因;
-
需要强 observability。
协议层趋势
值得关注的协议 / 标准方向:
-
MCP:偏模型与工具 / 上下文连接;
-
A2A:偏 agent-to-agent interoperability;
-
ACP / ANP:偏 agent 通信与网络化协作。
对 swarm 的启发:通信协议不能只定义 message format,还要定义 provenance:谁说的、基于什么证据、是否验证、被谁消费。
4.4 Orchestration:centralized / distributed / hybrid
| 拓扑 | 优点 | 风险 | 适用场景 |
|---|---|---|---|
| Centralized | 全局可控、容易调度、容易设置 guardrail | 单点瓶颈、manager 幻觉会影响全局 | 企业 workflow、强约束任务 |
| Distributed | 自主性强、鲁棒性好、可并行 | 难达成一致、难归因、难安全控制 | 搜索、探索、开放式任务 |
| Hybrid | 兼顾全局目标与局部自治 | 架构更复杂 | 生产级 swarm 的现实选择 |
代表方向:
-
AutoGen-style conversation orchestration;
-
MetaGPT-style workflow orchestration;
-
GPTSwarm:把 language agents 表示为可优化图;
-
AFlow:自动生成 agentic workflow;
-
Evolving Orchestration:让协作编排本身可演化。
我的判断:生产级 agent swarm 更适合 hybrid topology。 supervisor 负责目标、预算、安全、终止条件;局部 agent group 负责并行探索和执行;critic / evaluator / attribution agent 作为旁路审计层。
4.5 Interaction:顺序、并行、竞争与合作
常见交互模式:
-
Sequential:planner → executor → reviewer。
-
Parallel:多个 agent 并行生成候选,再聚合。
-
Debate:agent 互相挑战,提升 reasoning robustness。
-
Critique / revise:一个 agent 生产,另一个 agent 审查。
-
Cooperative:共享目标,协同完成。
-
Competitive:通过对抗或竞赛暴露错误。
对 swarm 的启发:不要默认更多轮对话更好。需要衡量:
-
协作是否真正提升 accuracy?
-
token / latency 成本是否合理?
-
哪个 agent 的贡献最大?
-
哪些 message 是噪声?
-
哪些交互导致错误传播?
4.6 Evaluation:从 final score 到 trajectory-level evaluation
论文强调,MAS evaluation 不能只看 final answer。应该评估:
-
task success rate;
-
subgoal completion;
-
communication efficiency;
-
agent contribution;
-
action trajectory correctness;
-
tool-call correctness;
-
error propagation;
-
recovery ability;
-
collaboration gain vs resource increase。
这点对我们做 swarm 非常关键:协作收益必须扣除 token、latency、agent 数量、工具调用次数,否则只是 compute 堆出来的幻觉收益。
5. Section:Failure Attribution
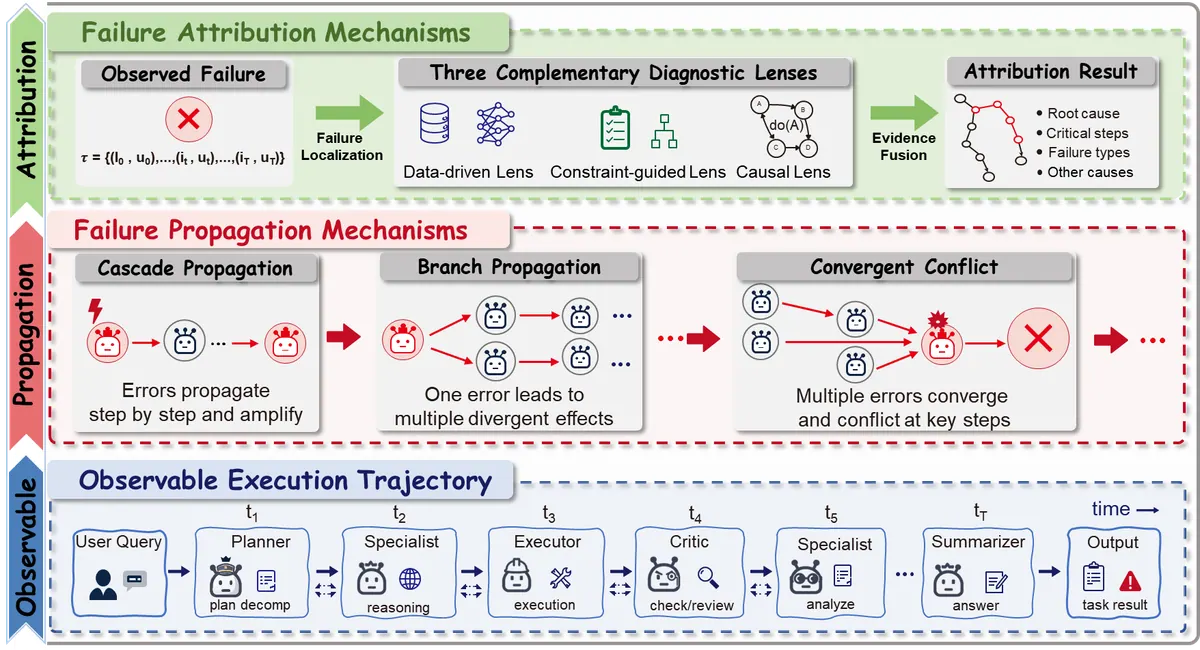
Failure attribution mechanism
5.1 这一章的核心观点
多 agent 失败很少是“某一步错了”这么简单,而是一个跨 agent、跨 message、跨 tool call 的传播链。
失败归因要回答:
系统为什么失败?
失败最早在哪里发生?
哪个 agent / message / tool call 是关键原因?
错误如何传播?
哪些检查本应阻断错误却没有阻断?论文把 failure attribution 放在 collaboration 与 self-evolution 之间,这是非常关键的设计:没有归因,自我演化就只是盲目调参。
5.2 Formal Definition:从 trajectory 到 root cause
一个 attribution 模块通常需要输入:
-
task / user query;
-
system configuration;
-
agent roles;
-
communication graph;
-
full trajectory;
-
tool call logs;
-
intermediate artifacts;
-
final output / evaluator result。
输出应该包括:
-
failure type;
-
responsible agent;
-
critical time step;
-
causal message / action;
-
propagation path;
-
repair suggestion。
5.3 Failure Category:失败从哪里来?
论文从多个角度组织失败类型。
A. System Structure Perspective
关注协作链条在哪里断裂:
-
specification failure:任务理解错;
-
role failure:角色分配不合理;
-
communication failure:信息传递缺失、歧义、污染;
-
orchestration failure:调度顺序或拓扑不合理;
-
verification failure:没人检查关键中间结论。
B. Execution Stage Perspective
关注执行阶段中的错误:
-
reasoning error;
-
planning error;
-
tool-use error;
-
memory retrieval error;
-
action execution error;
-
environment interaction error;
-
aggregation / finalization error。
C. Causal Lifecycle Perspective
关注错误如何形成、传播、暴露:
root cause → local error → propagation → downstream dependency → final failure这比简单分类更重要,因为 swarm 的失败往往是延迟暴露的:早期 message 看起来合理,但后续 agent 基于它做了错误行动。
5.4 Attribution Taxonomy:三条技术路线
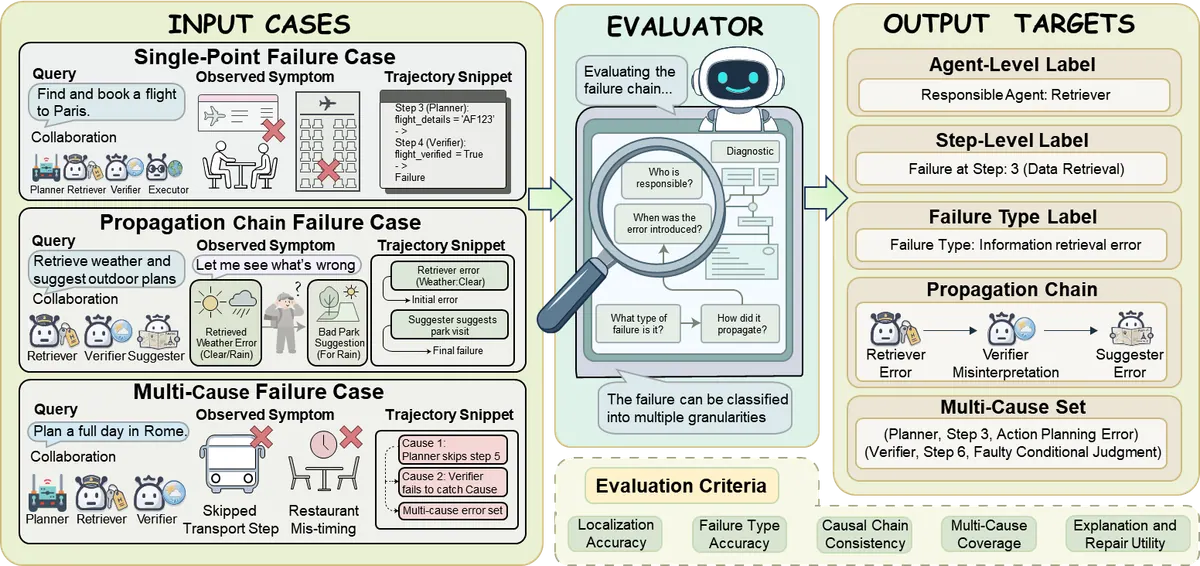
Attribution cases
A. Data-driven Attribution
把归因当成监督学习或表示学习问题。
做法:
-
收集大量成功 / 失败 trajectory;
-
标注 responsible agent / step;
-
训练 failure localizer;
-
用 learned model 对新轨迹进行定位。
优点:
-
可扩展;
-
适合大量日志;
-
能学习复杂 pattern。
问题:
-
标注难;
-
ground truth 不稳定;
-
容易学到相关性而非因果性。
代表论文:
-
Which Agent Causes Task Failures and When? — 自动化定位哪个 agent 在何时导致失败。
-
TRAIL: Trace Reasoning and Agentic Issue Localization — 面向 agent trace 的 issue localization。
B. Constraint-guided Diagnosis
把归因拆成一组显式诊断规则和检查流程。
做法:
-
先定义 failure taxonomy;
-
再根据阶段、角色、工具、约束缩小搜索空间;
-
最后用证据判断根因。
优点:
-
可解释;
-
适合生产排障;
-
易与 observability 系统结合。
问题:
-
规则设计成本高;
-
对开放式任务覆盖不足;
-
容易漏掉复杂因果链。
代表论文:
-
Why Do Multiagent Systems Fail?
-
Diagnosing Failure Root Causes in Platform-Orchestrated Agentic Systems
-
AgentErrorBench / Where LLM Agents Fail and How They Can Learn from Failures
C. Causal-inference Attribution
这是最值得长期关注的方向。
核心问题不是“谁输出了错误内容”,而是:
如果去掉某一步 / 替换某条 message / 修正某个 tool call,系统是否仍会失败?
常见方法:
-
counterfactual replay;
-
causal graph construction;
-
intervention analysis;
-
Shapley-style contribution;
-
multi-step propagation tracing。
代表论文:
- From Flat Logs to Causal Graphs: Hierarchical Failure Attribution for LLM-based MAS
对 swarm 的启发:我们不应该只存 logs,而应该存可重放的 causal trace。 没有 replay,就很难做 counterfactual attribution。
5.5 Attribution Evaluation:如何评估归因是否正确?
归因评估不能只看 accuracy。应该包括:
-
root-cause precision / recall;
-
agent-level attribution accuracy;
-
step-level localization accuracy;
-
explanation faithfulness;
-
counterfactual validity;
-
time-to-diagnosis;
-
repair usefulness;
-
post-repair performance gain。
这点很重要:一个解释听起来合理,不代表它能指导修复。 最好的归因结果应该能让系统在后续任务上明显改善。
6. Section:Self-Evolution
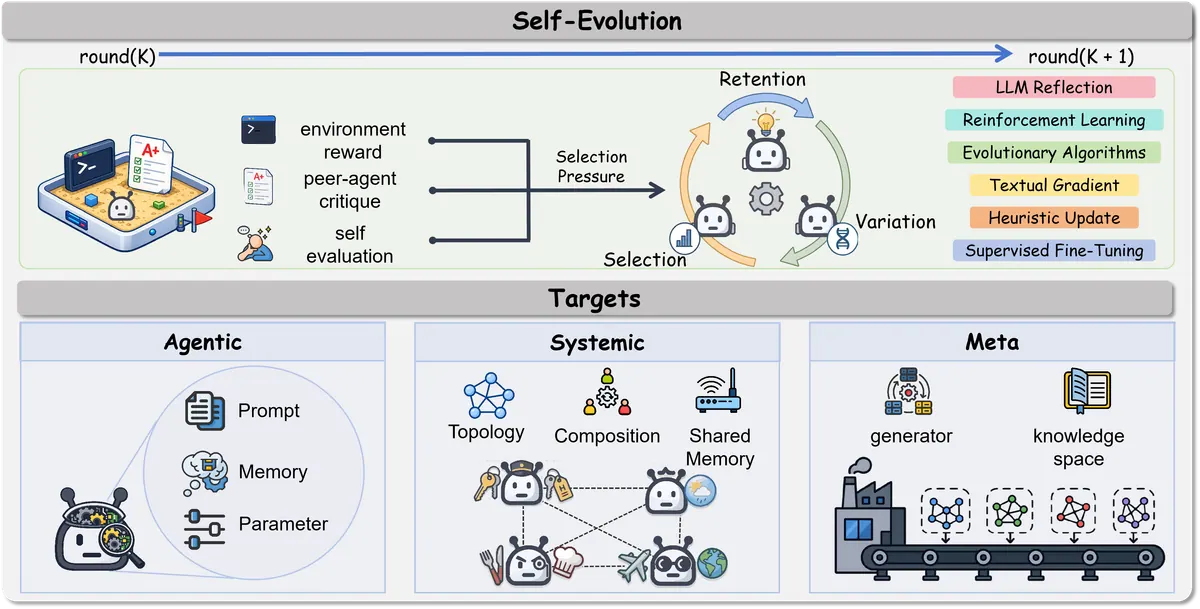
Self-evolution framework
6.1 这一章的核心观点
Self-evolution 是从“复盘失败”走向“修改系统”。
如果 attribution 回答:
为什么失败?
那么 self-evolution 回答:
系统应该如何改变,才能以后更少失败?
论文强调,多 agent 的 self-evolution 不只是让某个 agent reflection,也不是简单改 prompt。它可能修改整个 MAS 的结构。
6.2 从 Attribution 到 Evolution
一个合理闭环应该是:
Task execution
→ Full trajectory
→ Failure detection
→ Failure attribution
→ Patch proposal
→ Sandbox evaluation
→ Promote / rollback
→ Updated MAS如果没有 attribution,evolution 的搜索空间太大:到底该改 prompt、memory、tool policy、role assignment、communication protocol,还是 topology?归因的作用就是缩小修复空间。
6.3 Evolution Taxonomy:三层演化对象
A. Agentic Self-Evolution
修改单个 agent 内部能力。
对象:
-
prompt;
-
role instruction;
-
memory;
-
tool-use policy;
-
reasoning strategy;
-
model parameter / adapter。
典型技术:
-
Reflexion;
-
Self-Refine;
-
verbal reinforcement learning;
-
memory consolidation;
-
PRM / RL feedback;
-
tool-use curriculum。
适合修复的问题:
-
某个 agent 常犯同类 reasoning error;
-
某个 agent tool selection 不稳定;
-
某个 agent 没有记住历史经验;
-
某个 agent role prompt 不清晰。
B. Systemic Self-Evolution
修改整个 MAS 的协作结构。
对象:
-
agent team composition;
-
communication topology;
-
handoff protocol;
-
shared memory schema;
-
reviewer / critic placement;
-
planner-executor relationship;
-
tool ownership;
-
parallelism strategy。
典型技术:
-
evolving orchestration;
-
graph search over workflows;
-
RL over communication policy;
-
textual gradient / prompt optimization;
-
dynamic role assignment;
-
auto-generated agentic workflow。
适合修复的问题:
-
agent 之间重复劳动;
-
关键结论无人验证;
-
通信成本过高;
-
某些 agent 长期边缘化;
-
planner bottleneck;
-
review 环节太晚,错误已传播。
C. Meta Self-Evolution
把整个 MAS 配置当成候选架构,在任务分布上搜索、评估、选择、沉淀。
对象:
-
system blueprint;
-
team design pattern;
-
reusable workflow;
-
orchestration graph;
-
agent constitution;
-
design knowledge archive。
典型机制:
-
population-based search;
-
evolutionary algorithms;
-
meta-agent;
-
architecture generator;
-
cross-task design memory。
适合长期方向:
-
不同任务自动选择不同 agent organization;
-
从历史项目中沉淀 team playbook;
-
让 swarm 在任务分布变化时自动重组。
6.4 Evolution Dynamics:variation / selection / retention
论文借鉴演化视角,把 self-evolution 看成三步:
| 阶段 | 含义 | MAS 中的例子 |
|---|---|---|
| Variation | 产生候选变化 | 改 prompt、换 topology、增删 agent |
| Selection | 评估哪些变化有效 | reward、peer critique、self-eval、benchmark |
| Retention | 保留有效变化 | 写入 memory、更新 config、保存 workflow |
对工程系统来说,最关键的是 retention:有效改动必须版本化,否则系统只是在每轮“临时变聪明”,无法形成长期能力。
6.5 前沿补充:这篇 survey 之后/附近值得一起看
这几篇与论文主线高度相关,适合作为延伸阅读:
| 论文 / 方向 | 为什么重要 |
|---|---|
| Meta-Team: Collaborative Self-Evolution for LLM-based MAS | 强调 MAS 不只要作为团队执行,也要作为团队演化;把演化分成 agent-level、interaction-level、team-level。 |
| Towards a Science of Collective AI | 提出 collaboration gain 和 factor attribution,避免 MAS 研究停留在盲目试错。 |
| FluxMem / evolving memory | 把 memory 看成动态连接结构,而不是静态向量库,适合作为 agentic evolution 的底层能力。 |
| AFlow / GPTSwarm / Evolving Orchestration | 把 workflow / agent graph 本身作为可搜索、可优化对象。 |
7. Discussion:论文指出的关键挑战
7.1 Closed-loop benchmark 缺失
多数 benchmark 只测最终任务成功率。但 LIFE 需要测完整闭环:
失败是否被检测?
根因是否被定位?
修复是否被提出?
修复后是否真的更好?
这种改进是否能迁移?未来需要 end-to-end benchmark,评估 attribution → evolution 的真实收益。
7.2 Attribution ground truth 很难定义
多 agent 失败经常是多因多果:
-
planner 初始拆解有问题;
-
executor 没有发现;
-
reviewer 没有检查;
-
tool 返回值被误读;
-
supervisor 过早终止。
这种情况下,“谁负责”不是单标签问题,而是 causal contribution 问题。
7.3 Telemetry / trace 标准仍然缺失
要做可靠归因,需要统一的日志结构:
-
agent ID;
-
role;
-
timestamp;
-
message lineage;
-
memory read / write;
-
tool call input / output;
-
artifact version;
-
decision rationale;
-
evaluator feedback;
-
upstream dependency。
没有这些结构化 trace,failure attribution 无法工程化。
7.4 Evolution 的安全与稳定性
系统如果能改自己,就会带来新风险:
-
reward hacking;
-
self-reinforcing hallucination;
-
unsafe topology;
-
agent collusion;
-
memory poisoning;
-
performance oscillation;
-
rollback 困难。
因此 self-evolution 不能直接上线,必须有 sandbox、evaluation、rollback、human approval 或 policy guardrail。
8. 对我们做 Agent Swarm 的启发
8.1 先做 trace,而不是先堆 agent
最小可行的 swarm 不应该是“多个 agent 聊天”,而应该是:
agent execution + structured trace + replayable artifacts每个 action 都应记录:
-
谁做的;
-
基于什么信息;
-
调用了什么工具;
-
产出了什么 artifact;
-
谁消费了这个 artifact;
-
后续是否被验证;
-
最终结果是否依赖它。
8.2 Swarm runtime 应该是 hybrid topology
推荐结构:
Global Supervisor
├── task decomposition / budget / safety / stop condition
├── role registry / dynamic routing
├── local agent groups
│ ├── researcher group
│ ├── coding group
│ ├── verification group
│ └── tool execution group
└── sidecar modules
├── evaluator
├── attribution agent
└── evolution proposer重点:attribution / evaluator 不应该混在 executor 内部,而应该成为旁路模块。
8.3 把 role 做成 registry
每个 agent 应该有 profile:
agentid:
role:
capabilities:
tools:
costprofile:
reliabilityscore:
commonfailuremodes:
besttasktypes:
memoryscope:
allowedactions:这样 swarm 才能根据任务动态组队,而不是写死 planner / executor / reviewer 三件套。
8.4 建立 Failure Attribution Layer
建议先支持这些 failure types:
-
specification failure;
-
planning failure;
-
retrieval failure;
-
tool selection failure;
-
tool execution failure;
-
communication failure;
-
verification failure;
-
aggregation failure;
-
memory contamination;
-
premature termination。
归因输出应能直接生成 patch proposal:
failuretype → suspectedagent → suspectedstep → evidence → suggestedpatch8.5 Self-evolution 必须走安全闸门
推荐闭环:
Run
→ Trace
→ Diagnose
→ Propose patch
→ Offline replay / sandbox eval
→ Compare baseline
→ Promote or rollback不要让系统直接在线修改核心 prompt、memory schema、tool permission、topology。所有 evolution 都应该版本化。
8.6 一个最小 LIFE Swarm Roadmap
| 阶段 | 最小实现 | 下一步 |
|---|---|---|
| Individual | stable ReAct + tool call + memory | PRM / self-consistency / better retrieval |
| Collaboration | supervisor + role registry + structured messages | dynamic routing + parallel teams |
| Attribution | trace schema + manual failure labels | automated root-cause localization |
| Evolution | prompt / memory patch proposal | topology / team composition evolution |
| Evaluation | final score + cost | trajectory-level + collaboration gain |
9. 重要论文与技术索引
9.1 Individual Intelligence
| 方向 | 代表论文 / 技术 | 作用 |
|---|---|---|
| CoT | Wei et al., 2022 | 基础 step-by-step reasoning |
| Zero-shot CoT | Kojima et al., 2022 | 不依赖示例的推理触发 |
| Self-Consistency | Wang et al., 2023 | 多路径采样降低偶然错误 |
| Tree of Thoughts | Yao et al., 2023 | 搜索式 reasoning |
| Graph of Thoughts | Besta et al., 2024 | 图结构 thought 合并和复用 |
| Reflexion | Shinn et al., 2023 | 语言级失败反思 |
| PRM | Lightman et al., 2024 | step-level verification |
| RAG | Lewis et al., 2020 | 外部知识增强 |
| Self-RAG | Asai et al., 2024 | 检索、生成、自我批判结合 |
| ReAct | Yao et al., 2023 | reasoning + acting |
| Toolformer | Schick et al., 2023 | 模型自学习工具使用 |
| CodeAct | Wang et al., 2024 | 用可执行代码作为 action |
9.2 Collaboration
| 方向 | 代表论文 / 系统 | 作用 |
|---|---|---|
| ChatDev | Qian et al., 2024 | 软件开发多 agent 协作 |
| MetaGPT | Hong et al., 2024 | 把组织流程编码成 agent workflow |
| AutoGen | Wu et al., 2024 | 多 agent conversation framework |
| MAPoRL | Park et al., 2025 | 多 agent post-co-training / RL |
| GPTSwarm | Zhuge et al., 2024 | agents as optimizable graphs |
| AFlow | Zhang et al., 2025 | 自动生成 agentic workflow |
| MCP / A2A | Anthropic / Google | 协议与互操作性方向 |
9.3 Failure Attribution
| 方向 | 代表论文 | 作用 |
|---|---|---|
| MAS failure taxonomy | Why Do Multiagent Systems Fail? | 分析 MAS 失败模式 |
| Automated attribution | Which Agent Causes Task Failures and When? | 定位哪个 agent 何时导致失败 |
| Trace localization | TRAIL | 面向 agent trace 的 issue localization |
| Platform root cause | Diagnosing Failure Root Causes in Platform-Orchestrated Agentic Systems | 平台化 agent 系统根因诊断 |
| Causal graph attribution | From Flat Logs to Causal Graphs | 从日志到因果图的层次化归因 |
| Failure benchmark | AgentErrorBench / Where LLM Agents Fail | 失败数据集与学习修复 |
9.4 Self-Evolution
| 方向 | 代表论文 / 技术 | 作用 |
|---|---|---|
| Reflexion / Self-Refine | Shinn et al.; Madaan et al. | 单 agent 反思式改进 |
| Voyager | Wang et al., 2024 | open-ended embodied agent with skill memory |
| PromptAgent | Wang et al., 2024 | prompt optimization as planning |
| AFlow | Zhang et al., 2025 | workflow-level evolution |
| Evolving Orchestration | Dang et al., 2025 | 协作编排演化 |
| Meta-Team | Hao et al., 2026 | team-level collaborative self-evolution |
| FluxMem | Fang et al., 2026 | evolving memory connectivity |
10. 最后的判断
这篇论文对 agent swarm 最重要的提醒是:
Swarm 的长期壁垒不是“有多少 agent”,而是能否形成 trace → attribution → evolution 的闭环。
如果一个系统只能执行任务,但不能解释失败,也不能把失败转化为结构性改进,那它只是复杂 workflow。真正的 agent swarm 应该具备:
-
可观测的执行轨迹;
-
可重放的中间 artifact;
-
可定位的失败归因;
-
可评估的修复策略;
-
可回滚的系统演化;
-
可沉淀的组织经验。
这也是这篇 survey 的核心价值:它把 MAS 从“协作范式”推进到“自诊断、自组织、自演化系统”的研究路线图。
参考入口
-
Paper:
https://arxiv.org/abs/2605.14892 -
Companion Repo:
https://github.com/mira-ai-lab/awesome-mas-life -
Figure mirror:
https://www.emergentmind.com/papers/2605.14892 -
ChatPaper summary:
https://chatpaper.com/chatpaper/paper/281172