Beyond Individual Intelligence: the LIFE frame for multi-agent systems
Paper: Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems
arXiv:
2605.14892Repository:
mira-ai-lab/awesome-mas-life
Why this survey matters
Many multi-agent papers stop at the exciting part: several agents collaborate and the final score improves.
This survey is useful because it asks what happens after that. If a multi-agent system fails, can we tell where the failure came from? If we can tell, can the system improve? If it improves, can we keep it safe, observable, and stable?
The paper’s central frame is LIFE:
| Stage | Meaning | Core question |
|---|---|---|
| L - Lay the capability foundation | Individual agent capabilities | Can one agent reason, remember, plan, and use tools reliably? |
| I - Integrate agents through collaboration | Multi-agent organization | How do agents divide roles, communicate, orchestrate, and interact? |
| F - Find faults through attribution | Failure diagnosis | When the system fails, which agent, step, message, or dependency caused it? |
| E - Evolve through self-improvement | System evolution | How do failures become safer prompts, memories, roles, tools, or topologies? |
My read: the value of the paper is not a new algorithm. It is a cleaner lifecycle for thinking about agent systems that need to run, fail, be diagnosed, and improve.
The figure to keep
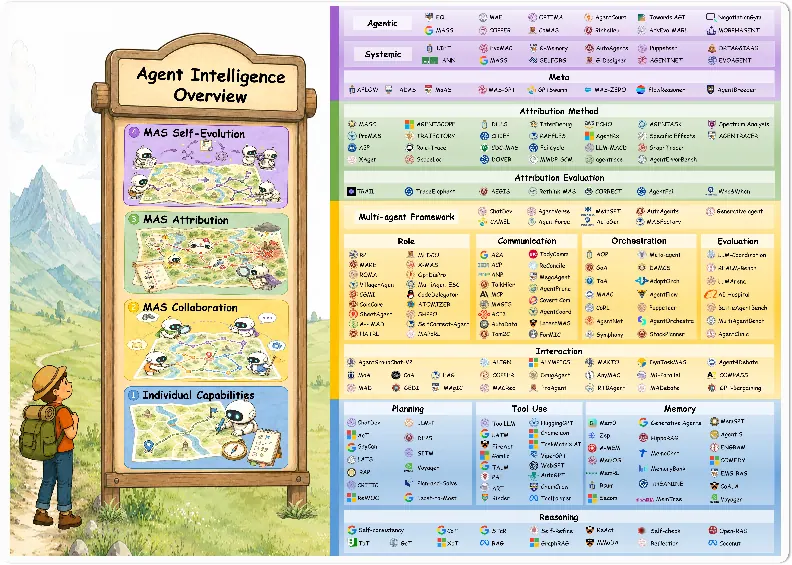
The figure is useful because it resists the lazy definition of MAS as “more than one agent.”
The lifecycle says:
individual capability
-> collaboration
-> failure attribution
-> self-evolution
-> stronger individual and system capabilityThe second half is the interesting half. Collaboration creates new capability, but it also creates new failure paths.
Individual intelligence
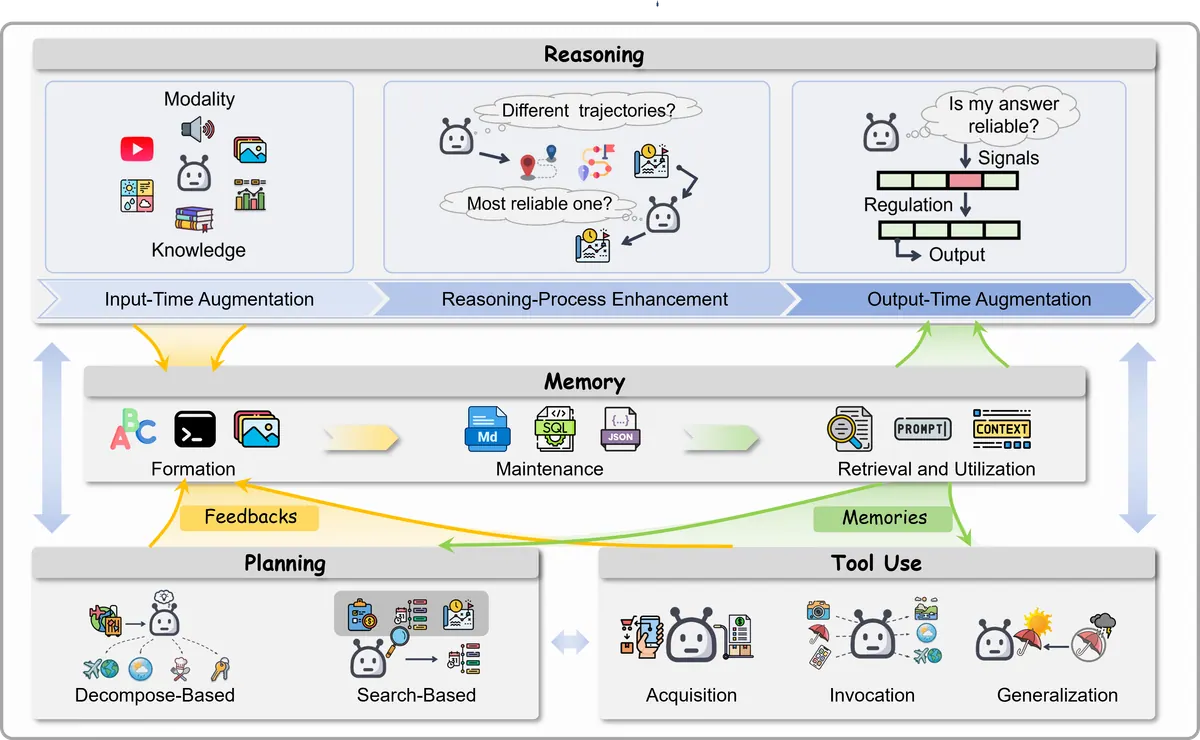
Before collaboration, a single agent needs a working execution loop:
observe -> retrieve memory -> reason -> plan -> act/tool call -> observe result -> update memoryThe survey groups individual capability into four parts:
| Capability | What it controls | Typical techniques |
|---|---|---|
| Reasoning | How the agent thinks and verifies | Chain-of-thought variants, search, self-consistency, process reward models |
| Memory | What the agent carries across time | Semantic, episodic, and procedural memory |
| Planning | How goals become action sequences | Decomposition, search, task graphs, replanning |
| Tool use | How the agent touches the world | API/tool selection, invocation, feedback handling |
The important warning: multi-agent systems do not erase single-agent weaknesses. They often systematize them.
If one agent hallucinates a dependency, another agent may use it as fact. If one planner decomposes the task badly, every worker can make locally reasonable progress in the wrong direction.
Collaboration
Collaboration is the “I” stage: integrate agents through roles, communication, orchestration, interaction, and evaluation.
| Design axis | Choices | Failure pressure |
|---|---|---|
| Role | Fixed roles, dynamic roles, emergent roles | Role labels can become theater without real authority boundaries |
| Communication | Explicit messages, shared memory, implicit signals | Bad information can propagate faster than good information |
| Orchestration | Centralized, distributed, hybrid | Control can become brittle or chaotic |
| Interaction | Sequential, parallel, competitive, cooperative | Parallelism can hide conflicts until synthesis |
| Evaluation | Final answer, trajectory, role-level, system-level | Final score alone cannot diagnose why the system failed |
The paper’s frame pushes me toward a practical rule:
Use more agents only when the system also has clearer state, boundaries, and verification.
Otherwise “multi-agent” becomes a way to amplify ambiguity.
Failure attribution
Failure attribution is the section I care about most.
For ordinary applications, a failed final answer is already bad. For multi-agent systems, it is worse because the system may have many plausible failure sources:
- the initial task was ambiguous;
- the planner decomposed it poorly;
- a worker used the wrong evidence;
- a tool returned stale data;
- a verifier missed a contradiction;
- shared memory stored a false claim;
- synthesis erased a minority warning;
- the stop condition fired too early.
Without attribution, the only repair strategy is prompt tweaking.
The survey separates failure views:
| View | Question |
|---|---|
| System structure | Did the agent, tool, memory, role, or communication channel fail? |
| Execution stage | Did failure enter during planning, action, observation, verification, or synthesis? |
| Causal lifecycle | Was this a root cause, propagation path, amplification step, or detection failure? |
That last row is the right mental model. In MAS, the visible error is often not the root cause. It is the final place where a hidden dependency became user-visible.
Attribution methods
The survey groups attribution techniques into three families.
| Family | Basic idea | Where it helps |
|---|---|---|
| Data-driven attribution | Learn patterns from traces, logs, trajectories, and failures | Large systems with enough examples |
| Constraint-guided diagnosis | Use schemas, invariants, tests, contracts, and rubrics | Engineering systems with explicit expectations |
| Causal attribution | Model interventions and counterfactuals | Understanding whether a step actually caused failure |
For practical agent tooling, I would start with constraint-guided diagnosis:
structured traces
claim/evidence links
tool-call schemas
test results
role contracts
stop conditionsThis is less glamorous than causal discovery, but it is where engineering leverage starts.
Self-evolution
Self-evolution is the “E” stage. A system should not only notice failures; it should transform failures into better future behavior.
The survey separates three levels:
| Level | What changes | Examples |
|---|---|---|
| Agentic evolution | The individual agent | Prompt rules, memory, tools, reasoning procedures |
| Systemic evolution | The multi-agent organization | Roles, topology, routing, communication protocol |
| Meta evolution | The evolution process itself | How improvements are proposed, evaluated, accepted, and rolled back |
The danger is obvious: self-improvement without gates can degrade the system.
So the evolution loop needs structure:
failure trace
-> attribution
-> candidate change
-> evaluation
-> gated promotion
-> monitoring
-> rollback if neededFor agent systems, “learning from mistakes” should mean a tested change to a durable artifact, not just a longer prompt.
Open problems
The survey’s challenges are concrete:
| Challenge | Why it matters |
|---|---|
| Closed-loop benchmarks | Most benchmarks do not test attribution and evolution after failure |
| Attribution ground truth | It is hard to know the true root cause in multi-agent traces |
| Telemetry standards | Systems log different things, making comparison difficult |
| Safe evolution | Self-modifying systems need gates, scopes, and rollback |
| Correlated errors | Multiple agents can share the same blind spots |
The telemetry point feels under-discussed. Multi-agent systems need something like observability for reasoning and coordination:
who knew what
when they knew it
what evidence they used
what tool result changed state
what claim entered memory
what verifier checked
what synthesis discardedWithout that, attribution becomes archaeology.
What I would reuse in an agent runtime
Here is the concrete design translation for my own agent-swarm work.
1. Build trace before adding more agents
Every meaningful claim or action should have a trace record:
agent id
role
input
artifact produced
evidence used
tool calls
confidence
open doubts
downstream consumersIf the system cannot trace a failure, it is not ready to evolve from that failure.
2. Use hybrid topology
Fully centralized orchestration is easy to inspect but can bottleneck. Fully distributed collaboration is flexible but hard to control.
A hybrid runtime is more attractive:
central orchestrator for state, budget, policy, and stop conditions
local agents for specialized work
verifiers with separate context and authority3. Make roles executable
Roles should not be labels in a prompt. They should imply permissions, input shape, output schema, and acceptance criteria.
Reviewer:
can read all artifacts
cannot modify worker output
must return findings with severity and evidence
Worker:
can edit scoped files
must produce tests or explanation
cannot approve its own patch4. Treat failure attribution as a layer
Do not bolt diagnosis onto the end. Make it part of the runtime:
final answer wrong
-> inspect trace
-> localize failure
-> classify failure mode
-> propose narrow repair
-> evaluate repair5. Gate self-evolution
Evolution should be promoted like code:
candidate rule
-> replay on past failures
-> check for regressions
-> stage behind flag
-> monitor
-> promote or revertThis prevents a system from overfitting to its last mistake.
Minimal roadmap
If I were building a LIFE-inspired swarm runtime, I would start here:
| Milestone | Artifact |
|---|---|
| Trace schema | A structured record for messages, claims, tools, artifacts, and dependencies |
| Role registry | Executable role definitions with permissions and output schemas |
| Verifier layer | Separate agents or tools that check claims, diffs, tests, and evidence |
| Failure taxonomy | A small set of recurring failure modes tied to trace fields |
| Evolution queue | Candidate prompt/tool/workflow changes with eval gates |
| Replay harness | Ability to rerun old failures against new rules |
That is more useful than adding ten agents to a chat room.
Final judgment
The LIFE survey gives a better question for multi-agent systems:
Can the system turn collaboration failures into diagnosed, evaluated, and gated improvements?
If not, the system may still be impressive, but it is not yet a reliable learning organization.
The paper’s strongest contribution is the lifecycle framing. It says that the future of MAS is not just collaboration. It is collaboration plus attribution plus evolution.
That is the difference between a swarm that produces output and a system that can become more trustworthy over time.
References
- Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems, arXiv
2605.14892. mira-ai-lab/awesome-mas-life.