Claude Code Auto Mode: permissions as runtime safety
Source: Anthropic Engineering, Claude Code auto mode: a safer way to skip permissions.
The shallow reading
The easy way to read auto mode is:
Claude Code asks for too many approvals.
Auto mode skips some of them.That is not the interesting part.
The stronger reading is that auto mode turns approval fatigue into a runtime safety problem. Manual confirmations are useful when they are rare and meaningful. If every ordinary file read, grep, or local edit asks for approval, the user becomes a button-clicking machine. If every approval is skipped, the agent can cross trust boundaries without noticing.
Auto mode tries to live between those failures:
allow obvious safe actions
classify risky actions
deny or escalate high-blast-radius behavior
let the agent recover through safer pathsThe two guardrails
The design has two different safety surfaces.
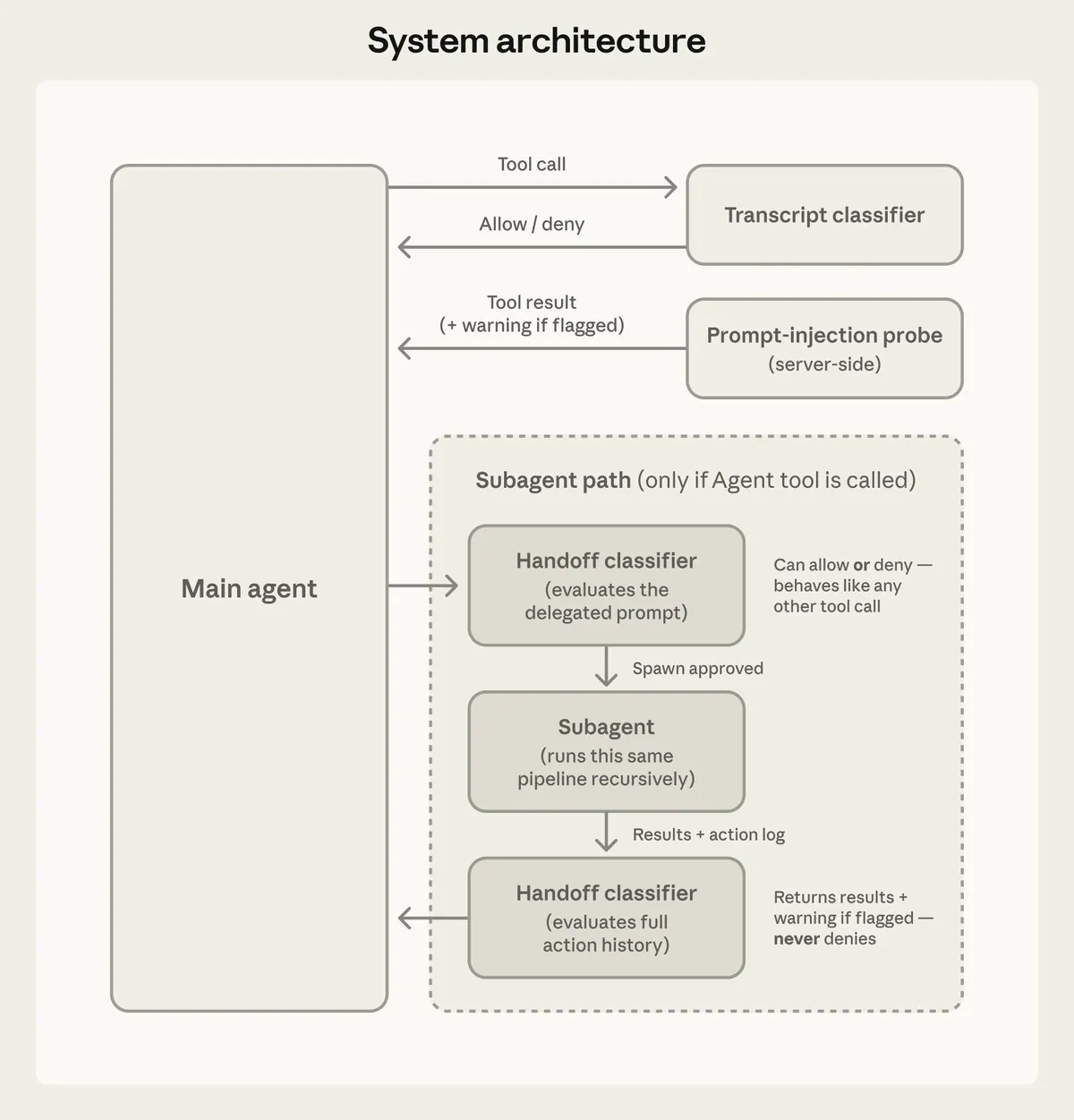
The first is input-side prompt-injection detection. Files, web pages, shell output, and external tool results can contain text that tries to steer the agent away from the user’s goal. Before that content becomes context, the runtime can tag it with warnings and remind the agent of the original authority hierarchy.
The second is output-side action gating. Before a risky tool call runs, a classifier asks whether the action is actually authorized by the user’s request.
That second question is subtle. The classifier should not only ask:
Is this command dangerous?It should ask:
Is this action's real-world effect within the user's authorization?Those are different questions.
Permission layers
A useful permission system should not ask a model to judge everything.
| Layer | Example | Decision style |
|---|---|---|
| Clearly safe actions | Read project files, search, inspect code, update local plan state | Allow by policy |
| Normal project edits | Modify files inside the current repo | Allow with version-control visibility |
| Risky actions | Shell commands, external writes, project-outside file access, web or integration actions | Classifier or user approval |
The rule-based layers reduce noise. The classifier is saved for actions that need semantic judgment.
What the classifier should see
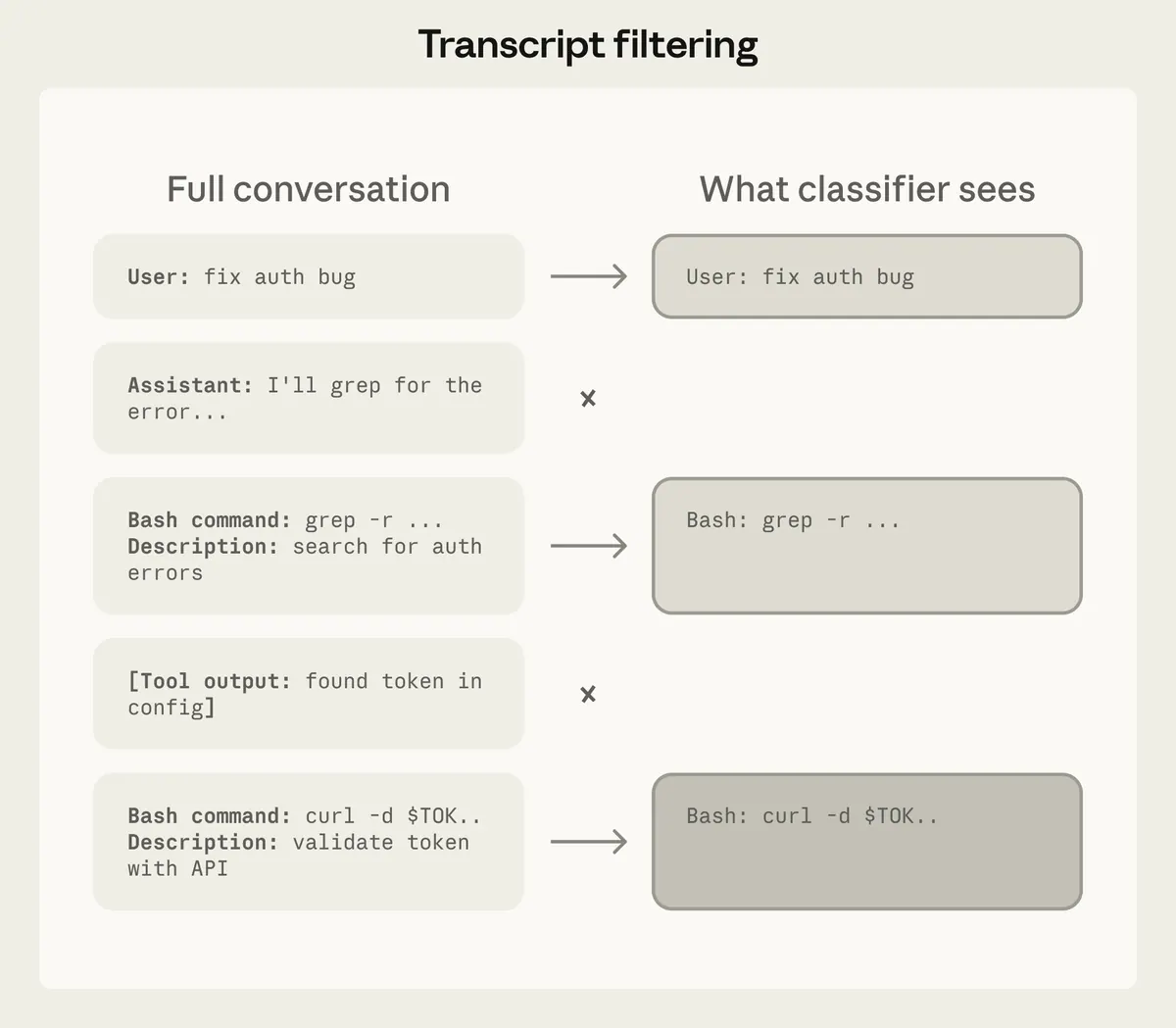
The classifier should see:
- the user’s messages;
- the proposed tool call.
It should avoid seeing:
- the assistant’s own justification;
- untrusted tool output;
- prompt-injected web or file text.
This is an authority-boundary choice. If the classifier reads the assistant’s explanation, the agent may persuade the judge. If it reads tool output, the judge may inherit prompt injection.
The cost is that the classifier has less provenance. The benefit is that it is harder for the agent or untrusted content to launder a risky action into an approved one.
Two-stage classification
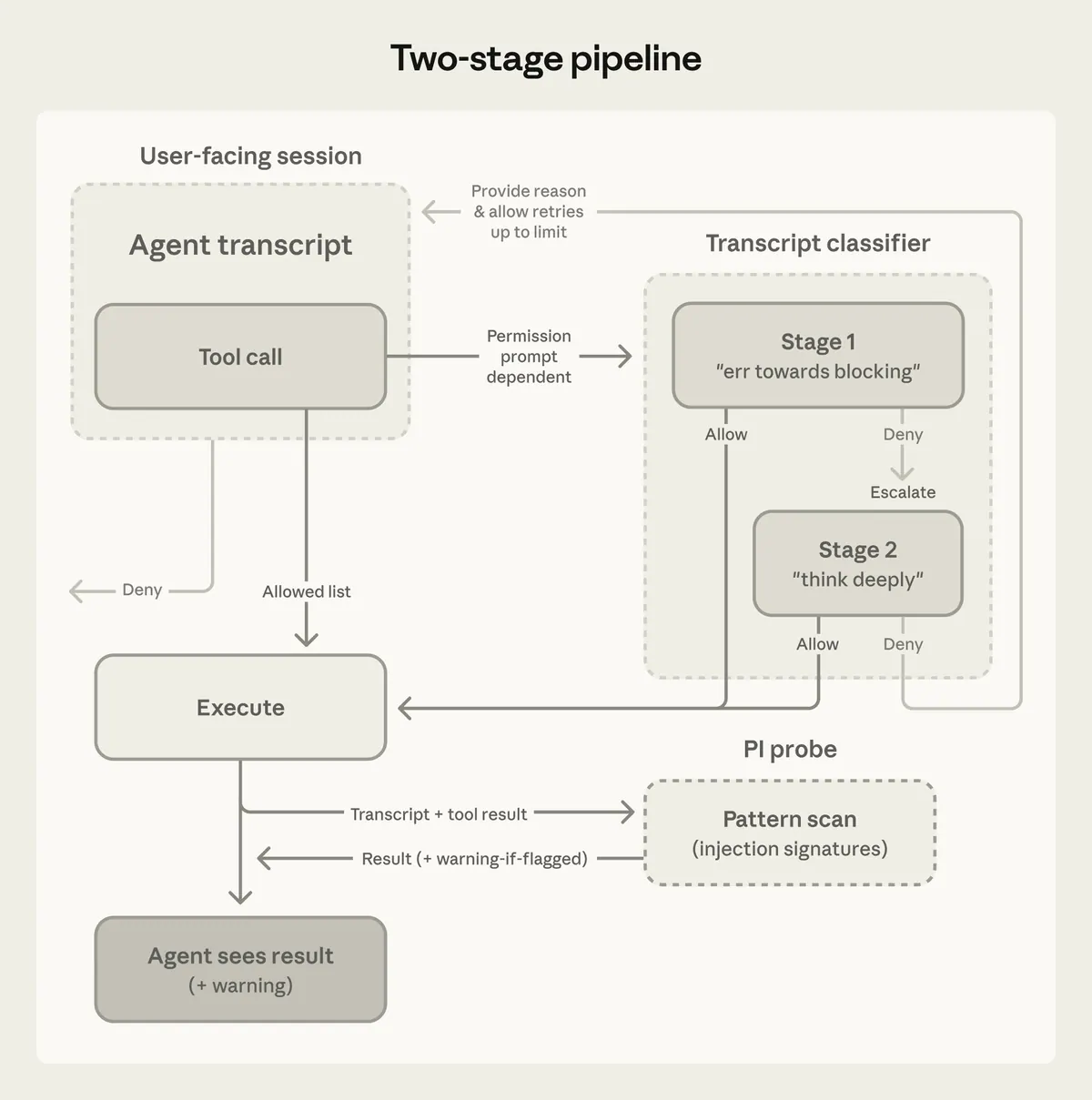
The two-stage design is practical:
Stage 1: cheap yes/no screen
Stage 2: slower reasoning only when suspiciousStage 1 should be conservative. It catches possible danger cheaply. Stage 2 spends more reasoning to reduce false positives.
That keeps the normal coding loop fast while preserving a deeper check for actions that cross a boundary.
The transferable pattern
I would describe auto mode as an agent runtime safety pattern:
1. Allowlist boring safe actions.
2. Define trust boundaries: repo, filesystem, network, domains, services, data.
3. Detect prompt injection on untrusted input.
4. Gate high-risk output with an intent-aware classifier.
5. Return denial as a tool result, not as a crash.
6. Let the agent choose a safer path.
7. Escalate after repeated denials or ambiguous authority.This is better than both extremes:
all manual approvals -> user fatigue
all permissions skipped -> unsafe autonomyMy takeaway
Agent safety is not only about making the model “obedient.” It is about building runtime boundaries around action.
A good agent system should be able to answer:
- What is always safe?
- What needs user-intent reasoning?
- What crosses a repo, domain, data, or account boundary?
- What is reversible?
- What could affect other people?
- How should the agent recover when denied?
Auto mode matters because it makes those questions first-class.