LeanMarathon: 把长程 Lean 形式化变成可恢复的多智能体工程
Paper: LeanMarathon: Toward Reliable AI Co-Mathematicians through Long-Horizon Lean Autoformalization
arXiv:
2606.05400Code:
YuanheZ/LeanMarathon阅读定位:这篇文章不是在提出一个更强的单点 theorem prover,而是在回答一个更系统的问题:当 AI 要把整篇研究论文形式化成 Lean proof 时,怎样设计一个能长期运行、可审计、可恢复、不漂移的 multi-agent harness? (arXiv)
0. 本文一句话
LeanMarathon 的核心思想是:
research paper
↓
evolving Lean blueprint
↓
proof DAG
↓
contract-scoped agents
↓
CI-gated local PRs
↓
sorry-free Lean formalization它把“让一个大模型一次性证明整篇论文”改写成“让多个有边界的 agent 围绕同一个 blueprint 做小步、可验证、可回滚的工程交易”。论文最终在两篇 2026 年研究论文、四个 Erdős problems、七个目标定理上完成了 no sorry 的 Lean 形式化,共证明 258 个不同的 lemma / theorem。(arXiv)
Takeaway:
强 prover 不够。
长程数学形式化需要 durable harness。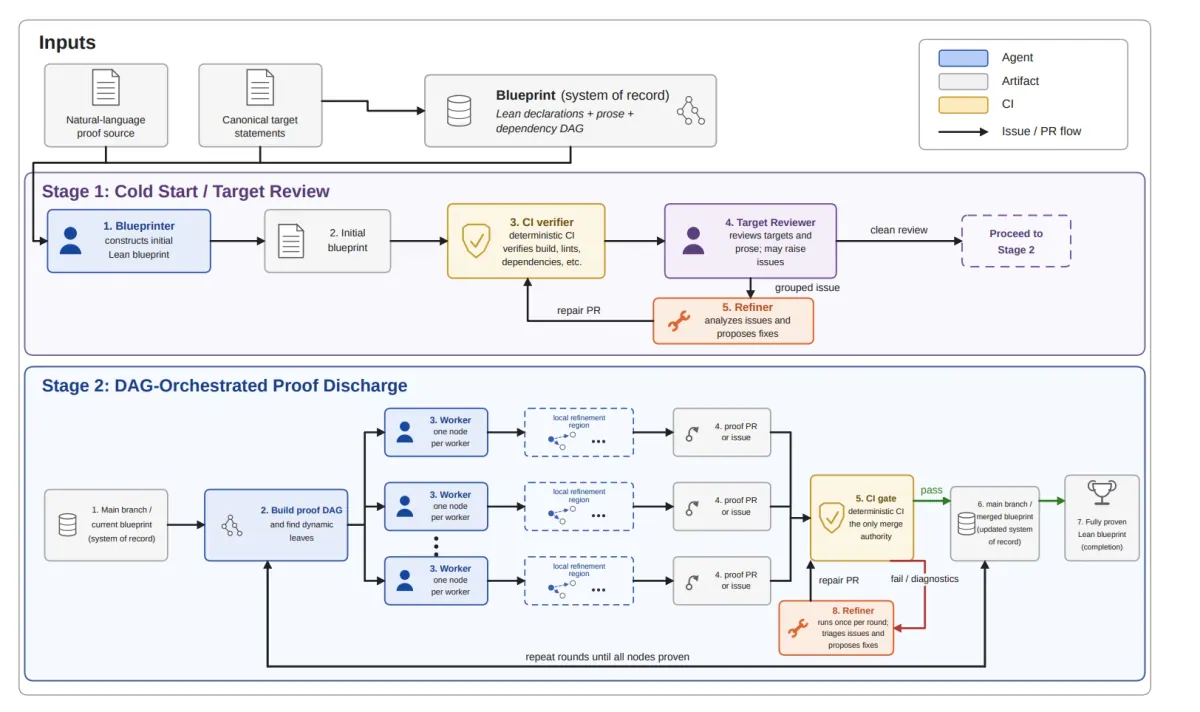
1. Motivation(动机)
这篇论文的出发点是 AI-assisted mathematics 的一个关键断层。
现在 LLM 已经能生成很长的自然语言数学证明,甚至参与研究级问题。但是一个自然语言证明“看起来对”并不等价于它真的可验证。尤其是 AI 生成的数学结果,需要一个更强的 correctness guarantee:把证明翻译成 Lean 4,并让整个文件在 proof assistant 中通过检查。论文把这个阶段称为 verification:把自然语言证明变成 machine-checked artifact。(arXiv)
问题在于,研究级论文的形式化不是“证明一个 lemma”。一篇论文可能包含上百个互相依赖的 definitions、lemmas、theorems。只要一个中间 statement formalize 错了,后面所有证明都可能变成“形式上正确,但数学上证明了另一个东西”。这就是论文反复强调的 formalization shift / goal drift。(arXiv)
这篇文章的核心 motivation 可以压缩成一句话:
AI 数学真正需要的不是一次性输出答案,
而是一个能长期保持目标一致性的验证系统。作者把这个能力叫做 agent durability:一个 autonomous system 是否能在多小时、多轮编辑、多节点依赖、多次失败修复中,仍然保持 coherent、recoverable、faithful。(arXiv)
2. 现有领域的不足
现有方法的问题不只是“模型还不够聪明”,而是系统形态不适合长程形式化。
2.1 单点 prover 只解决局部目标
很多 neural theorem proving / autoformalization 工作关注的是 statement translation、单个 Lean goal、局部 tactic search,目标通常停留在 isolated lemmas 或 IMO-level problems。它们对“整篇研究论文如何维护一个不断演化的 proof graph”处理得不够。(arXiv)
2.2 Textbook formalization 默认已有细粒度 proof plan
一些 textbook-level formalization 给 agent 提供了完整、细粒度的推理蓝图,agent 主要做翻译。但 research-level formalization 中,这个 blueprint 往往不存在。source proof 可能有省略、有隐含步骤、有 gap,甚至有错误。系统需要自己发现并维护 proof DAG。(arXiv)
2.3 Monolithic agent 容易发生不可恢复漂移
如果让一个 agent 同时负责读论文、设计 proof graph、写 Lean、检查自己、修复自己,就会出现三个典型问题:
| Failure | 含义 |
|---|---|
| Coherence loss | 局部修复破坏全局结构 |
| Self-evaluation bias | agent 过度相信自己的 formalization |
| Irreversibility | 一旦 proof graph 偏离目标,后续工作会继续沿着错误方向推进 |
论文的判断很明确:不要假设一个 agent 永远不犯错,而要设计一个系统,让错误不能扩散。(arXiv)
2.4 闭源 paper-level agent 缺少 harness 细节
论文提到 AxiomProver、Gauss、Aristotle 等系统已经进入 paper-level formalization 区间,但很多是 closed-source company products,外部很难看清它们的 harness design。LeanMarathon 的价值之一,就是把 long-horizon autoformalization 的工程结构显式写出来。(arXiv)
Takeaway:
research-level autoformalization 的瓶颈
不是单个 proof attempt,
而是长程系统如何防止 drift。3. Contributions(贡献)
这篇论文的贡献可以概括为四点。
3.1 提出 LeanMarathon
LeanMarathon 是一个 multi-agent harness,用于把自然语言数学证明转成 Lean 4 中 fully-proven blueprint。它的目标不是取代 Lean verifier,而是围绕 Lean verifier 建立一个可长期运行的 agent workflow。(arXiv)
3.2 提出 evolving blueprint 作为 system of record
论文最核心的抽象是 blueprint:一个 Lean file 同时扮演三种角色。
| 角色 | 含义 |
|---|---|
| formal proof skeleton | Lean declarations、types、proof bodies |
| natural-language proof graph | 每个 node 保留 LaTeX statement / proof prose |
| shared system of record | 所有 agent 共享的唯一持久状态 |
每个 theorem / lemma 是 proof DAG 中的一个 node。Lean type、LaTeX statement、LaTeX proof prose、dependency citations 都放在同一个 declaration 附近。这样 formal graph 和 natural-language graph 不能各走各的。(arXiv)
3.3 用 contract-scoped agents 做 fault containment
LeanMarathon 有四类 agent:Blueprinter、Target-Reviewer、Worker、Refiner。每个 agent 都有固定输入、固定输出、固定编辑范围和明确 failure mode。这样一个 agent 的失败最多变成 rejected patch 或 issue,而不是污染整个 proof development。(arXiv)
3.4 在真实研究论文上验证
论文在两篇 AI-assisted research mathematics papers 上测试 LeanMarathon,覆盖四个 Erdős problems:#1051、#1196、#164、#1217。最终七个 target theorems 都完成 no sorry formalization;作为对比,商业单 agent baseline Aristotle 在相同输入上失败。(arXiv)
Takeaway:
LeanMarathon 的贡献不是“一个 agent 会证明更多 theorem”,
而是“一个系统能把很多不可靠局部尝试组织成可靠全局产物”。4. Method(方法)
4.1 整体流程
LeanMarathon 的输入是:
1. natural-language proof source
2. canonical target statements输出是:
a Lean blueprint
where every proof node is proven
and no sorry / sorryusing remains整体分成两个 stage:
Stage 1: Cold Start / Target Review
Blueprinter 生成初始 blueprint
Target-Reviewer 审核 target fidelity
Refiner 修复 mismatch
直到 target review clean
Stage 2: DAG-Orchestrated Proof Discharge
抽取当前 proof DAG
找到 dynamic leaves
并行分配给 Workers
Worker 提交 PR 或 issue
CI gate 决定是否 merge
Refiner 每轮处理 issues
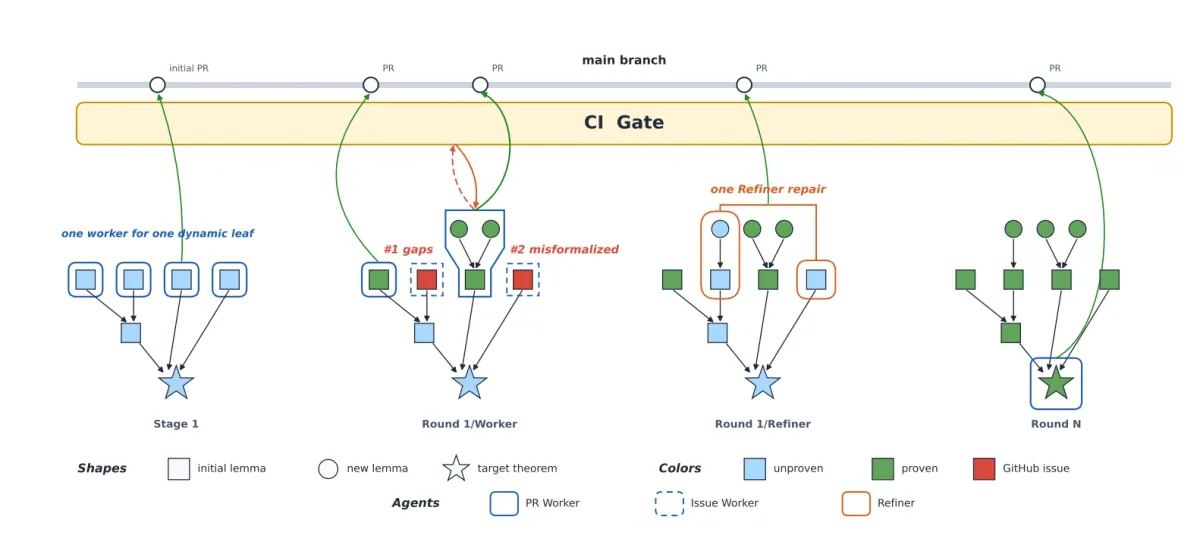
重复直到所有 nodes proven论文中的 Figure 1 和 Figure 5 都在强调同一件事:主线不是 prompt chain,而是 DAG + PR + CI。
4.2 Blueprint:把 Lean file 变成共享状态
Blueprint 中每个 proof node 大致长这样:
@[blueprint "lem:weighted-tail-bound"
(statement := /-- LaTeX statement text -/)
(proof := /-- LaTeX proof prose with references -/)
(title := /-- one-line LaTeX title -/)
(latexEnv := "lemma")]
lemma weightedtailbound ... : ... := by
sorryusing [auxlemmaone, auxlemmatwo]这里有两个关键设计:
第一,Lean declaration 负责 formal statement,LaTeX fields 负责 human-readable proof intent。agent 不是只写 Lean,也要维护自然语言 proof graph。
第二,dependency 不是随便写注释。系统会检查 LaTeX prose 中的引用和 Lean elaborator 抽取出的依赖是否双向一致。如果 prose 说依赖 A,但 Lean proof 没依赖 A,或者 Lean proof 实际依赖 B 但 prose 没写,CI 都会拒绝。(arXiv)
Takeaway:
Blueprint = proof skeleton + prose graph + dependency contract4.3 四类 agent
| Agent | 主要职责 | 关键边界 |
|---|---|---|
| Blueprinter | 从 source proof 和 canonical targets 生成初始 Lean skeleton | 只负责 decomposition,不负责证明 |
| Target-Reviewer | 审核 Lean type 是否忠实表达 target theorem | read-only,只能 file issue |
| Worker | 证明一个 dynamic leaf node | 只能改本 node 的 prose、proof body 和 local refinement region |
| Refiner | 修复 blueprint-level defects | 可以改 connected illness sub-DAG,但要经过 CI |
这四个角色的重点不是“分工更细”,而是每个 agent 都被限制在一个 contract 里。Blueprinter 做初始拆解,Target-Reviewer 防止一开始就证明错 theorem,Worker 做局部证明,Refiner 处理跨节点 drift 或 source gap。(arXiv)
4.4 Worker:一个 node 一个局部交易
Worker 被分配到一个 proof DAG 的 dynamic leaf,也就是依赖已经证明完、但自己还没有 proof 的 node。它的 workflow 分四步:
| Phase | 目的 |
|---|---|
| Misformalization audit | 先怀疑 Lean type 是否正确 |
| Cheap falsification | 用有限、数值、边界 case 尝试低成本反驳 |
| Statement polish | 让 prose 精确描述 Lean statement |
| Formalization | 在 frozen statement 下补全 Lean proof |
Takeaway:
Worker 不能随意改 target type,也不能改别的 node。它可以在本 node 前面局部增加 helper lemmas,形成 local refinement DAG。这样做的好处是:并行 Workers 修改的是 disjoint editable regions,因此 PR 可以并行落地,失败也只会局部失败。(arXiv)
Worker 不是自由写文件,
而是在一个 frozen substrate 上做 local proof transaction。4.5 Refiner:修复 drift,而不是胡乱 patch
Refiner 处理 Target-Reviewer 或 Worker 提交的 issue。它会先找到 affected region,也就是论文里说的 illness area:最小的 connected sub-DAG。
Refiner 需要区分两类问题:
| 类型 | 含义 |
|---|---|
| blueprint drift | Lean blueprint 偏离了 source proof |
| source gap | source proof 本身在形式化粒度下缺步骤、不清楚或有错误 |
一个重要纪律是:如果某个已完成 proof 因上游 statement 改动而不再 compile,Refiner 不允许局部乱修这个 proof body,而是 wholesale-replace 成 placeholder,交回后续 Worker 重新证明。这样牺牲了一些重复计算,但避免把不可靠 patch 混进已完成证明。(arXiv)
4.6 CI gate:把 agent 输出变成可验证交易
LeanMarathon 的 CI verifier 不只是跑 Lean build。它编码了 blueprint contract,包含七类检查:
| Check | 作用 |
|---|---|
| Lean compilation | 文件必须能编译,允许显式 sorry warning |
| Node well-formedness | blueprint metadata 必须完整 |
latexEnv consistency | Lean keyword 和 LaTeX environment 一致 |
| Label-name normalization | blueprint label 和 Lean name 对齐 |
| Unique labels | 每个 node label 唯一 |
| Proof-dependency parity | prose dependencies 和 Lean dependencies 双向一致 |
| Lemma closeness | lemma 必须通向后续 lemma / theorem,避免 orphan lemmas |
这里最有意思的是 lemma closeness:如果一个 agent 漂移了,往往会开始证明一些和目标无关的 machinery。orphan lemma 就是这种漂移的结构痕迹。CI 不理解数学语义,但它可以在 graph 层面阻止“证明了一堆无关东西”。(arXiv)
5. 实验结果
5.1 Evaluation setup
作者选择了两篇 2026 年的研究级数学论文,都是 Erdős problems 相关,并且都带有 AI-assisted provenance。每次 run 的输入是论文 LaTeX source 和 canonical target statements,成功标准是:所有 blueprint proof nodes 都有完整 Lean proof,且没有 sorry / sorry_using。(arXiv)
5.2 Formalization outcomes
| Run | Targets | Lean lines | Proof nodes | Remaining sorry | Status |
|---|---|---|---|---|---|
| Erdős–Graham | 4 | 8,513 | 111 | 0 | complete |
| ESS #1196 | 1 | 3,988 | 44 | 0 | complete |
| #164 & #1217 | 2 | 14,592 | 147 | 0 | complete |
注意:第三个 run 是 incremental development。它以 #1196 的 blueprint 为 seed,再扩展到 #164 和 #1217。因此论文统计 distinct proofs 时是 111 + 44 + 103 = 258 个不同 lemmas / theorems。(arXiv)
Takeaway:
LeanMarathon 不只是从零形式化一篇论文,
也能在已有 blueprint 上继续扩展新 target。5.3 Orchestration cost
| Run | Rounds | Workers | Refiners | Merged PRs | Tokens | Cost |
|---|---|---|---|---|---|---|
| Erdős–Graham | 19 | 58 | 7 | 53 | 308M | $257.17 |
| ESS #1196 | 17 | 33 | 6 | 32 | 245M | $189.43 |
| #164 & #1217 | 40 | 111 | 25 | 93 | 796M | $623.54 |
最难的是 #164 & #1217 run:40 rounds,111 Workers,25 Refiners,93 merged PRs。论文还报告了一个关键工程结果:三次 run 中共有 135 个 Worker PR 在不断移动的 main 上直接 squash-merge,没有出现 merge conflict。(arXiv)
这说明 frozen editable region 不是形式上的约束,而是真正让 parallel proof discharge 可行的工程机制。
5.4 Formalization 反过来发现数学问题
实验里最有价值的部分不是数字,而是 Lean feedback 如何推动数学变清楚。
论文报告了几类 recurring issues:
| Issue type | 例子 |
|---|---|
| false statement | 某些估计实例化后变成 1 ≤ 0 或 4/3 ≤ 2/3 |
| hidden totalization | Real tsum 或 limsup 在 Lean 中 totalize 成 0,暴露出 prose 中缺少 summability / boundedness 条件 |
| Mathlib-absent facts | Dirichlet eta monotonicity 等需要额外构造概率论 argument |
这说明 proof assistant 不只是 checker,也是在给 agent 提供 ground-truth mathematical signal。(arXiv)
一个特别典型的例子是 #1217:论文中约 62 行 prose、没有中间 lemmas 的证明,在 blueprint 中展开成约 84 个 nodes。论文里的 “routine calculation” 被展开成约 14 个 explicit lemmas,“an induction gives” 被展开成 22-node construction。形式化真正消耗精力的地方,不一定是作者详细写出的 number theory,而是那些被自然语言证明压缩掉的 probability / analysis 边界。(arXiv)
Takeaway:
formalization 的价值不只是验证结论,
也包括把论文中的压缩步骤展开成可检查结构。5.5 和 Aristotle baseline 的对比
论文用 Aristotle 作为 commercial single-agent baseline。相同输入下,Aristotle 在 Erdős–Graham 上运行超过 40 小时仍留下 sorry,在 #1196 上运行超过 24 小时也没有完成。LeanMarathon 在对应 comparison set 中完成了所有目标。(arXiv)
| Task | Aristotle | LeanMarathon |
|---|---|---|
| Erdős–Graham | 0 / 3 targets, 2 sorry | 3 / 3 targets, 0 sorry |
| ESS #1196 | 0 / 1 targets, 1 sorry | 1 / 1 targets, 0 sorry |
这个对比的重点不是“某个模型更强”,而是 single-agent approach 很难处理长程 proof graph 的 drift、repair、dependency management。LeanMarathon 把这些问题拆成了 blueprint、issue、PR、CI、Refiner loop。(arXiv)
5.6 Ablation:哪些设计真的重要?
论文还给了一个很有信息量的 ablation。早期 harness 在 Erdős–Graham 上跑了约 12 天,filed 137 issues,重启 blueprint 约 8 次,最后仍然有 26 个 sorry。当前 harness 约 3 天完成,16 issues,1 次 blueprint restart,0 sorry。(arXiv)
两个关键改动:
| 设计 | 为什么重要 |
|---|---|
| Refiner 必须能看 source proof | 否则它无法区分 blueprint drift 和 source gap,只能在错误 DAG 上继续发明 machinery |
| Worker 不能用 physical-line budget 作为放弃理由 | 否则 “proof 太长” 会变成逃避 formalization 的出口 |
Takeaway:
Refiner needs source.
Worker needs evidence-based stopping.5.7 Limitation:library 缺失时 harness 也救不了
论文还报告了一个 failure case:尝试形式化一个 unit-distance disproof 时失败。原因不是 orchestration 本身,而是 hardest prerequisite 依赖 Mathlib 中几乎不存在的深层 algebraic number theory。系统可以组织工作,但不能凭空补齐 library 缺失的大块数学基础。(arXiv)
这个 limitation 很重要,因为它给 LeanMarathon 划定了边界:
如果 proof source 的主要困难在已有 library 附近,
harness 可以把它分解、验证、修复。
如果 proof source 依赖大量 library 中没有的理论,
harness 只能暴露缺口,不能直接替代整个数学库建设。6. 最后的判断
这篇论文最值得记的点是:
Long-horizon autoformalization is a systems problem.过去很多 AI-for-math 工作把重点放在 model capability:模型会不会证明、会不会 search、会不会写 tactic。LeanMarathon 的视角更像 agent system engineering:怎样定义共享状态、怎样限制编辑边界、怎样让失败变成 issue、怎样让 CI 成为唯一 merge authority、怎样让 proof DAG 在多轮修复中不失真。
对 multi-agent systems 来说,这篇文章也很有启发:
| MAS 问题 | LeanMarathon 的回答 |
|---|---|
| shared memory 容易污染 | 用 blueprint + GitHub issue / PR 作为唯一持久状态 |
| agent 自评不可靠 | 让 CI 和外部 reviewer 决定是否接受 |
| 并行 agent 容易冲突 | 用 frozen substrate + local editable region |
| 长任务容易漂移 | 用 target review、dependency parity、lemma closeness 约束 DAG |
| 修复容易扩大损伤 | 用 illness sub-DAG 和 wholesale downgrade 控制 blast radius |
我的一句话评价:
LeanMarathon 不是“多 agent 证明数学”的简单堆叠,
而是把数学形式化变成了一个可追踪、可恢复、可验证的工程系统。