Graph of Agents
GoA 把多 LLM 协作从“把所有 agent 的答案拼起来再聚合”,改写成一次测试时动态建图。每个模型是一个节点,模型之间的回答相关性变成有向边,信息沿着边来回传递,最后再用 graph pooling 得到统一答案。它瞄准的是 LLM zoo 时代的一个很现实的问题:模型越来越多,真正困难的不是再接入一个模型,而是每道题该叫谁、谁该听谁、最后该信谁。
-
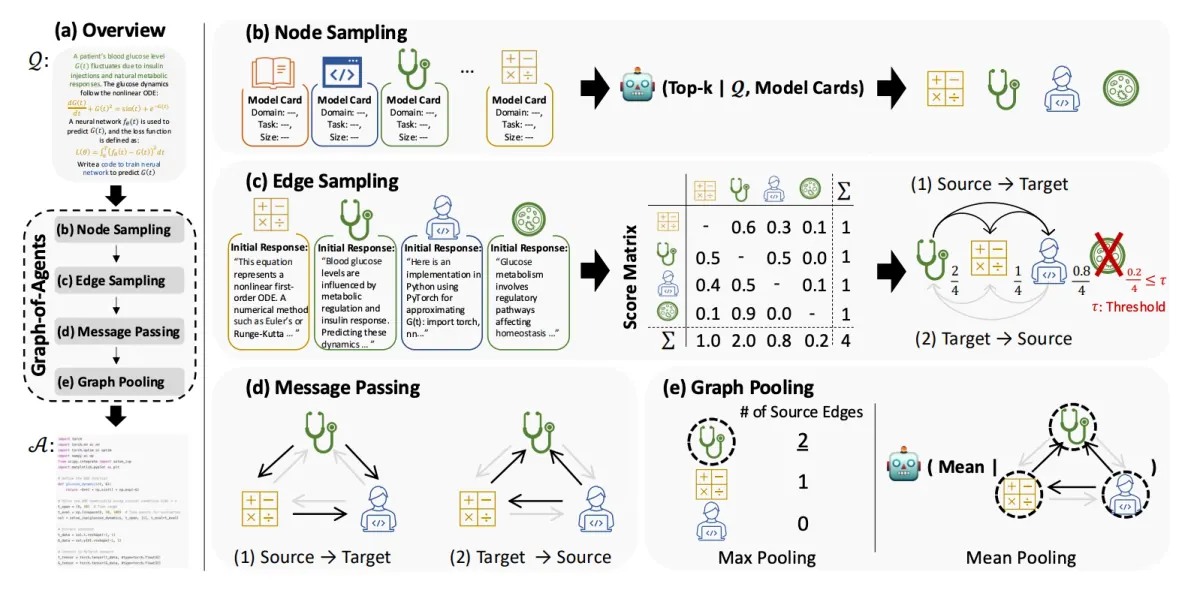
选择本身成为推理的一部分: GoA 先用 HF model cards 描述每个模型的领域、任务专长和参数规模,再让一个通用 meta-LLM 按 query 选择 top-k agent。论文和代码默认强调 top-k=3,而不是把 6 个模型全拉进来;这一步直接过滤掉与问题无关的法律、金融、代码或医学模型,避免 MoA 式全员广播带来的噪声和成本。
-
边不是固定拓扑,而是互评出来的信任关系: 被选中的 agent 先各自作答,然后每个 agent 给其他 agent 的回答打分,依据是 correctness、coherence 和 relevance,分数归一化后形成 relevance score。GoA 再按这些分数排序、剪掉低于阈值的弱节点,并把高相关 agent 设为 source,低相关 agent 设为 target;也就是说,图结构不是预设架构,而是每道题现场长出来的通信结构。
-
消息传递有方向,而且方向很关键: GoA 先做 Source-to-Target,让更可靠的高相关回答去修正低相关节点,再做 Target-to-Source,把低相关节点吸收后的改进反馈回高相关节点。消融里反向传递是最大伤害项,在 MMLU-Pro 上掉 2.60,在 GPQA 上掉 5.05;这说明收益不是来自“多聊几轮”,而是来自正确的信息流方向和 relevance-aware weighting。
-
少用 agent 反而更强: 在 MMLU、MMLU-Pro、GPQA、MATH、HumanEval、MedMCQA 上,GoA 用 3 个 agent 超过多种 6-agent baseline。GoA-Max 在 MMLU 79.18、MMLU-Pro 54.78、MedMCQA 60.04 上最好,GoA-Mean 在 GPQA 40.54、MATH 73.12、HumanEval 84.98 上最好;MMLU-Pro 的效率对比也很直接,MoA 需要 19 次调用、56.05k tokens、240.26 秒,而 GoA-Max 降到 11 次调用、19.18k tokens、100.43 秒,同时准确率还更高。
为什么重要: 这篇论文的实际启发不是“多 agent 更好”,而是“多 agent 系统需要可学习或可构造的通信结构”。GoA 把 agent selection、peer scoring、directed message passing 和 pooling 串成一个纯 prompt-interface 的测试时框架,不需要微调,也兼容黑盒 API;它还说明 MoA 可以被看作 GoA 的一个退化特例:选中全部节点、全连接、边权相同、mean pooling。对 agent builder 来说,真正的杠杆不在堆更多模型,而在把模型池组织成一个每题自适应的小图。