Dynamic Workflows: Agent 系统从 Prompt 到 Runtime
Anthropic 最近在 Claude Code 中提出的 Dynamic Workflows,表面上是一个产品功能:模型可以临时写出一个 workflow,用来协调多个 subagents 完成任务。但如果把具体工具抽掉,它更像是一个值得单独讨论的 agent-system design pattern:
Dynamic Workflow 是一种 online workflow synthesis:系统根据当前任务动态生成一个 task-specific orchestration layer,把原本发生在单一上下文中的计划、执行、验证和收敛过程,外置成一个可调度、可追踪、可恢复的执行系统。
我觉得这件事的关键不在于“怎么在 Claude 里调用”,而在于它把 long-horizon agent 的问题重新表述了。过去我们经常把复杂任务失败归因于模型不够聪明、context 不够长、prompt 不够细;Dynamic Workflows 指向的是另一条路径:很多失败不是 reasoning failure,而是 execution organization failure。
1. 核心思想:把 Agent 的执行过程编译成 Workflow
传统 agent 交互中,模型通常在同一个 context window 里同时完成几件事:理解目标、维护计划、调用工具、记录中间状态、修改错误、验证结果、决定何时停止。这个结构对短任务有效,但在长任务、并行任务和强验证任务中会逐渐暴露出系统性问题。
Dynamic Workflow 的核心变化是:系统不再只让一个 agent 在上下文里“想办法完成任务”,而是让模型先生成一个面向当前任务的 workflow runtime。这个 runtime 再负责拆解任务、spawn subagents、隔离上下文、收集中间产物、触发验证、处理重试和合并最终结果。
因此,它不是一个更复杂的 prompt,而是一个 task-level compiler:自然语言目标被编译成一个临时的 multi-agent execution graph。这个 graph 可以包含并行 worker、adversarial verifier、pairwise judge、classifier、synthesizer、stop-condition checker 等不同角色。任务的组织结构从“隐含在模型上下文里”变成了“显式存在于 runtime 状态里”。
这也是为什么 Dynamic Workflows 对 multi-agent systems 有启发:它强调的不是“有很多 agent”,而是 agent 之间的调度关系、状态边界和验证协议。
2. 它为什么能缓解 Long-horizon Agent 的典型失败?
Dynamic Workflows 主要缓解三类失败:agentic laziness、self-preferential bias 和 goal drift。它们本质上都与单一上下文里的状态管理和自我验证有关。
Agentic laziness 指的是模型在复杂多步任务中提前收敛。它可能完成了 40% 的检查,却给出一个看似完整的结论。这里的问题不是模型完全不知道剩余任务,而是上下文中的任务队列、覆盖率和完成条件都太软,模型容易把“已经做了一些”误判成“已经足够”。
Dynamic Workflow 的做法是把任务队列和完成条件外置。比如一个安全审计任务可以被拆成多个文件、模块或规则,每个 shard 都有独立状态,只有当所有 shard 都完成并通过验证时,workflow 才进入 synthesis。换句话说,停止条件不再由一个疲劳的上下文主观判断,而由 runtime 维护。
Self-preferential bias 指的是模型倾向于相信自己已经产生的结论。让同一个 agent 生成假设、验证假设并最终总结,天然会产生自我确认。Dynamic Workflow 通过角色分离降低这种偏差:提出假设的 agent 和反驳假设的 agent 处于不同上下文,verifier 的目标不是润色,而是攻击上游输出。
Goal drift 则常发生在长对话和 compaction 之后。原始目标中的边界条件、禁止项和 edge cases 可能逐渐消失。Dynamic Workflow 通过将 goal、constraints、rubric、budget 和 stop condition 固化在 workflow state 中,让局部 subagent 不需要承担完整全局记忆,而由 orchestrator 维持任务不偏航。
这三个机制合在一起,可以概括为一句话:Dynamic Workflow 的可靠性来自 context splitting、state externalization 和 adversarial role separation,而不是单纯依赖更强的单体模型。
3. 实现机制:一个动态生成的 Orchestration Layer
如果从系统实现角度抽象,Dynamic Workflow 至少包含六个组件。
| 组件 | 作用 | 关键设计点 |
|---|---|---|
| Workflow generator | 从用户目标生成任务级执行计划 | 需要把自然语言目标转成可执行 graph,而不是只产出 prose plan |
| State store | 维护任务状态、中间产物、验证结果和依赖关系 | 避免把状态全部塞进 context |
| Scheduler | 决定哪些 subtask 可以并行、哪些需要等待上游结果 | 支持 fan-out、barrier、retry、loop |
| Agent router | 为不同 subtask 分配角色、模型、工具权限和上下文切片 | 不同任务需要不同 intelligence level 和 isolation |
| Verification layer | 对 worker 输出做 schema check、evidence check、adversarial review | 需要把 correctness 从主 agent 的自我判断中拆出来 |
| Synthesizer | 合并结构化产物,处理冲突、去重和排序 | synthesis 只能发生在验证之后,否则会放大上游错误 |
这里最重要的是 state store 和 verification layer。很多 agent 系统失败,是因为它们把状态和判断都放在模型上下文里。Dynamic Workflow 把状态管理交给 runtime,把模糊判断交给模型,把硬约束交给程序结构。一个更稳健的原则是:LLM 负责局部判断,runtime 负责全局控制。
在实现上,workflow generator 可以生成某种脚本或 DSL。原文中提到的是可执行 JavaScript,并提供特殊函数来 spawn 和协调 subagents;但这不是本质。更一般地说,任何系统只要支持动态生成 execution graph、独立 agent context、结构化输出、可恢复状态和验证回路,都可以实现类似机制。
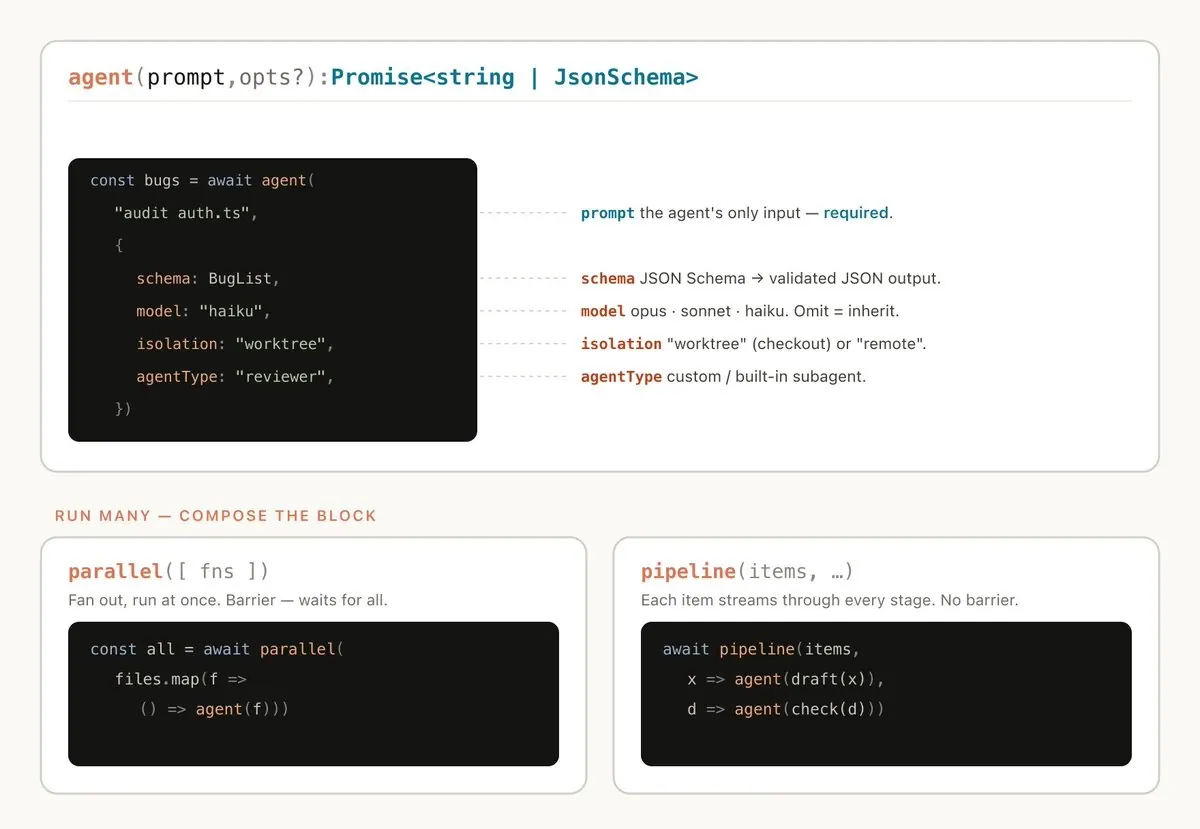
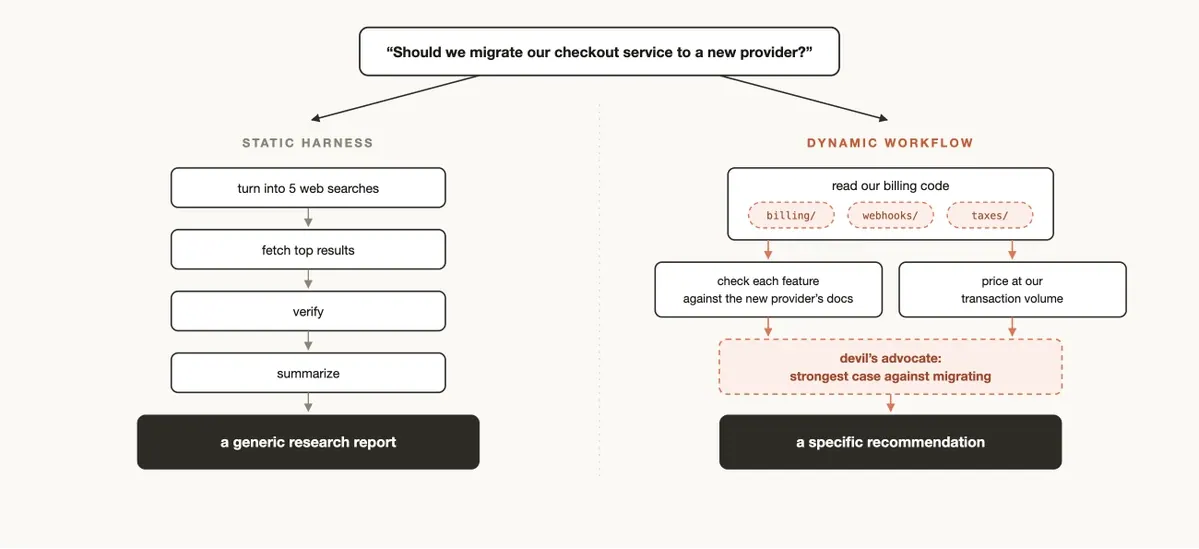
4. Dynamic Workflow 与 Static Workflow 的区别
Static workflow 是提前设计好的 pipeline,适合可重复、边界清晰、输入分布稳定的任务。Dynamic workflow 则是在任务到来时生成,适合一次性、复杂、结构不固定的任务。
| 维度 | Static Workflow | Dynamic Workflow |
|---|---|---|
| 生成时间 | 预先设计 | 任务到来时生成 |
| 适用任务 | 重复性强、流程稳定 | 长任务、探索性任务、结构不确定任务 |
| 可靠性来源 | 人工设计和长期测试 | task-specific decomposition 与 runtime verification |
| 主要风险 | 泛化不足 | 成本高、可预测性弱、难以复现 |
| 最佳位置 | production pipeline | exploratory execution / workflow discovery |
一个有意思的方向是二者融合:Dynamic Workflow 可以作为 workflow discovery mechanism。也就是说,系统先为一次性任务动态生成 workflow;如果某类 workflow 反复有效,就可以被抽象成 reusable static workflow、skill 或 template。
这对 agent infra 很重要。长期看,真正有价值的不是每次都动态生成,而是从动态探索中提炼出稳定模式。
5. 几个关键 Pattern
Dynamic Workflow 的价值不在于某个单独 pattern,而在于可以按任务组合 pattern。
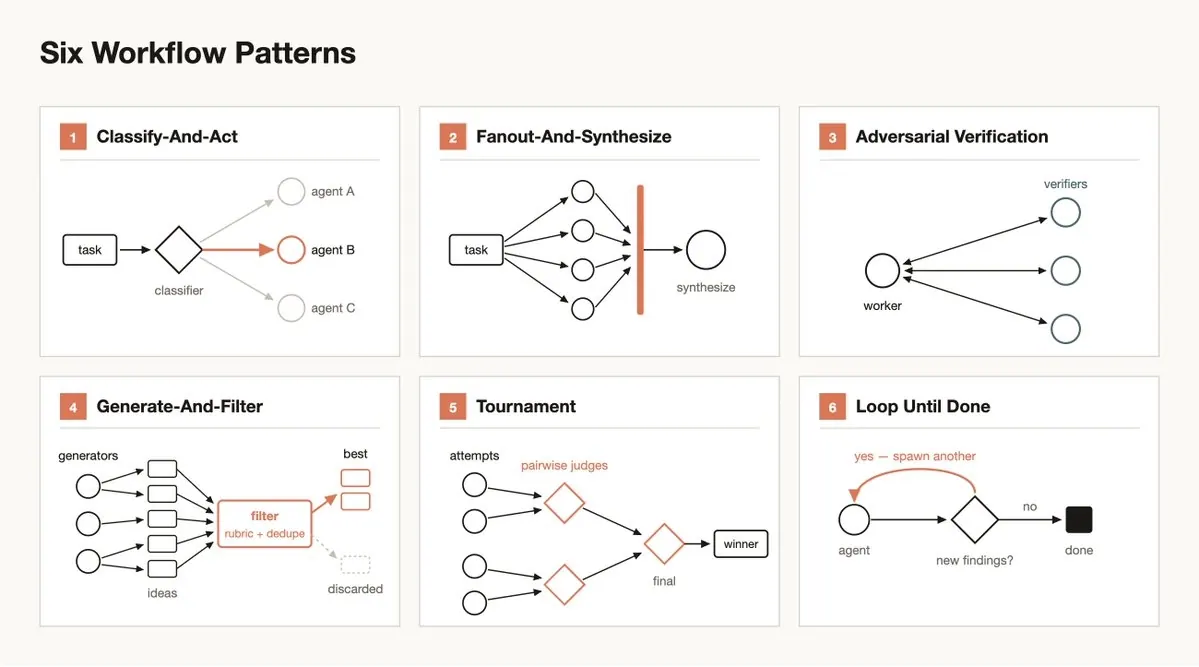
Fan-out-and-synthesize 适合大规模覆盖型任务,例如代码库审查、文档核查、source collection、迁移和重构。它的核心价值不是“多开几个 agent”,而是把任务切成互不污染的局部上下文,并在 barrier 之后统一合并结构化结果。
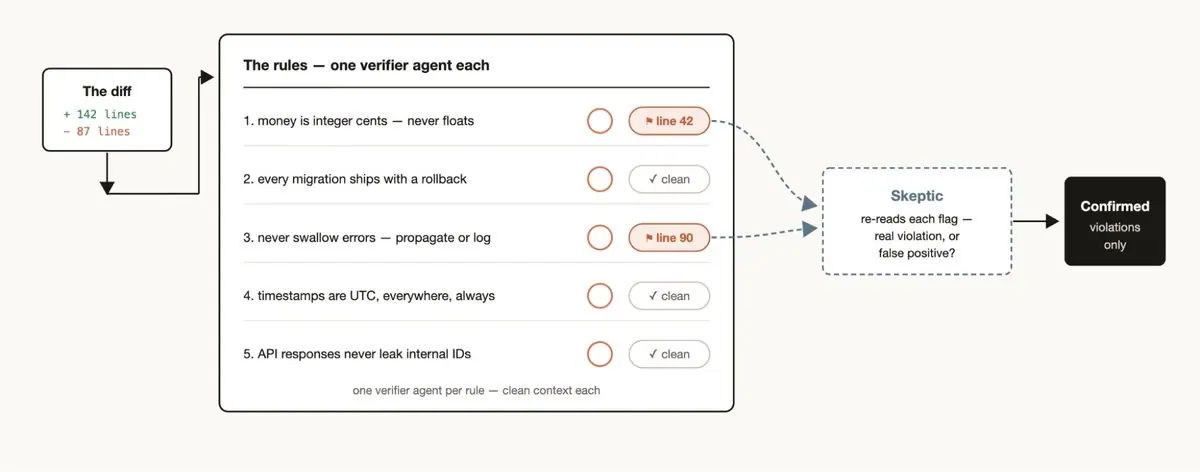
Adversarial verification 适合 high-stakes reasoning,例如安全分析、技术 claim 核查、root-cause investigation 和代码 review。关键是 verifier 的目标必须是发现问题,而不是确认上游 agent 的说法。理想情况下,每个重要 claim 都应该带着 evidence、confidence 和 counterexample search 结果进入 synthesis。
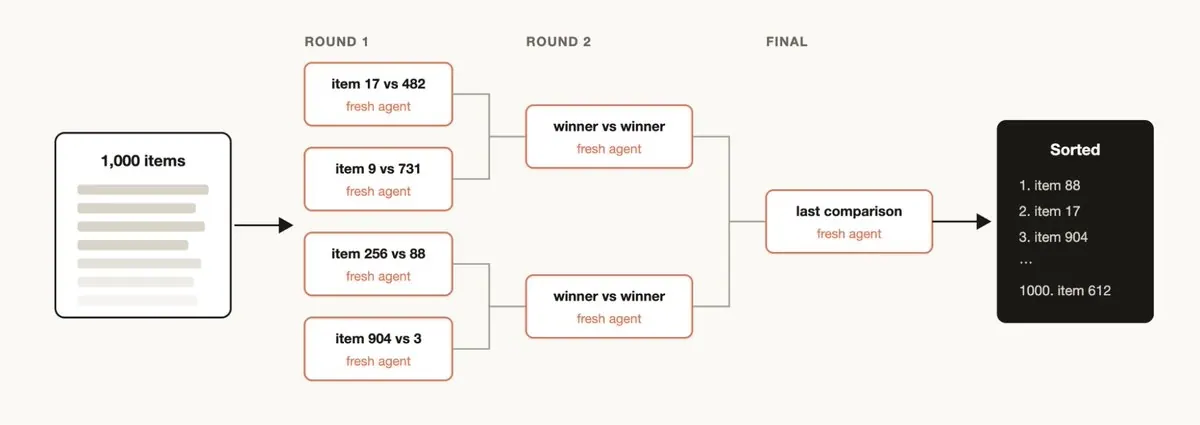
Generate-and-filter / tournament 适合开放式探索和 judgment-heavy tasks。比如命名、架构方案、设计方向、研究假设或简历排序。LLM 在绝对打分上经常不稳定,但在 pairwise comparison 上通常更可靠。因此 tournament 可以把模糊排序问题改写为一系列局部比较,再由程序维护 bracket 和 merge。
Loop-until-done 适合工作量未知的任务,例如 flaky test reproduction、日志排查、长期 triage、自动修复和 recurring issue mining。这里最关键的是 stop condition 必须外置,例如“没有新的 finding”“所有 claim 都有可验证 source”“测试连续通过 N 次”“没有未处理 high-severity item”。没有硬停止条件的 loop 只是在放大 agent 的主观收敛。
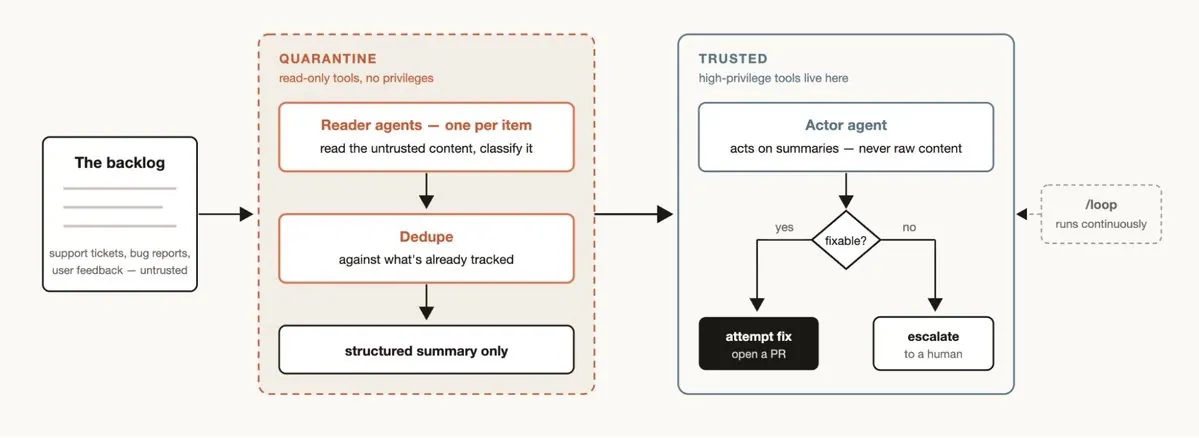
Classify-and-act 适合规模化入口,例如 support queue、bug reports、alerts、文档集合和用户反馈。classifier 不直接完成任务,而是把输入路由到不同子流程。对不可信输入,尤其需要 quarantine pattern:读取外部内容的 agent 不应该直接拥有高权限 action,行动应由另一个受约束的 agent 执行。
6. 应用场景:哪些任务真的值得用?
Dynamic Workflow 的成本明显高于单 agent 调用,因此它应该用于那些“执行组织”本身就是难点的任务。
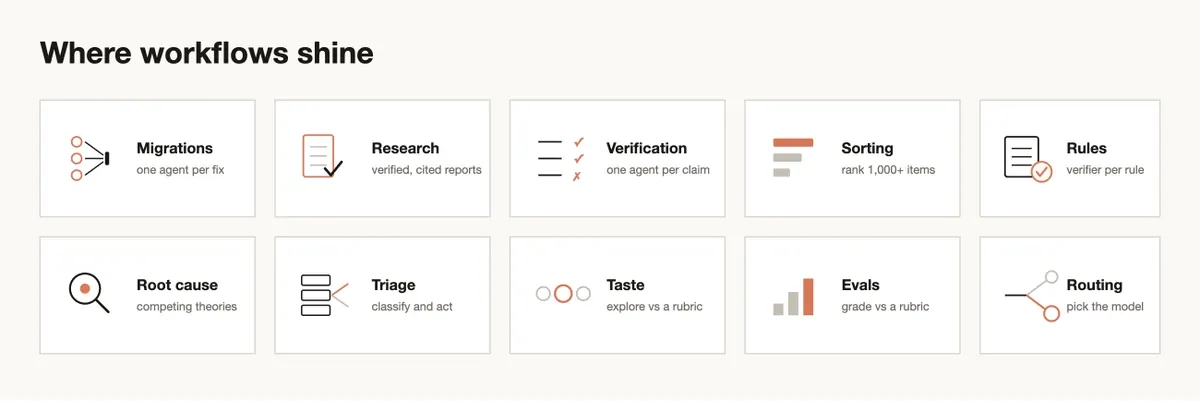
| 场景 | 为什么适合 | 典型 workflow |
|---|---|---|
| 大规模迁移与重构 | 任务可拆、文件多、需要测试闭环 | 按 callsite / module fan-out,在隔离环境中修改,由 reviewer 验证后合并 |
| Deep research | 需要覆盖多个来源并处理冲突证据 | 并行 source collection,claim extraction,source quality verification,cited synthesis |
| Deep verification | 输入是已有报告或博客,需要逐条核查 | 抽取 factual claims,为每条 claim spawn verifier,再做 contradiction check |
| Root-cause investigation | 多证据源、多假设竞争,容易自我确认 | 日志、指标、diff、配置各自生成假设,再由 refuters 攻击 |
| Triage at scale | 输入量大、局部判断多、需要分流 | classify、dedupe、severity ranking、auto-action 或 human escalation |
| Sorting / ranking | 绝对评分不稳定,但比较判断相对可靠 | pairwise comparison tournament 或 bucket-rank-merge |
| Memory mining | 从历史纠错中提炼规则 | 并行聚类 recurring corrections,验证规则是否能预防真实错误 |
| Agent evals | 需要比较 trajectory 和 failure mode | baseline vs candidate,多 agent judge,failure attribution,再迭代 skill 或 workflow |
我会特别强调三个场景。
第一是 deep verification。对技术写作、论文总结和系统分析来说,最危险的问题不是没写,而是写得很顺但某些 claim 没有依据。Dynamic Workflow 可以把“读一遍帮我检查”改造成“抽取每个 factual claim,并为每个 claim 建立独立验证路径”。这非常适合高质量博客、技术报告和 research memo。
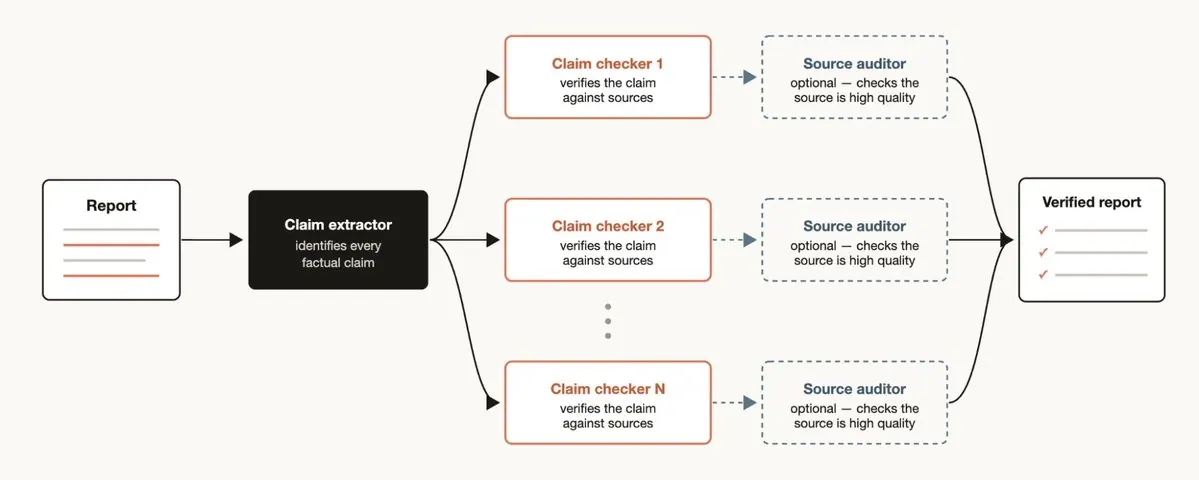
第二是 root-cause investigation。调试和事故复盘最容易被第一个合理假设吸引。Dynamic Workflow 可以强制系统从 disjoint evidence 生成多个假设,再让每个假设接受反驳。它把 debugging 从单线叙事变成 hypothesis competition。
第三是 memory / rule evolution。如果一个 agent 反复犯同类错误,简单把更多规则塞进系统提示并不一定有效。更好的方式是从历史 session、review comment 和用户纠错中挖掘 recurring corrections,再验证这些 candidate rules 是否真的能预防过去的错误。这里 Dynamic Workflow 实际上成了 agent self-improvement pipeline 的一部分。
7. 代价与限制
Dynamic Workflow 不是免费午餐。它至少有五个限制。
第一,token 和工具调用成本更高。多个 subagents、多个 verifier 和多轮 synthesis 会显著放大 compute。它适合用 compute 换 reliability,但不适合轻量任务。
第二,动态生成的 workflow 难以测试。Static workflow 可以积累 regression tests;Dynamic workflow 每次可能不同,因此更依赖 trace、replay、预算约束和执行日志。
第三,verification 不能完全消除错误。如果 worker 和 verifier 使用相似模型、相似提示和相同 evidence,错误可能高度相关。真正的 adversarial verification 需要差异化视角、明确 rubric、反例搜索和必要时的外部工具校验。
第四,synthesis 仍然是瓶颈。即使上游并行做得很好,最终合并阶段也可能丢失 minority signal 或过度平滑冲突证据。因此 synthesis 不应该只消费自然语言 summary,而应该消费结构化产物、verdict、evidence 和 unresolved disagreement。
第五,安全边界需要单独设计。尤其在 triage、网页研究、Slack/Email 自动化和代码修改场景里,读取不可信内容的 agent 与执行高权限动作的 agent 必须分离。否则 workflow 只是把 prompt injection 和权限滥用的攻击面放大了。
8. 对 Multi-Agent System 研究的启发
我认为 Dynamic Workflow 值得关注,不是因为它是 Claude Code 的一个新功能,而是因为它把 multi-agent system 的一个核心问题说得更清楚:多 agent 系统的关键不是 agent 数量,而是 orchestration intelligence。
一个成熟的 MAS 不应只是“多个 agent 互相聊天”,而应该包含任务图、状态机、角色隔离、权限控制、结构化产物、验证协议、预算管理和 trace。Dynamic Workflow 把这些组件组合成一种 task-specific runtime,并允许模型参与 runtime synthesis。
这会带来几个研究问题:
-
如何评估一个动态生成的 workflow 本身,而不只是评估最终输出?
-
什么样的任务适合 dynamic orchestration,什么任务适合 static pipeline?
-
如何自动发现 reusable workflow pattern,并把动态经验沉淀成静态技能?
-
如何降低 worker 与 verifier 的 correlated error?
-
如何在保持灵活性的同时给动态 workflow 加上安全和资源边界?
-
如何把 trace 用于 failure attribution、workflow refinement 和 agent memory evolution?
我的总体判断是:agent 系统未来的竞争点不会只在 model intelligence,也会在 harness intelligence。更强的模型能产生更好的局部判断;更好的 harness 则决定这些判断如何被组织、验证和收敛。
Dynamic Workflows 的真正意义在于,它把 agent 从“在一个上下文里努力完成任务”推进到“为当前任务生成一个临时执行系统”。这可能是 long-horizon agents 从 demo 走向可靠系统的关键中间层。
9. 一句话总结
Dynamic Workflow 不是 Claude Code 的使用技巧,而是一种 agent runtime 设计思想:通过动态生成 task-specific orchestration layer,把复杂任务拆成可并行、可隔离、可验证、可恢复的 multi-agent execution process。
如果说 prompt engineering 关心的是“如何让模型回答得更好”,那么 workflow engineering 关心的是“如何让一组模型和工具作为一个系统完成更复杂的工作”。
References
-
Anthropic, A harness for every task: dynamic workflows in Claude Code.
-
Anthropic, Introducing dynamic workflows in Claude Code: https://claude.com/blog/introducing-dynamic-workflows-in-claude-code