Apodex-1.0: deep research as multi-agent verification
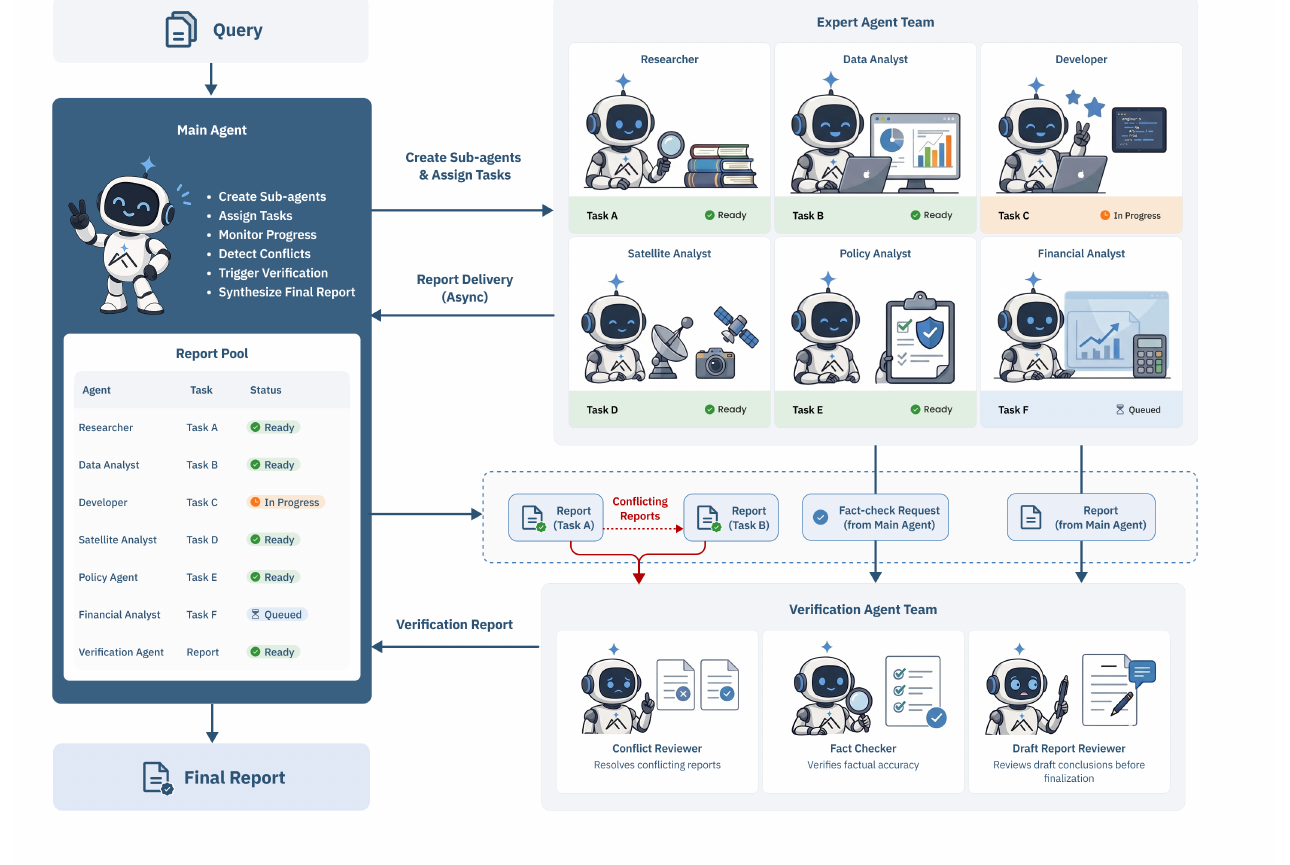
Apodex-1.0 reframes deep research as a multi-agent verification problem rather than a longer single-agent ReAct loop. The trained model can run alone, but the paper’s real system claim is Apodex-1.0-H: an asynchronous agent team where specialized sub-agents explore independently, reports accumulate in a shared evidence pool, and separate verifier agents plus a global verifier decide what the evidence actually supports. The training pipeline matters mainly because the authors want sub-agent spawning, coordination, and verification to be native model behavior, not just an external script wrapped around a generalist model.
-
MAS is the inference unit: The paper’s strongest move is shifting the unit of reasoning from one context window to a problem-specific team. A main agent decomposes the query, dispatches researcher, analyst, developer, and domain-specialist sub-agents, then reads their reports from a shared pool instead of forcing every branch through one congested trajectory. This makes exploration branchable: each sub-agent has its own prompt, tools, and context, so one failed or slow branch does not poison the entire run.
-
Verification is structurally external: Apodex distinguishes itself from self-reflection by assigning verification to agents that did not produce the original reasoning trace. The verifier team is split into a conflict reviewer, fact checker, and draft-report reviewer, each aimed at a different failure mode: contradictory evidence, unsupported claims, and weak final synthesis. For MAS design, this is the central lesson: reliability comes less from agents “debating” and more from giving review agents independent context, independent tools, and permission to reject the worker agents’ conclusions.
-
Asynchrony is the coordination primitive: The report pool is not just storage; it is the causal backbone of the system. Sub-agents deposit reports with statuses like queued, in progress, and ready, while the orchestrator continues spawning, verifying, or synthesizing as partial evidence arrives. That turns exploration, verification, and synthesis into independent control loops, which is why the authors can claim deployments with up to 150 sub-agents and more than 15,000 steps inside one task.
-
Global verification changes selection: Heavy-duty mode does not merely vote across multiple candidate answers. For deep research, the global verifier builds a claim-evidence graph whose nodes are atomic findings and tentative claims, with support and contradiction edges. The final answer is selected by evidence reasoning over the graph, not by answer popularity, which is a better MAS pattern for research tasks where duplicated findings should not outweigh missing or contradictory evidence.
-
AgentOS is the system boundary: The runtime argument is that agent teams need a task-agnostic kernel, not a bespoke loop per benchmark. AgentOS keeps scheduling, model and tool routing, event streaming, checkpoints, traces, cost accounting, and permissions below a narrow node-context facade, while workflows, roles, tools, skills, MCP servers, and verifier components live as plugins above it. This is the part builders should steal: keep the coordination substrate generic, and let each agent topology be a workflow/plugin decision.
Why it matters: The paper is useful for MAS less as a model-training recipe and more as a blueprint for verification-centric agent infrastructure. Its strongest design principle is that agentic scale should not mean “one agent with more turns”; it should mean independent contexts, asynchronous evidence flow, and reviewers that audit the work from outside the worker trace. The main open question is reproducibility: the public repository currently exposes an evaluation harness for Apodex-1.0 in standard ReAct mode, while the heavy-duty MAS runtime and global-verifier implementation are only described at the system-report level.