Autocurricula and Multi-Agent Innovation:社会互动如何生成新问题
Chapter 0
exploration by exploitation (of others)
更多 agents 带来更多搜索压力和资源冲突;好的 solution / tool / pattern 被共享 memory 保存并传播;传播提高整体能力;整体能力提高后可以支撑更大规模、更复杂任务;更大规模又产生更多经验和创新。
Questions:
-
MCTS
-
no free lunch dilemma
-
strategy + tactics
-
game theory
Reading Notes: Autocurricula and the Emergence of Innovation from Social Interaction
论文链接:
Chapter 1:核心问题——为什么 AI 需要自动生成新问题?
这篇论文的出发点是所谓的 problem problem:如果智能来自解决越来越复杂的问题,那么 AI 系统必须不断遇到新的、有挑战性的环境。但在传统单 agent 研究中,这些环境通常由研究者手工设计。环境越复杂,设计成本越高,最终会限制 agent 的成长空间。
作者认为,Multi-Agent 系统可能提供一种自然解法。因为在多智能体环境中,其他 agent 本身就是动态环境的一部分。一个 agent 的策略变化,会改变另一个 agent 面对的问题。这样,系统不再完全依赖人类外部设计任务,而是可以通过 agent 之间的互动自动生成新的学习挑战。
论文用“单人围棋”和“多人围棋”的对比说明这一点。如果棋盘上只有一个玩家,那么问题很快变成简单的空间填充;但只要加入第二个玩家,对方的行动就会持续改变你的局面,原本简单的问题立刻变成复杂的战略互动。这个例子说明,Multi-Agent 的价值不只是“多个 agent 一起工作”,而是其他 agent 会持续改变你的决策空间。
Chapter 2:Autocurriculum——由互动自动生成的学习课程
Autocurriculum 是这篇论文的核心概念。普通 curriculum learning 是人为安排任务难度,比如先训练简单任务,再训练复杂任务。而 autocurriculum 指的是:系统内部的 agent 通过相互适应,自己生成一连串新的挑战。
在 Multi-Agent 系统中,一个 agent 学会某个策略后,其他 agent 的环境就会改变。其他 agent 被迫调整策略,而这种调整又反过来改变第一个 agent 面对的问题。于是,学习过程不再是 agent 在固定环境中寻找最优解,而是多个 agent 共同制造一个不断变化的问题空间。
这篇论文最重要的洞察是:真正有潜力的 Multi-Agent 系统,应当能够让“解决一个问题”自然地产生“下一个问题”。如果 agent 的互动只是重复同样的协作或竞争,那它并不会带来开放式智能。只有当互动持续改变策略地形,并迫使 agent 进入新的学习区域时,autocurriculum 才真正发生。
Chapter 3:Strategy 与 Implementation——社会行为不是一个简单动作
论文强调,在社会互动中,agent 要同时学习两个层面的东西。第一个层面是 strategy,也就是高层战略选择,比如合作、背叛、惩罚、联盟、竞争或分享资源。第二个层面是 implementation policy,也就是如何通过一连串具体动作实现这个战略。
这个区分对 Multi-Agent 非常重要。传统矩阵博弈里,“合作”或“背叛”只是一个离散选项;但在真实的 sequential environment 中,合作不是一个按钮,而是一整套行为模式。一个 agent 可能需要等待、让路、少拿资源、保护队友、惩罚违规者,才能真正实现“合作”。
因此,Multi-Agent 学习的难点不只是选择什么战略,还包括如何把战略落实到具体动作中。更复杂的是,其他 agent 也在同时学习。当它们的战略改变时,你原本有效的 implementation policy 可能会失效。这种高层战略和低层执行之间的双重变化,是 autocurriculum 能够产生复杂性的关键来源。
Chapter 4:Exploration by Exploitation——为什么旧策略会把 agent 推向新问题?
论文提出了一个很有启发性的概念:exploration by exploitation。传统强化学习通常把 exploration 和 exploitation 对立起来。Exploration 是尝试未知策略,exploitation 是利用当前已知最优策略。但作者认为,在 Multi-Agent 环境中,即使 agent 只是继续执行原来的策略,它也可能被迫进入新的学习区域。
原因是环境不是静态的。其他 agent 变了,资源分布变了,社会规则变了,惩罚机制出现了,合作伙伴的行为模式改变了。于是,原来有效的策略开始失效。agent 并不是主动探索新行为,而是因为旧行为不再适应新的社会环境,被迫学习新的 response。
这个概念对 AI Agent 系统非常重要。如果一个系统里的任务、角色和评价规则始终固定,那么 agent 很难自然产生新能力。真正推动 agent 学习的,是其他 agent 的行为不断改变自己的 reward landscape。换句话说,Multi-Agent 系统中的“探索”不一定来自随机扰动,也可以来自社会环境的持续变化。
Chapter 5:外生挑战与种群间挑战——竞争如何生成 Autocurriculum
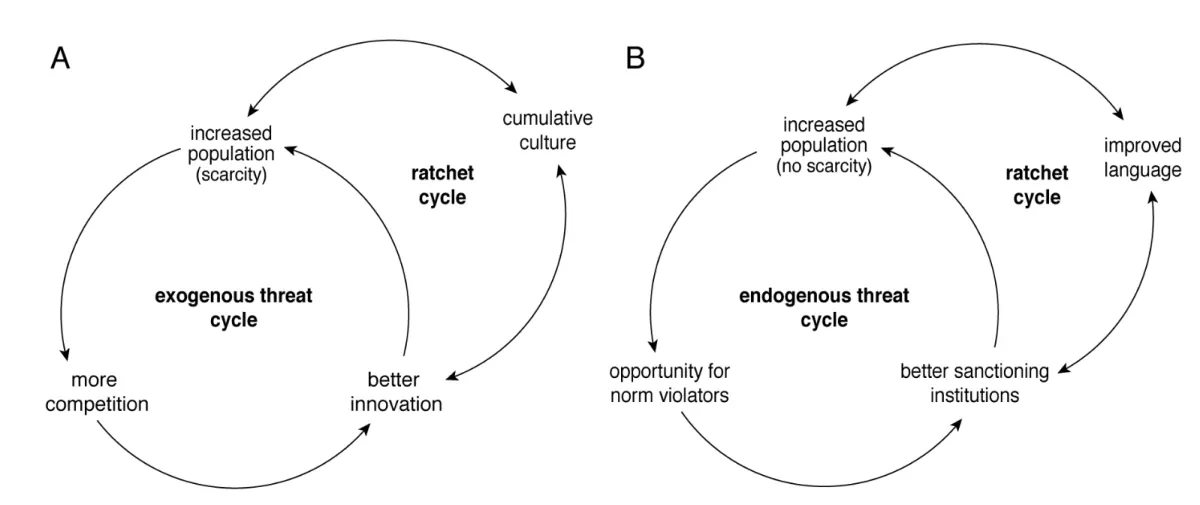
论文把挑战分为外生挑战和内生挑战。外生挑战 指的是挑战来自当前 adaptive unit 外部的其他 adaptive units。最典型的例子是两个 agent、两个团队、两个种群之间的竞争。对其中一方来说,另一方的策略变化就是外部环境变化。
在 AI 中,self-play 是外生 autocurriculum 的经典形式。agent 和自己或过去版本的自己对战,当前版本不断暴露旧版本的漏洞,旧错误因此成为新的训练信号。AlphaGo、AlphaZero 这类系统之所以有效,一个重要原因就是它们不依赖固定对手,而是通过自我对抗持续生成合适难度的挑战。
但论文也强调,外生挑战并不自动等于开放式进步。竞争系统很容易陷入循环。例如石头剪刀布式的策略关系中,策略一直在变化,但系统没有真正积累新能力。为了避免这种循环,系统需要保留历史策略、多样化对手和策略 archive。否则 agent 可能只是不断忘记旧策略、重新学习旧策略,而不是向更高层次推进。
Chapter 6:内生挑战与同一系统内部的合作失败
内生挑战 指的是挑战来自一个 collective adaptive unit 内部。也就是说,问题不是外部敌人带来的,而是系统内部成员之间的目标冲突造成的。论文把这种现象和社会困境联系起来:个体从局部利益出发做出的合理选择,可能会破坏整体系统的长期利益。
这里最重要的社会学概念是 social dilemma,也就是社会困境。典型例子是公地悲剧:每个人都想多占一点公共资源,但如果所有人都这么做,资源最终会崩溃,所有人都受损。在 Multi-Agent 系统里,共享 memory、共享计算资源、共享工具调用额度、共享代码库,都可能成为 common-pool resource。
从 AI Agent 角度看,内生挑战非常现实。多个 agents 如果都只追求局部 reward,可能会污染共享记忆、重复无效工作、抢占容易任务、逃避验证成本,或者把困难任务留给别人。这些问题不是外部 benchmark 能解决的,而是 Multi-Agent 系统内部组织结构必须面对的问题。
Chapter 7:制度、惩罚与约束——从个体策略到群体规则
面对内生挑战,论文认为单个 agent 的自觉克制通常不够。因为社会困境的核心在于:个体短期最优和群体长期最优不一致。要解决这个问题,系统需要形成 institution,也就是规则、规范和信念系统,用来改变个体 agent 的激励结构。
制度的作用不是直接让 agent “变善良”,而是改变 reward landscape。比如,如果过度占用公共资源会受到惩罚,那么原本对个体有利的策略就不再划算。这里的 sanction 可以理解为惩罚、制裁或负反馈。它可以是扣分、降低信誉、减少权限、排除协作,也可以是要求返工或降低调度优先级。
这对 Multi-Agent 设计非常关键。一个成熟的 agent society 不能只依赖每个 agent 的 prompt 或局部目标,而需要有系统层面的约束机制。制度可以把个体短期收益重新对齐到群体长期收益。真正复杂的 Multi-Agent 系统,不只是多个 agent 合作完成任务,而是能够形成规则、执行规则,并通过规则塑造长期行为模式。
Chapter 8:二阶社会困境——为什么解决一个问题会制造下一个问题?
论文最深的洞察之一是:解决一个社会困境,往往会制造更高阶的社会困境。比如,公共资源被过度使用时,系统可以引入惩罚机制。但惩罚本身也有成本,于是新的问题出现了:谁来承担监督和惩罚的成本?如果大家都希望别人去惩罚违规者,自己坐享其成,就会出现 second-order free rider problem。
这说明社会复杂性不是一次性解决出来的,而是在一层层制度问题中生成的。第一阶问题是资源滥用;第二阶问题是谁来监督资源滥用;第三阶问题是谁来监督监督者;再往后,还会出现声誉造假、制度腐化、惩罚滥用等问题。
这正是 endogenous autocurriculum 的来源。一个群体每解决一个内部合作问题,就可能把问题推向更高层级。对 AI Agent 来说,这意味着一个真正高级的 Multi-Agent 系统,不能只设计简单规则,还要处理规则执行、监督成本、仲裁机制、信誉维护和反作弊问题。这些 higher-order problems 本身会成为新的学习课程。
Chapter 9:创新的积累——为什么 Autocurriculum 需要文化记忆
论文最后强调,autocurriculum 本身还不够。多个 agent 相互作用,确实可以持续生成新挑战,但这些挑战可能只是循环。如果系统没有记忆机制,它可能会不断重新发现同样的策略、犯同样的错误、解决同样的问题,然后再次遗忘。
因此,开放式智能需要 cultural memory 和 cumulative culture。Cultural memory 指的是群体层面的长期记忆,不是某个单个 agent 的上下文记忆,而是整个系统对知识、策略、制度、工具和失败经验的保存。Cumulative culture 指的是后一代 agent 可以继承前一代 agent 的成果,并在此基础上继续改进。
论文用 ratchet loop 来描述这种机制。Ratchet 是棘轮,意思是系统可以向前推进,但不容易倒退。对 Multi-Agent 系统来说,这对应策略 archive、共享知识库、失败案例库、工具库、评估协议、历史对手集合和长期制度记忆。没有这些机制,agent 之间的互动可能只是热闹的循环;有了这些机制,互动才可能变成真正的累积式智能增长。
Chapter 10:对 AI Agent / Multi-Agent 的核心启发
这篇论文最重要的结论是:智能不只存在于单个 agent 的内部模型中,也存在于 agent 之间的关系结构中。传统 AI 更关注单个 agent 的 memory、planning、attention 和 reasoning,但这篇论文提醒我们,真正的人类式智能还依赖社会互动、规范、制度、文化记忆和多层级适应。
从 AI Agent 角度看,弱 Multi-Agent 系统只是多个 agent 并行工作;更强的 Multi-Agent 系统会让 agent 彼此改变对方的问题;真正有开放式智能潜力的系统,则会让这些变化形成持续的新挑战,并通过记忆、制度和文化机制把创新积累下来。
因此,设计 Multi-Agent 系统时,关键问题不只是“如何让多个 agent 协作”,而是系统是否具备内生挑战生成机制,是否会因为 agent 的成功而产生新的压力,是否能处理共享资源和 free-riding,是否有制度约束 agent 的局部自利行为,以及是否有长期记忆来防止系统反复回到同一个低水平循环。
这篇论文的核心 idea 可以浓缩为一句话:Autocurriculum 是 Multi-Agent 系统中由互动自动生成的学习课程,而开放式智能的关键,不只是生成新挑战,还要把解决挑战后的创新保存、传播并继续升级。