Crafting Interpreters 第 2 章笔记:A Map of the Territory
核心问题:一段源代码从“文本”到“运行”,中间通常会经过哪些步骤?
0. 本章一句话
第 2 章是在给语言实现画地图:
源代码不是直接运行的,而是会被一步步转换成更结构化、更接近机器执行的形式。
常见路线是:
Source Code
→ Scanning
→ Tokens
→ Parsing
→ Syntax Tree / AST
→ Static Analysis
→ Intermediate Representation
→ Optimization
→ Code Generation
→ Bytecode / Machine Code
→ Virtual Machine / Runtime不是每种语言都会走完整路线,但这张图是理解解释器和编译器的总框架。
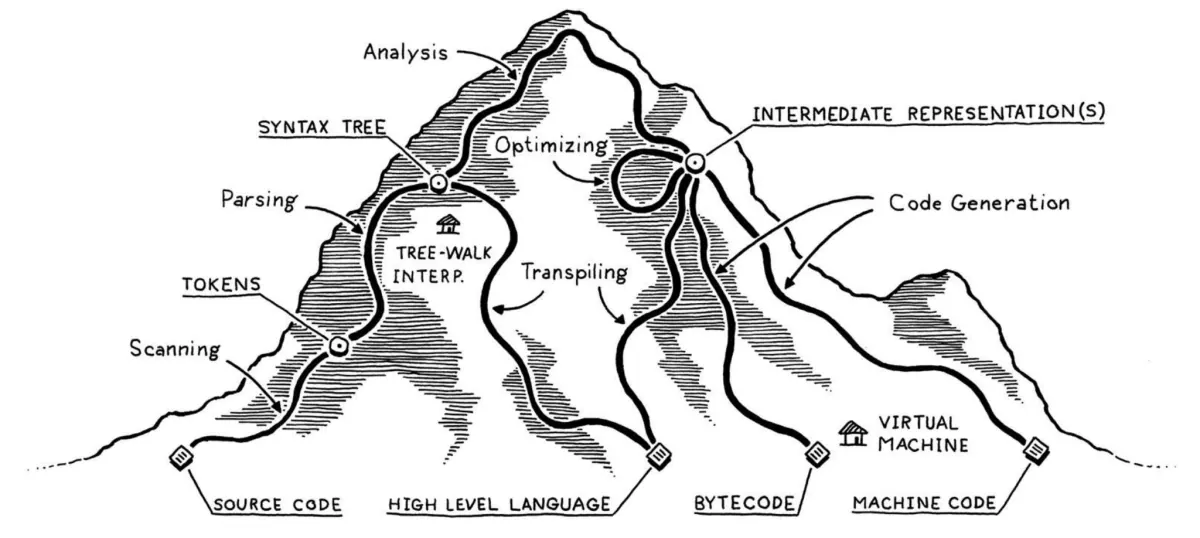
1. 语言 vs 语言实现
语言本身是规则:
-
语法怎么写
-
变量怎么绑定
-
函数怎么调用
-
类型什么时候检查
语言实现是让规则跑起来的程序:
-
scanner
-
parser
-
AST
-
compiler
-
VM
-
runtime
例子:
print "hello";print 是语言功能;
扫描、解析、执行 print 的代码,是语言实现。
2. Scanning:把字符变成 Token
Scanning 也叫 lexing / lexical analysis。
它把源代码字符切成有意义的小块,也就是 token。
例如:
var average = (min + max) / 2;会被切成:
VAR
IDENTIFIER(average)
EQUAL
LEFTPAREN
IDENTIFIER(min)
PLUS
IDENTIFIER(max)
RIGHTPAREN
SLASH
NUMBER(2)
SEMICOLON扫描器通常会忽略:
-
空格
-
换行
-
注释
记忆点
扫描器像“分词器”。
它不理解整个句子的意思,只负责把字符切成语言里的“词”。
3. Parsing:把 Token 变成树
Parsing 是语法分析。
scanner 输出的是一串扁平的 token;
parser 要把它们组织成有层次的结构,也就是 syntax tree / AST。
例如:
1 + 2 3不是简单从左到右理解,而是:
+
├── 1
└──
├── 2
└── 3因为 * 的优先级高于 +。
记忆点
AST 表示代码的嵌套结构。
后面的解释器或编译器通常不会直接处理文本,而是处理 AST。
4. Static Analysis:运行前理解语义
Parsing 只能知道代码的结构。
Static analysis 要进一步理解代码的含义。
例如:
a + bparser 只知道这是加法表达式。
static analysis 可能要判断:
-
a是在哪里定义的? -
b是局部变量还是全局变量? -
它们的类型能不能相加?
其中一个重要步骤叫 binding / resolution:
找出变量名到底指向哪个声明。
5. Intermediate Representation:中间表示 IR
IR 是 source language 和 target machine 之间的中间层。
它的作用是:
-
不太依赖源语言
-
不太依赖目标机器
-
方便优化
-
方便支持多语言、多平台
例如,如果有 3 种语言和 3 种 CPU:
不使用 IR,可能要写:
3 × 3 = 9 个编译器使用 IR 后,可以写:
3 个 front end + 3 个 back end记忆点
IR 像“中转站”。
前端把不同语言翻译成 IR,后端再把 IR 翻译到不同平台。
6. Optimization:在不改变含义的情况下变快
优化是在程序语义已经清楚之后做的。
核心原则:
换一种更快的写法,但结果必须一样。
例子:constant folding
pennyArea = 3.14159 (0.75 / 2) (0.75 / 2);编译器可以提前算好:
pennyArea = 0.4417860938;这样运行时就不用重复计算。
记忆点
优化不是改程序意思,而是改执行方式。
7. Code Generation:生成可执行形式
Code generation 是把程序转换成机器能执行的形式。
可能生成:
-
真实 CPU 的机器码
-
虚拟机的 bytecode
-
另一个高级语言的源代码
如果生成机器码,运行速度快,但平台相关性强。
如果生成 bytecode,可移植性更好,但通常需要 VM 执行。
8. Bytecode 和 Virtual Machine
Bytecode 是给“虚拟机器”看的指令,不是直接给真实 CPU 的。
如果编译器生成 bytecode,就还需要 VM 来运行它。
VM 的优点:
-
实现相对简单
-
更容易跨平台
-
同一份 bytecode 可以在不同机器上跑
缺点:
-
通常比原生机器码慢
-
每条 bytecode 指令都需要 VM 解释执行
本书后半部分的 C 解释器 clox 就会走 bytecode + VM 路线。
9. Runtime:程序运行时需要的服务
Runtime 是程序运行时语言实现提供的基础设施。
常见内容包括:
-
内存管理
-
garbage collector
-
类型信息
-
对象表示
-
函数调用机制
-
VM 执行环境
例如 Java、Python、JavaScript 这类语言,运行时系统非常重要。
记忆点
runtime 不是源代码的一部分,但程序运行时离不开它。
10. 几条捷径和替代路线
并不是所有语言实现都会走完整路线。
Single-pass compiler
一边解析,一边生成代码。
优点是快、简单、省内存。
缺点是语言设计会受限制。
例如早期 C 和 Pascal 就受这种思路影响。
Tree-walk interpreter
解析成 AST 后,直接遍历 AST 执行。
特点:
-
容易实现
-
很适合教学和小语言
-
通常比较慢
本书第一个解释器 jlox 就是 tree-walk interpreter。
Transpiler
把一种高级语言翻译成另一种高级语言。
例如:
TypeScript → JavaScript这样可以复用目标语言已有的编译器、运行时和生态。
JIT
JIT 是 Just-In-Time compilation。
它在程序运行时把代码编译成机器码。
优点:
-
可以接近原生速度
-
可以根据运行时信息优化热点代码
缺点:
-
实现复杂
-
启动和编译本身也有成本
JavaScript 引擎、JVM、CLR 都大量使用 JIT 思路。
11. Compiler 和 Interpreter 的区别
这章强调:compiler 和 interpreter 不是绝对对立的。
Compiler
核心是:
把源代码翻译成另一种形式。
它可能输出:
-
机器码
-
bytecode
-
另一个高级语言
Interpreter
核心是:
直接接收源代码并运行程序。
但很多解释器内部也会先编译。
例如 CPython:
Python source
→ bytecode
→ Python VM executes bytecode所以 CPython 从用户角度看是 interpreter,内部又包含 compiler。
记忆点
编译是一种“翻译技术”。
解释是一种“运行方式”。
一个语言实现可以同时包含两者。
12. 本章关键词
Scanner
把字符流切成 token 的组件。
Token
语言中的最小语法单位,比如关键字、标识符、数字、运算符。
Parser
把 token 序列变成 AST 的组件。
AST
Abstract Syntax Tree,抽象语法树。
表示代码的嵌套结构。
Static Analysis
运行前分析代码含义,比如变量绑定、类型检查。
IR
Intermediate Representation,中间表示。
连接前端和后端的中间层。
Optimization
在保持语义不变的前提下,让程序更快或更小。
Bytecode
给虚拟机执行的低级指令。
VM
Virtual Machine,执行 bytecode 的程序。
Runtime
程序运行时需要的基础服务。
13. 容易误解的地方
误解 1:解释器完全不编译
不一定。很多解释器内部会先编译成 bytecode。
误解 2:编译器一定生成机器码
不一定。编译器也可以生成 bytecode 或另一种源代码。
误解 3:AST 就是最终执行形式
不一定。tree-walk interpreter 会直接执行 AST,但很多实现会继续把 AST 转成 IR 或 bytecode。
误解 4:优化是必须的
不是。很多语言实现一开始几乎不做优化,先保证正确性和简单性。
14. 复习总结
第 2 章给的是一张地图。
源代码会从字符开始,先被扫描成 token,再被解析成 AST。
之后语言实现可能做静态分析、生成 IR、优化、生成 bytecode 或机器码。
如果目标是 bytecode,还需要 VM 执行。
程序运行时还依赖 runtime 提供内存管理、类型信息等服务。
本章最重要的抓手是:
解释器和编译器不是两个完全分开的世界,而是一条语言实现路线上的不同选择。