Codex Source Dive (IV): The Tool Runtime
Codex Source Dive (IV): The Tool Runtime
Subtitle: How Codex safely lets a model read files, run commands, edit code, and call MCP tools.
TLDR: Codex tools are not just functions exposed to a model. They are a model-facing menu backed by a policy-bound runtime that owns execution, permissions, sandboxing, stream events, MCP wrapping, skill injection, and history feedback.
The first post argued that Codex’s agentic loop is not a toy while tool demo. A turn is a managed runtime boundary.
The second post argued that Goals are not prompts. A Goal is a thread-level state machine with persistence, continuation gates, accounting, and authority boundaries.
The third post argued that subagents are not background function calls. They are persistent child threads in a session-level tree.
This fourth post is about the thing users feel most directly:
Read the repo, run the failing test, patch the bug, and verify the result.That sounds simple. It is also the moment where an LLM stops being a text generator and starts touching a real workspace.
The shallow explanation is: Codex gives the model tools.
That is true, but it hides the interesting design.
Codex’s tool system is not a bag of functions. It is a model-facing menu in front of a policy-bound execution runtime.
The model sees schemas. The runtime owns execution. Between those two layers sit the router, registry, permission policy, sandboxing, stream events, cancellation, parallelism rules, MCP wrapping, skill injection, and history feedback.
That separation is the whole point. A model should be able to ask for cargo test, sed -n, apply_patch, an MCP call, or a plugin skill. It should not get to decide what filesystem it is really touching, whether escalation is allowed, whether a command can run in parallel with another command, how an MCP server is called, or how a patch is verified.
Start with a concrete task.
The checkout service started failing after the billing SDK migration.
Find the failing test, patch the adapter, run the smallest useful test, and explain the evidence.A capable agent will usually need four kinds of action:
1. inspect files and history;
2. run commands;
3. edit code;
4. maybe call external tools: docs, issue trackers, app connectors, MCP servers, or skills.If these actions were implemented as scattered if model_called_shell { ... } branches, the system would become impossible to reason about. Shell would have one permission path. apply_patch would have another. MCP would have another. Plugins would have another. Streamed UI events would drift away from actual execution. Cancellation would be inconsistent. Tool outputs would be hard to feed back into the next model sample.
Codex instead gives the turn a common shape:
model-visible specs
↓
ToolRouter
↓
ToolCallRuntime
↓
ToolRegistry
↓
CoreToolRuntime handlers
↓
stream events + tool outputs + conversation historyThat is the main idea of this post.
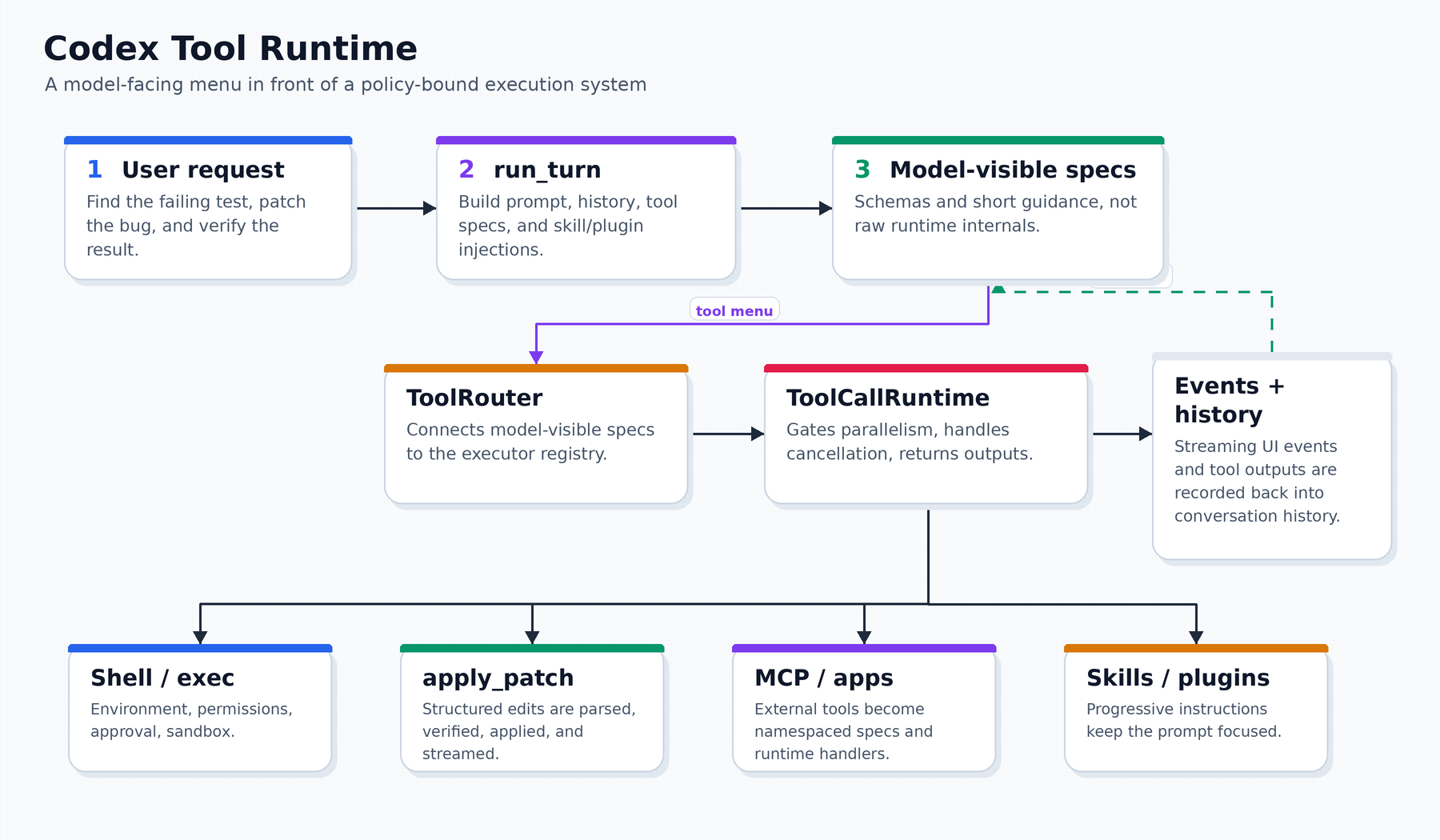
1. The model sees a menu; Codex keeps the kitchen
A tool schema is a contract, not the tool itself.
That distinction matters because the model-facing surface has to be small, readable, and stable enough for the model to choose from. The execution side has to be richer: it needs runtime state, environment IDs, sandbox policy, app connections, cancellation tokens, telemetry hooks, stream emitters, and output truncation rules.
Codex separates those responsibilities with two outputs from tool planning:
model_visible_specs: the schemas sent to the model
registry: the executors available to the runtimeThe model only needs the first output. The runtime needs the second.
That means a tool can be:
direct: visible to the model and dispatchable by the runtime
hidden: not shown to the model, but still dispatchable internally
deferred: not initially shown as a callable tool, but searchable/discoverable
hosted: model-provider hosted, not a local executorThis is the first important design choice: Codex does not equate “installed” with “visible.”
A repo session might have shell tools, patch tools, view-image support, request-permission tools, collaboration tools, MCP tools, app/plugin extension tools, dynamic tools, and hosted model tools. Showing all of that at once would produce a noisy prompt and a weak decision surface. Hiding too much would make the agent underpowered. So Codex builds a per-turn tool plan.
The plan is assembled from sources, filtered by feature flags, environment mode, model capabilities, code-mode settings, namespace support, and tool exposure.
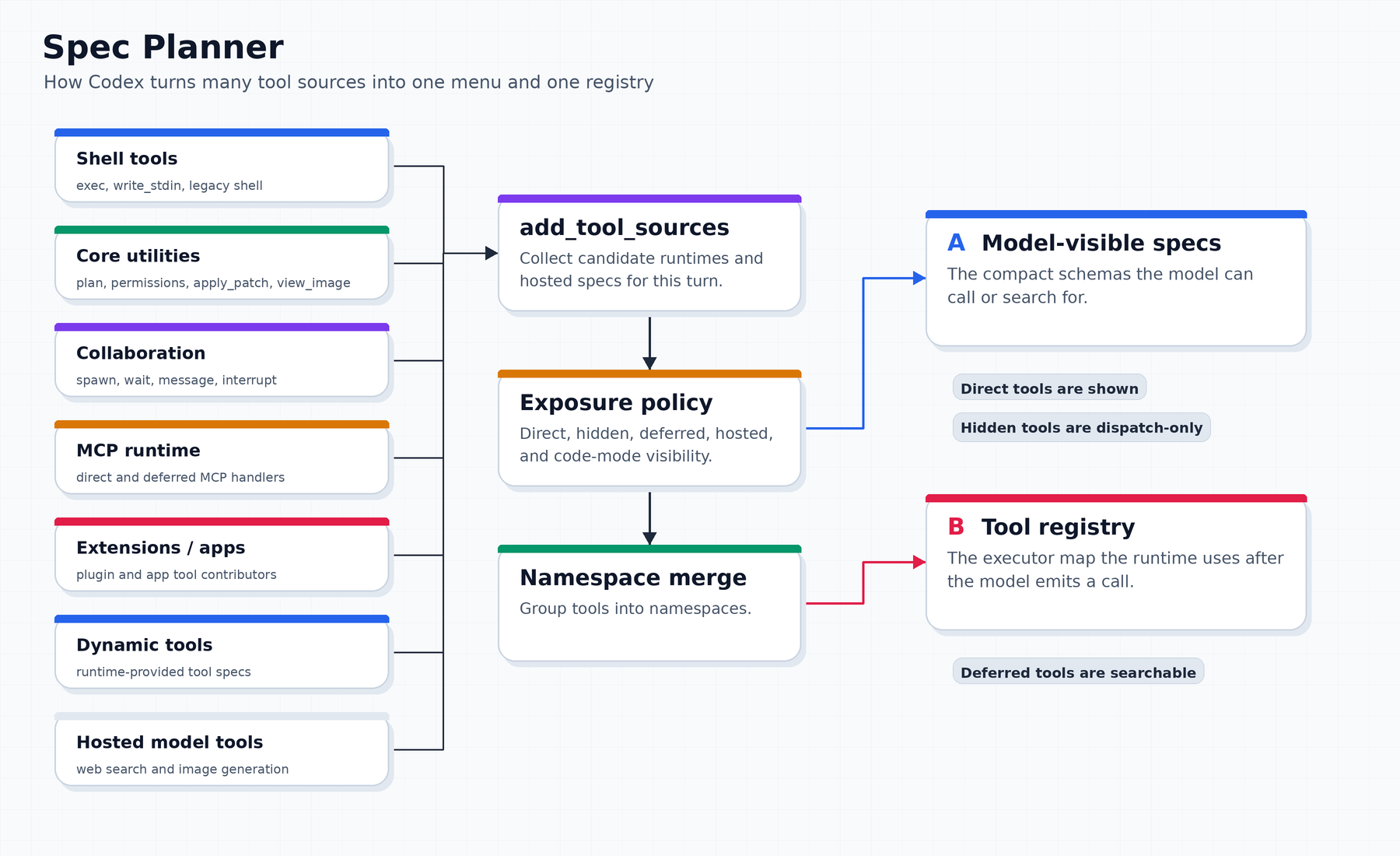
The result is not merely a list. It is a pair:
ToolRouter {
model_visible_specs,
registry,
}The router is the bridge. On the model side, it exposes schemas. On the runtime side, it resolves a completed model item into an executor.
That lets the code stay honest about the boundary:
The model chooses a tool call.
The runtime decides how that call is executed.2. run_turn is where the menu becomes active
The turn loop is where the tool system becomes real.
Before sampling, Codex builds the prompt, the conversation history, skill/plugin injections, MCP/app exposure, and the tool router for this turn. That is why tools belong in the turn runtime instead of in a global static list. The correct tool surface depends on the active model, current environment, enabled features, installed plugins, app mentions, skill mentions, session source, sandbox profile, and current context budget.
For our checkout task, the initial prompt might make several tool families relevant:
shell / exec -> run tests, grep, inspect files
apply_patch -> edit the adapter safely
MCP / apps -> fetch external context if connected
skills/plugins -> load specialized guidance only if relevantThe model sees a compact menu. It might first call a shell tool:
cargo test -p checkout adapter_migration -- --nocaptureWhen the response stream produces a completed tool-call item, Codex does not immediately execute arbitrary JSON. It asks the ToolRouter to build an internal ToolCall.
That conversion matters because model outputs are not all shaped the same way. Some are ordinary function calls. Some are custom/freeform calls such as apply_patch. Some are tool-search calls. The router normalizes those model items into a runtime-level call that can be dispatched.
Then ToolCallRuntime takes over.
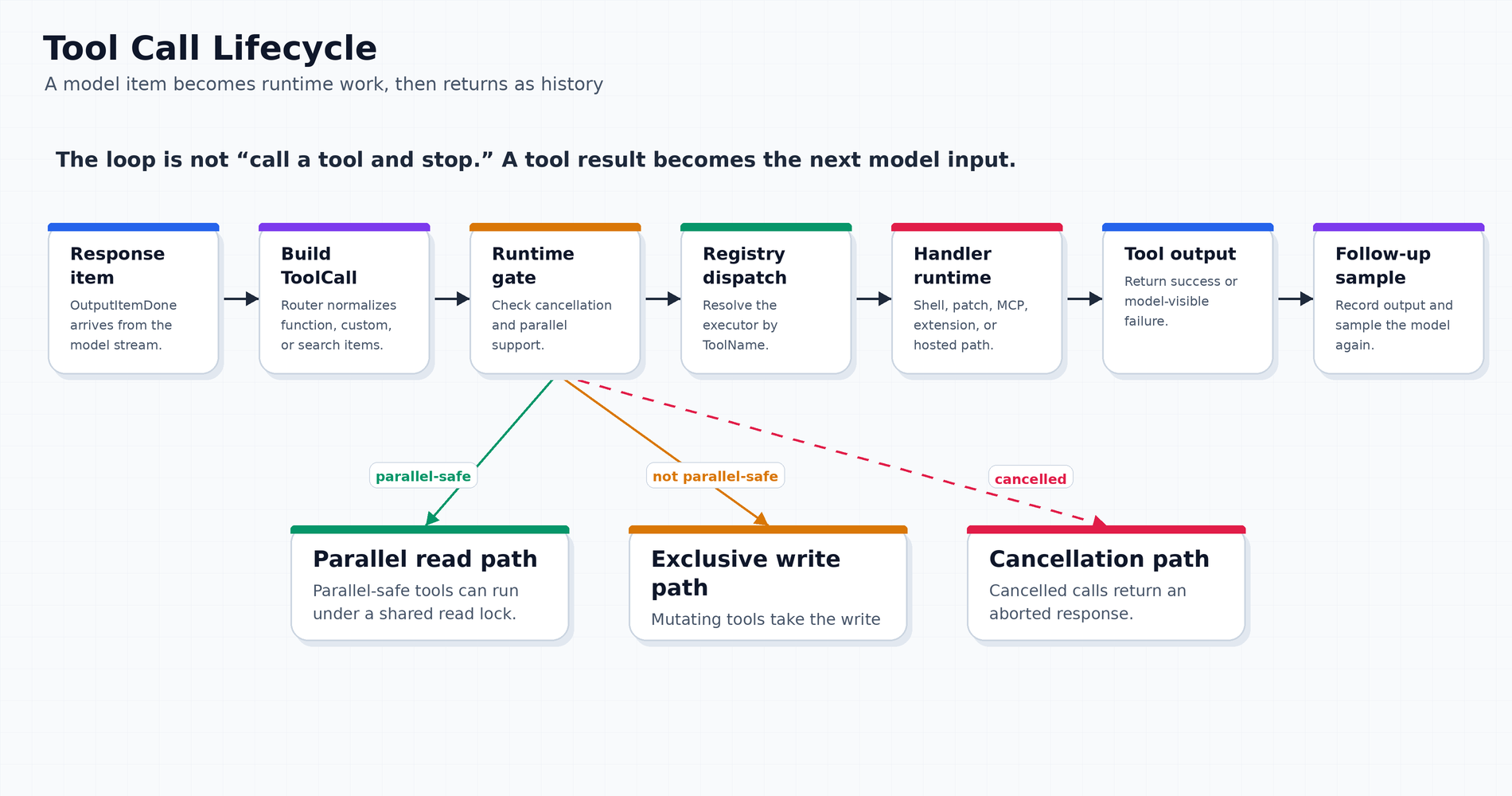
There are several useful details hidden in that diagram.
First, the runtime checks cancellation. A user interrupt should not become a half-applied tool call.
Second, the runtime checks whether the selected tool supports parallel calls. Read-only tools can sometimes run under a shared path. Mutating tools need an exclusive path. That is why the runtime uses a parallelism gate instead of letting every tool run freely.
Third, errors are returned in a model-visible shape. A tool failure is not just a Rust error or an exception; it becomes structured feedback the model can reason about in the next sample.
Fourth, successful output is recorded back into history. The next model sample is not starting from memory or vibes. It sees the tool result as conversation input.
This is why the agentic loop works: tool execution is not outside the conversation. It is folded back into the conversation.
3. Shell is powerful, so shell is policy-bound
Shell is the most tempting tool to describe casually. It is also the most dangerous.
In a coding agent, shell means more than ls and grep. It can run tests, start servers, mutate files, reach networks if allowed, invoke package managers, and generate long outputs. A shell tool cannot just be a string passed into std::process::Command.
Codex treats shell execution as a request that must be resolved against the current turn environment and permission profile.
The path looks like this:
model emits command
↓
resolve primary environment
↓
apply granted turn permissions
↓
validate requested additional permissions
↓
reject invalid escalation under the current approval policy
↓
intercept apply_patch if the command is actually a patch
↓
otherwise create exec approval requirement
↓
run through ShellRuntime and ToolOrchestrator
↓
emit shell events and return formatted outputThat is a lot of machinery for “run a command,” but each part exists for a reason.
The model might ask for a command that needs more filesystem or network access than the current profile allows. Codex should not let the model silently upgrade itself. If the approval policy does not allow explicit escalation, the tool path rejects the request and returns a message the model can act on.
The model might also run a command that takes time. The runtime needs cancellation and event streaming so the UI can show progress and the user can interrupt.
The model might produce huge output. The tool output has to be formatted and truncated under the active truncation policy so the next model sample does not drown in logs.
Most importantly, the shell path is where Codex draws a bright line between “the model asked” and “the system allowed.”
That is the correct line.
4. apply_patch is not just shell with better syntax
Editing code is different from printing output.
If the model writes a patch, Codex can reason about the edit before applying it. The patch can be parsed. File references can be checked. The filesystem can be verified. Sandbox policy can be applied. The UI can stream patch deltas. The result can be associated with a turn diff tracker.
That is why apply_patch gets its own path.
In the model-facing world, apply_patch can look like a freeform patch tool. In the shell-shaped world, a model might also try to run an apply_patch command. Codex handles that by intercepting patch-shaped shell commands and routing them into the patch pipeline instead of treating them as an ordinary shell process.
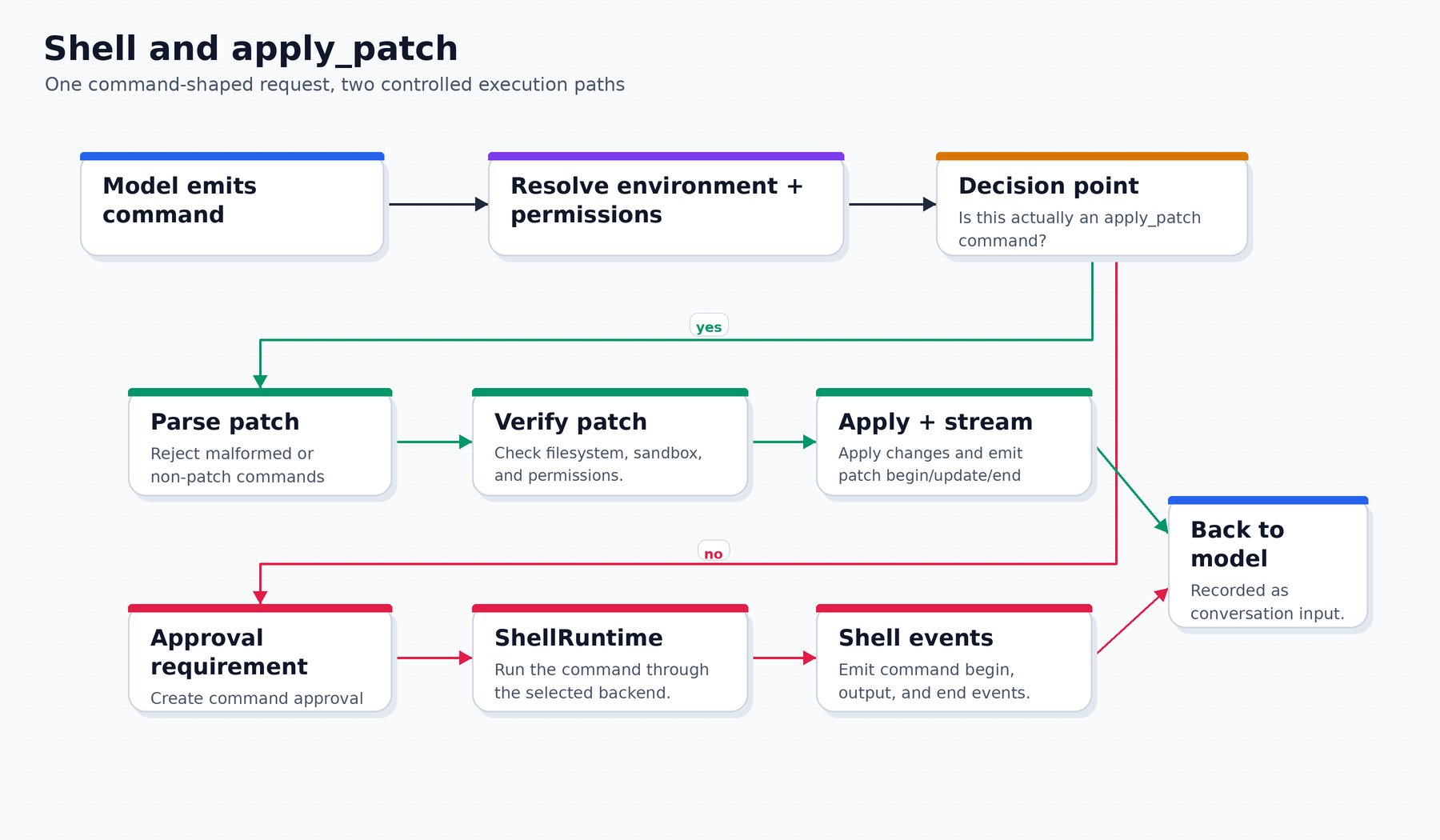
For the checkout task, the sequence might look like this:
1. The model runs the focused test and sees a failure in BillingAdapter.
2. It opens the adapter and notices the new SDK returns cents, not dollars.
3. It emits an apply_patch diff.
4. Codex parses and verifies the patch against the selected environment filesystem.
5. Codex applies the patch and emits patch begin/update/end events.
6. The model runs the focused test again.
7. The tool output returns as evidence for the final answer.The important part is step 4. A patch is not trusted just because it appears in a model response. It is checked against the actual workspace and current execution boundary.
This also explains why apply_patch should not be mentally grouped with normal shell commands. A shell command asks the environment to do something. A patch asks Codex to perform a structured code edit. That lets Codex attach better safety, better UI events, and better diff tracking to code changes.
5. MCP tools enter through the same runtime mesh
MCP makes the tool surface much wider. A session can expose tools backed by external servers, app connectors, project-specific integrations, or plugin-provided capabilities.
The naive version would be dangerous:
for every MCP server:
dump every tool schema into the prompt
let the model call any of them directlyCodex does something more disciplined.
MCP tool information is wrapped into McpHandler runtimes. The handler converts tool metadata into a namespaced model-facing spec, keeps searchable metadata, handles pre/post hook payloads, and delegates execution to the MCP tool-call path. If the server or tool annotations say a tool is read-only or parallel-safe, that can feed into the runtime’s parallelism decision. Otherwise, the tool should not be assumed safe to run concurrently.
That gives MCP tools the same basic lifecycle as local tools:
schema shown or discovered
↓
model emits tool call
↓
router builds ToolCall
↓
runtime gates concurrency and cancellation
↓
registry dispatches to McpHandler
↓
MCP result becomes tool output and historyThe same boundary is doing the work. MCP expands what Codex can reach, but it does not bypass the execution system.
This is important for product design. Once external tools enter the picture, the agent needs consistency more than ever. The user should not have to learn one mental model for shell, another for patches, another for app connectors, and another for MCP. The runtime should make them feel like one controlled surface.
6. Skills are progressive disclosure for instructions
Tools are not the only scarce resource. Instructions are scarce too.
A skill can contain detailed guidance: when to use a capability, what files to inspect, what constraints to respect, what tool sequence is safe, what output format is expected. Loading every full skill document into every turn would waste context and confuse the model.
Codex’s skill path is built around progressive disclosure.
The useful mental model is:
First show enough metadata to choose.
Then load the full skill only when the task actually needs it.The code surface reflects that shape: available skills can be built from bundled skills, plugin skill roots, config layers, and project roots; explicit skill mentions can be collected from user input; implicit skill invocation can be detected from commands; and default skill metadata budget limits how much initial skill metadata competes with the rest of the prompt.
That creates a different kind of tool boundary.
A shell schema tells the model what arguments it can provide. A skill stub tells the model that a deeper instruction package exists. The full skill file is not always part of the initial prompt. It becomes part of the turn only when selected by mention, context, or runtime logic.
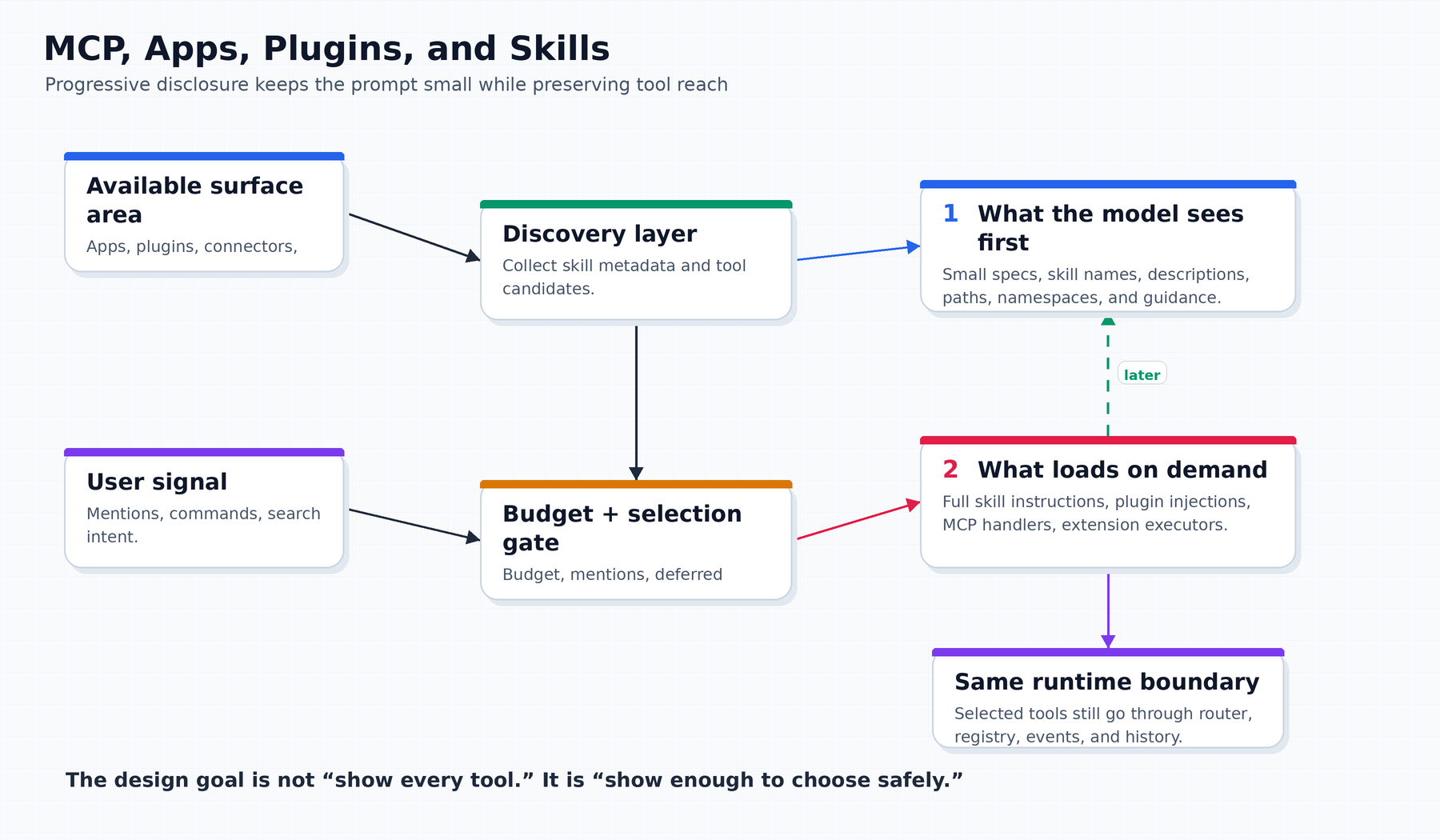
This is easy to underestimate.
Without progressive disclosure, a powerful agent platform collapses under its own tool catalog. Every new integration makes the prompt longer. Every new skill makes the model less focused. The system becomes more capable in theory and less usable in practice.
With progressive disclosure, Codex can say:
The model knows this capability exists.
The runtime can load the details when needed.
The context budget remains available for the actual repo and task.That is the right trade-off for a coding agent. Most turns do not need every skill. But when a turn does need one, the model needs a reliable path to discover and load it.
7. Stream events make the runtime legible
A tool runtime that only returns final text is hard to trust.
Users need to see what the agent is doing:
which command is running;
what output has appeared;
whether a patch is being applied;
which MCP call is in flight;
whether a tool was cancelled;
what changed in the workspace.This is why the tool system is tied to stream events. Shell execution emits begin/output/end-style events. Patch execution emits patch begin/update/end-style events. MCP calls can emit their own begin/end events. The turn loop handles streamed model events, active tool argument diffs, tool outputs, and turn items as part of the same conversation lifecycle.
That makes the UI honest. The user is not watching a decorative transcript after the fact. The user is watching runtime state as it happens.
For the checkout task, this matters practically:
- The user sees the focused test command.
- The user sees the failing assertion.
- The user sees the patch diff as it is applied.
- The user sees the verification command.
- The final answer can cite the actual commands and outputs observed in the turn.The story ends where it began: tool output comes back into history.
The final answer is not just a natural-language claim. It is backed by the tool events and outputs the runtime recorded.
8. The real design: capabilities are unified, authority is not
Here is the wrong abstraction:
Codex has a shell tool, a patch tool, MCP tools, and skills.That is a feature list. It does not explain the system.
Here is the better abstraction:
Codex gives the model a controlled way to request actions.
The runtime owns execution, policy, visibility, cancellation, events, and history.That explains why the code has the shape it has.
spec_plan.rs is not just registering tools. It is deciding which capabilities should be visible, hidden, deferred, or hosted for this turn.
ToolRouter is not just a map from names to functions. It is the boundary between model-facing specs and runtime dispatch.
ToolCallRuntime is not just an async executor. It applies concurrency and cancellation semantics before dispatch.
Shell is not just command execution. It is environment resolution plus permissions plus approval policy plus sandboxing plus streamed events.
apply_patch is not just a command. It is a structured edit path with parsing, verification, sandbox checks, patch events, and diff tracking.
MCP is not a separate escape hatch. It is wrapped into handlers and namespaces so it can flow through the same router and registry.
Skills are not prompt bloat. They are progressive instruction packages that can be discovered and loaded under a context budget.
Put together, that is the design choice:
Codex unifies the tool surface without flattening authority.
The model gets a single way to ask. The runtime preserves many ways to decide, constrain, execute, stream, and record.
That is why the tool runtime is the right Part IV of this series. Once you understand turns, goals, and subagents, tools are the layer where all of those abstractions touch the real world.
A turn can call tools. A goal can continue across tool-backed progress. A subagent can run its own tool runtime inside a child thread. And every one of those paths still has to answer the same question:
What is the model allowed to ask for, and what is the runtime allowed to do?The answer is Codex’s tool system.
Source landmarks
These are the most useful files to read after the article:
codex-rs/core/src/session/turn.rs: the turn loop, prompt construction, skill/plugin preparation, streamed response handling, and tool-call handoff.codex-rs/core/src/tools/spec_plan.rs: the per-turn tool planner that builds model-visible specs and the runtime registry.codex-rs/core/src/tools/router.rs: the bridge between model output items and runtimeToolCalls.codex-rs/core/src/tools/parallel.rs:ToolCallRuntime, cancellation, parallelism gating, and model-visible failure output.codex-rs/core/src/tools/registry.rs: the executor contract, hook payloads, diff consumers, and tool exposure model.codex-rs/core/src/tools/handlers/shell.rs: shell execution, permission normalization, approval policy checks, sandbox handoff, andapply_patchinterception.codex-rs/core/src/tools/handlers/apply_patch.rs: structured patch parsing, verification, sandbox-aware application, and patch streaming events.codex-rs/core/src/tools/handlers/mcp.rs: MCP tool wrapping, namespaced specs, searchable metadata, hooks, and runtime execution.codex-rs/core/src/skills.rs: the skill-loading bridge for available skills, explicit mentions, implicit invocation, and metadata budgeting.