Codex Source Dive (V): The Security Model
Codex Source Dive (V): The Security Model
Sandbox, approvals, and exec policy behind one command.
TLDR: Codex security is not one confirmation box. A command crosses several gates: exec policy classifies it, approval policy decides whether a human must review it, sandbox mode defines what it can touch, and platform-specific backends enforce the boundary.
In the first four parts, we looked at the shape of Codex as an agent runtime:
- the agentic loop that turns model output into tool work and feeds the result back into the next turn;
- Goals as persistent, resumable, budget-aware thread state;
- Subagents as a thread tree rather than a one-off parallel model call;
- the Tool Runtime that exposes shell,
apply_patch, MCP, apps, plugins, and skills through a single model-facing capability system.
This part is about the membrane around all of that.
A coding agent is useful because it can act. It reads files, edits code, runs tests, invokes package managers, calls tools, and sometimes asks for network access. The hard part is that those actions are not equal. cargo test inside a repo, rm -rf ~/.cache, curl https://api.example.com, writing .git/config, and calling a side-effecting connector are all “tool calls” from a model’s point of view, but they should not have the same runtime authority.
So the security model cannot be a single prompt instruction like “be careful.” It has to be a runtime design.
The thesis of this article is:
Codex security is not one yes/no confirmation box. It is a layered execution membrane: sandbox decides what is technically possible, approval decides who must review a boundary crossing, exec policy decides whether a command should be trusted, and platform-specific sandboxing turns those decisions into OS-enforced behavior.
The story starts with one ordinary debugging task.
The task: “Fix the checkout timeout and run the failing test”
Imagine the user says:
The checkout integration test started timing out after the adapter refactor.
Find the regression, patch it, and run the failing test.From the model’s point of view, the next steps look straightforward:
- inspect the checkout adapter;
- run the failing test;
- patch the code;
- run the test again;
- if a dependency or service is missing, fetch what is needed;
- report the result.
From the runtime’s point of view, those steps have very different risk profiles.
Reading src/checkout/adapter.rs is low risk. Editing src/checkout/adapter.rs is expected in workspace-write. Running a local test command may be fine. But fetching a package from the network, writing outside the workspace, changing .git/hooks/pre-push, reading .env, or calling an MCP connector with side effects crosses a different boundary.
The security model is there to keep those boundaries explicit without turning every normal repo action into a negotiation.
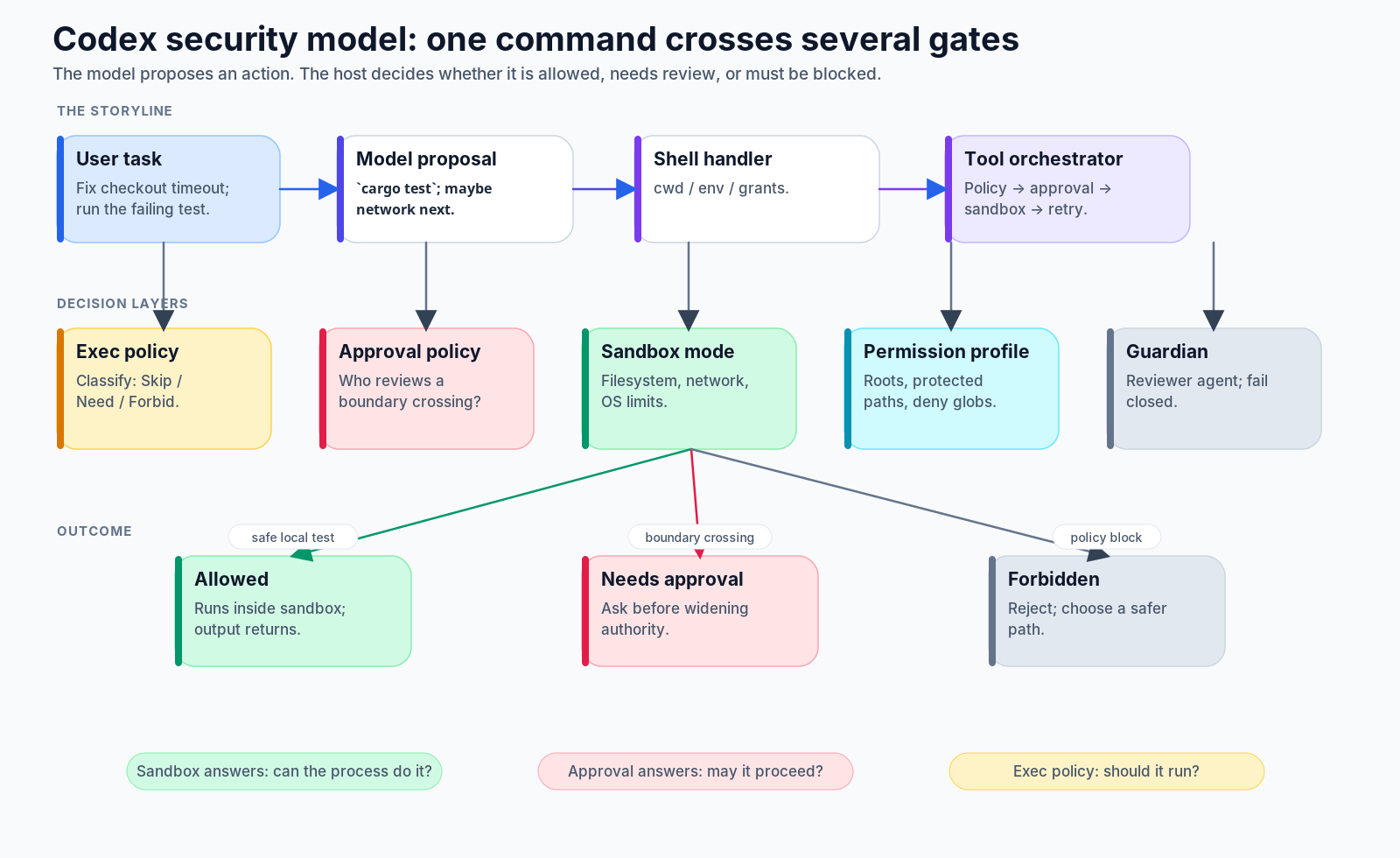
A good mental model is to treat every concrete action as passing through several gates:
model proposes action
↓
shell / tool handler resolves request
↓
exec policy classifies the command
↓
approval policy decides whether review is required
↓
sandbox mode and permission profile define the technical boundary
↓
ToolOrchestrator runs, blocks, or retries under the selected boundary
↓
stdout / stderr / denial / approval result returns to the turnThat sounds heavy, but it is exactly why Codex can feel smooth on routine tasks while still stopping at meaningful risk boundaries.
The first split: sandbox answers “can it?”, approval answers “may it?”
The official docs draw the most important line in the system: sandbox mode and approval policy are different controls.
Sandbox mode is the technical envelope. It controls what a spawned command can actually touch: filesystem, network, and platform-level capabilities. Approval policy is the review protocol. It controls when Codex must ask a reviewer before it attempts an action that crosses the configured boundary.
That split matters because the two solve different failure modes.
If the sandbox is weak, a model mistake can become a real system mutation before anyone reviews it. If approval is weak, the sandbox may still block some behavior, but the model may keep trying boundary-crossing actions without a deliberate decision. If everything requires approval, the agent becomes unusable for ordinary work. If nothing requires approval, the agent becomes too trusted.
The default useful posture is therefore not “never act” or “act freely.” It is closer to:
work normally inside the active workspace;
keep network off by default;
protect sensitive roots;
ask before crossing the boundary;
fail closed when review cannot complete.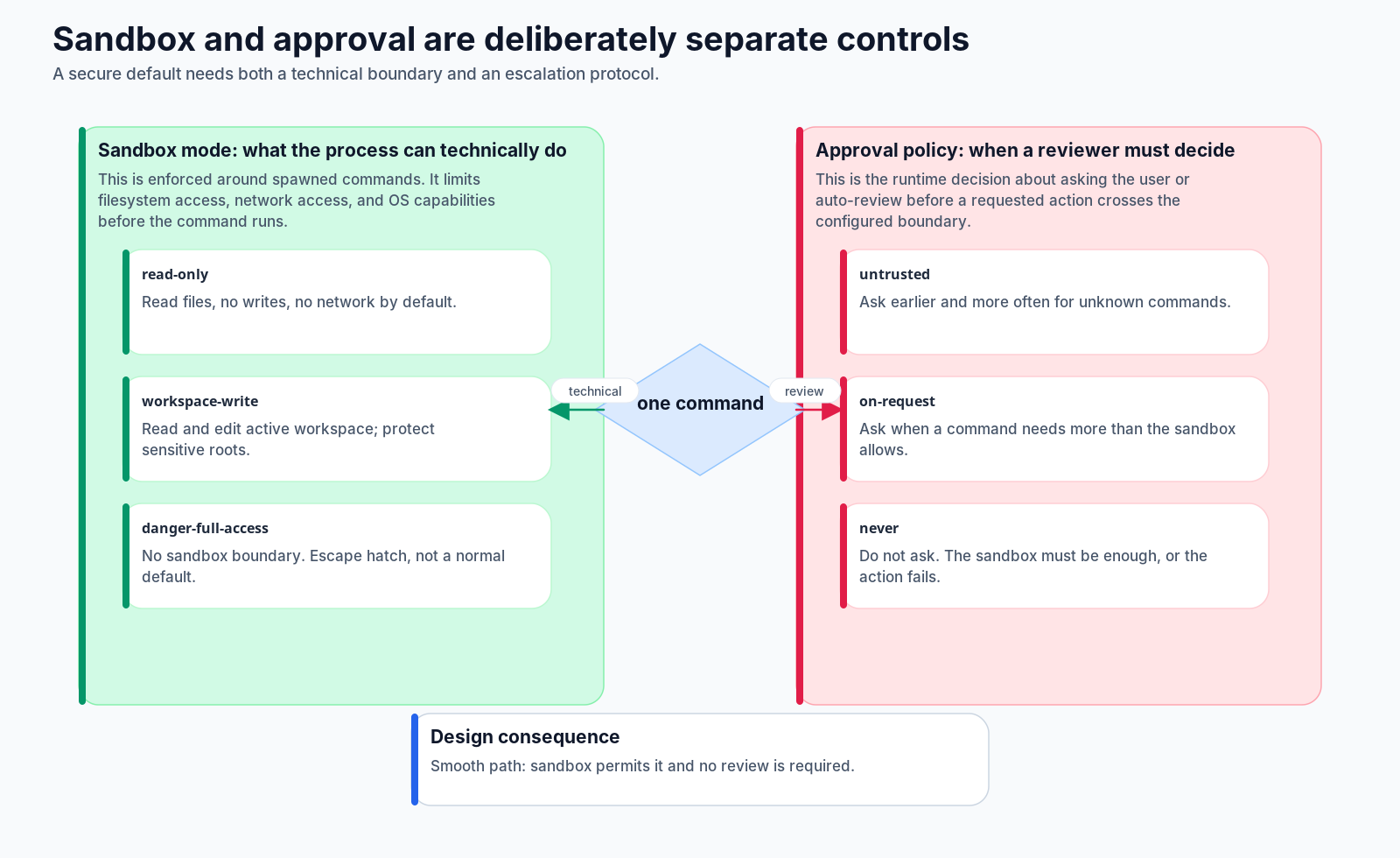
In practical terms, a local test command such as:
cargo test -p checkout checkout_timeout -- --nocapturecan often run inside the workspace sandbox. A command that tries to write outside the workspace, access the internet, or disable sandboxing is a different request. The model may still ask for it, but the runtime treats it as an escalation.
This is the first important design choice: the model does not own the boundary. The host does.
The shell path: one command becomes a structured execution request
In Part IV, we looked at the tool runtime as a model-facing capability layer. In the security model, the shell path is where that abstraction becomes concrete.
The model may emit something that looks like a plain command:
npm install && cargo test -p checkout checkout_timeoutBut Codex does not simply hand that string to the operating system.
The shell handler first resolves the execution environment: current working directory, shell choice, environment variables, network setting, granted permissions for the current turn, explicit escalation flags, and sandbox permissions. It also handles an important special case: patch-shaped shell commands are intercepted and routed into the structured apply_patch path instead of being treated as arbitrary shell text.
After that, the request becomes something closer to an execution record:
ExecParams {
command,
cwd,
env,
timeout,
capture_policy,
network,
sandbox_permissions,
windows_sandbox_settings,
justification
}That record is not yet permission to run. It is the object that the runtime can classify, review, sandbox, and execute.
The source structure is worth paying attention to:
shell.rsis the model-facing shell handler. It resolves the environment, applies permissions, rejects invalid escalation, detects patch-shaped commands, and constructs the shell request.exec_policy.rsclassifies commands intoSkip,NeedsApproval, orForbiddenusing policy rules, command parsing, and approval mode.tools/orchestrator.rscentralizes approval, sandbox selection, execution, denial handling, and retry semantics.exec.rsbuilds the lower-level process execution request and sends it through the sandboxing path.sandboxing/translates the high-level sandbox decision into a platform-specific execution strategy.
That is the difference between “a model ran a command” and “the runtime accepted a structured request under a policy.”
Exec policy: the command gate before the OS sandbox
Sandboxing is not enough by itself, because some decisions are semantic rather than purely filesystem-based.
Consider these commands:
cargo test -p checkout
python scripts/rewrite_imports.py
sudo rm -rf /usr/local/share/cache
bash -lc "curl https://example.com/install.sh | sh"
git clean -fdxA filesystem sandbox can restrict what these commands can mutate, but Codex still needs a command-level view before execution. Some commands are routine. Some are unknown. Some are known to be risky. Some request no sandbox. Some imply network. Some are harmless only under particular approval and sandbox settings.
That is the role of exec policy.
ExecPolicyManager is the command gate. It parses the command, loads rules from configuration layers, applies managed policy overlays, checks sandbox-related requirements, and returns a concrete execution approval requirement:
Skip
NeedsApproval
ForbiddenThe important part is that this is not merely a string allowlist. The policy layer understands categories of commands, nested command shapes, approval modes, and sandbox override requests. It can allow a known-safe command, ask for approval when the action crosses a boundary, or reject a command entirely.
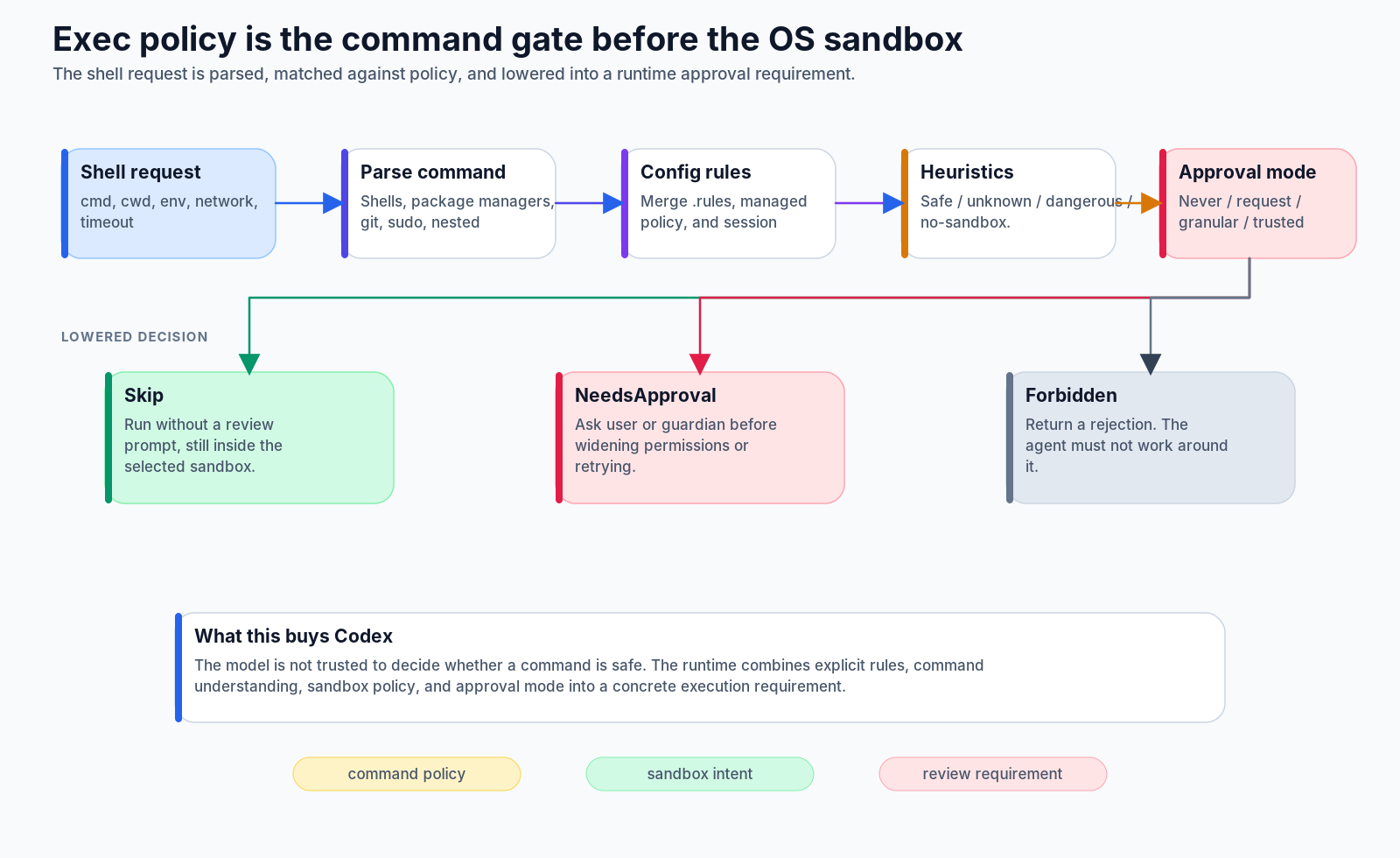
Back to the checkout story.
Running the failing test inside the repo may be classified as safe enough to run under the selected sandbox. Trying to run a networked install step may require approval. Trying to bypass the sandbox or mutate protected metadata should not be silently treated as just another command.
That distinction is what lets Codex be autonomous on the boring path and cautious on the dangerous path.
Workspace-write is not “write anything near the repo”
The next subtle design choice is that workspace-write does not mean every path under the working directory is equally writable.
From a user’s point of view, “the repo” feels like a single object. From the runtime’s point of view, a repo contains very different categories of data:
- source files that the agent is expected to edit;
- tests and fixtures that may be part of the task;
- build artifacts and caches;
- VCS metadata in
.git; - agent state in
.agentsand.codex; - environment files that may contain secrets.
A secure default should not let a model rewrite .git/config, alter hooks, mutate agent state, or read secret files just because those files live under the current directory.
That is why the permission model treats some roots as protected. The docs explicitly call out .git/ and .codex/ safeguards under workspace-style profiles, while permission profiles can also express deny-read globs such as **/*.env and combine filesystem rules with network domain rules. Agent-state directories such as .agents/, when used by a workflow, belong to the same design class: they are control-plane state, not ordinary application code.
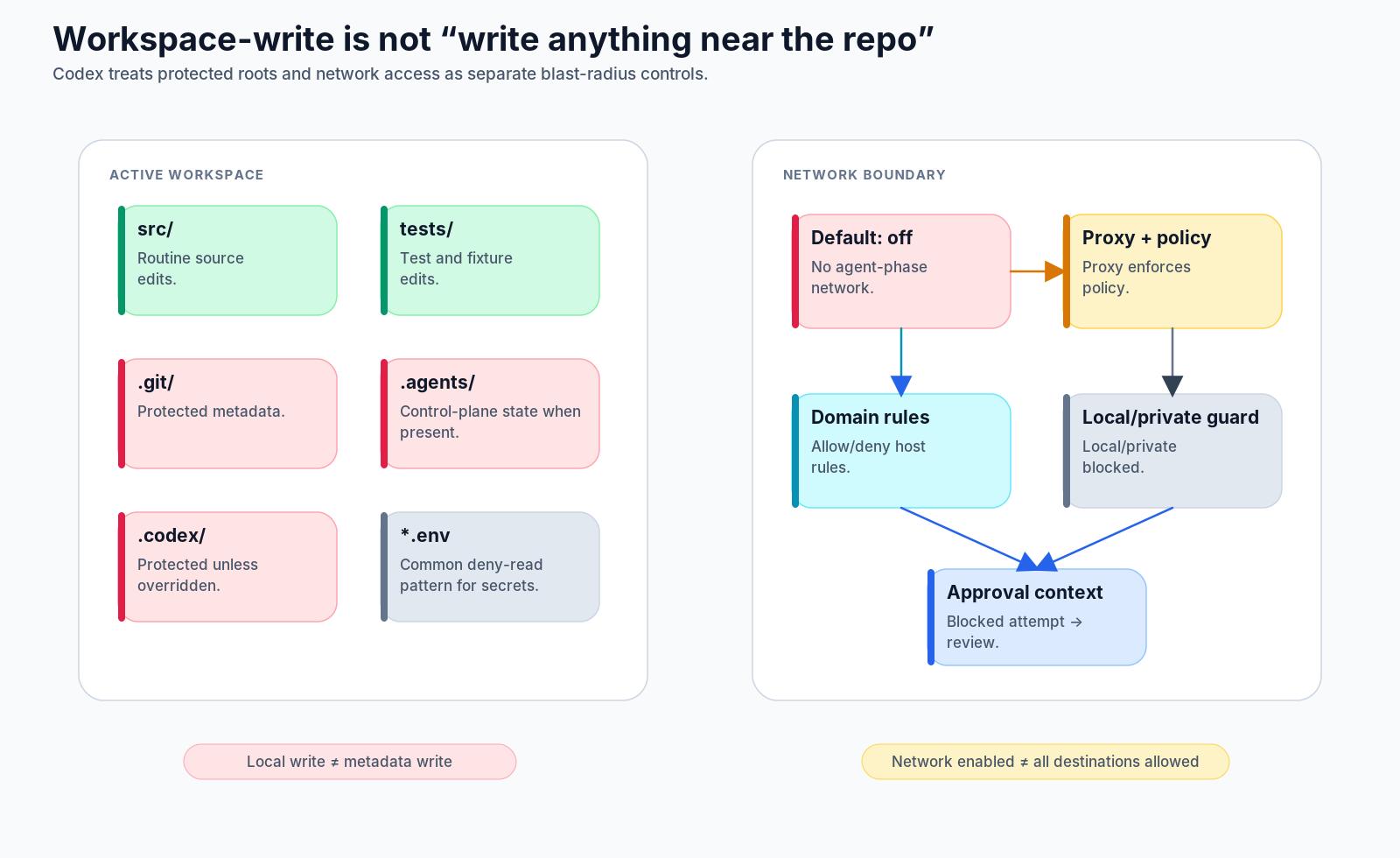
In the checkout task, editing this file is normal:
src/checkout/adapter.rsEditing this file is not the same kind of operation:
.git/hooks/pre-pushReading this file may be worse:
.envThe model might think all three are just paths. The runtime must not.
This is also why danger-full-access should feel like an escape hatch rather than a better productivity setting. Full access removes the membrane. That can be acceptable inside a disposable VM or a purpose-built container, but it is a bad default for a personal machine or a repo with secrets.
Network is a separate blast radius
Network deserves its own category because it changes the threat model.
Without network, a bad command is mostly limited to local filesystem and process effects. With network, a bad command can download unreviewed code, leak secrets, call external services, mutate remote systems, or combine local reads with external writes.
Codex therefore treats network as a separate boundary rather than a side effect of shell execution.
A command like this might be needed for legitimate work:
npm installBut it is not the same as running a local test. It can fetch packages, run install scripts, and talk to external registries. Depending on the configured policy, the runtime may block it, ask the reviewer, or allow it only through a network proxy with domain-level rules.
The network policy layer distinguishes several concepts that are easy to blur together:
- whether network is enabled at all;
- whether a proxy is enforcing decisions;
- which domains are allowed or denied;
- whether local and private destinations are blocked;
- whether a blocked attempt can be converted into an approval request.
The implementation has a dedicated network_policy_decision.rs path that turns blocked network attempts into reviewer context or clear denial messages. That is a sign of the design goal: a network denial should not look like a random process failure. It should become a model-visible safety event that the agent can reason about.
For our checkout task, a good agent should not respond to a denied network request by trying a sneakier command. It should either find a local path—read the lockfile, inspect cached artifacts, run a narrower test—or ask the user for the specific network permission it needs.
ToolOrchestrator: the choreography of approval, sandbox, execution, and retry
Once the shell request is classified, Codex still has to run it correctly.
This is where ToolOrchestrator matters. Its job is to keep the execution choreography in one place:
- compute or receive the approval requirement;
- route the request to user approval or guardian auto-review when needed;
- select the first sandbox attempt;
- run the command under the chosen sandbox;
- interpret sandbox denials or network decisions;
- retry only when policy allows it;
- stream events and record the result.
This centralization is easy to underestimate. Without it, each tool handler would grow its own approval and sandbox logic, and the system would eventually contradict itself. A shell command might retry one way, an MCP tool another way, and a patch path a third way.
The orchestrator gives the runtime a single place to ask:
Did the action require approval?
Was approval granted?
Which sandbox should the first attempt use?
Was the denial caused by sandbox filesystem limits, network policy, or something else?
Is a retry allowed?
What event should the user and model see?That is the kind of “boring infrastructure” that makes agent behavior understandable.
Auto-review: a second reviewer, not a bigger sandbox
Approval does not always have to mean a human click. Codex also has an auto-review path where a separate reviewer agent evaluates boundary-crossing requests.
This is not the same as giving the main agent more power.
The main agent stays inside the configured sandbox and approval policy. When it asks to cross a boundary, the review is routed to the guardian only when the mode supports it. The guardian reconstructs a compact transcript, reviews the proposed action, and returns a structured decision.
The important safety property is fail-closed behavior. If the reviewer times out, fails to execute, returns malformed output, or repeatedly denies requests, the system does not silently approve. It blocks, warns, or trips a circuit breaker.
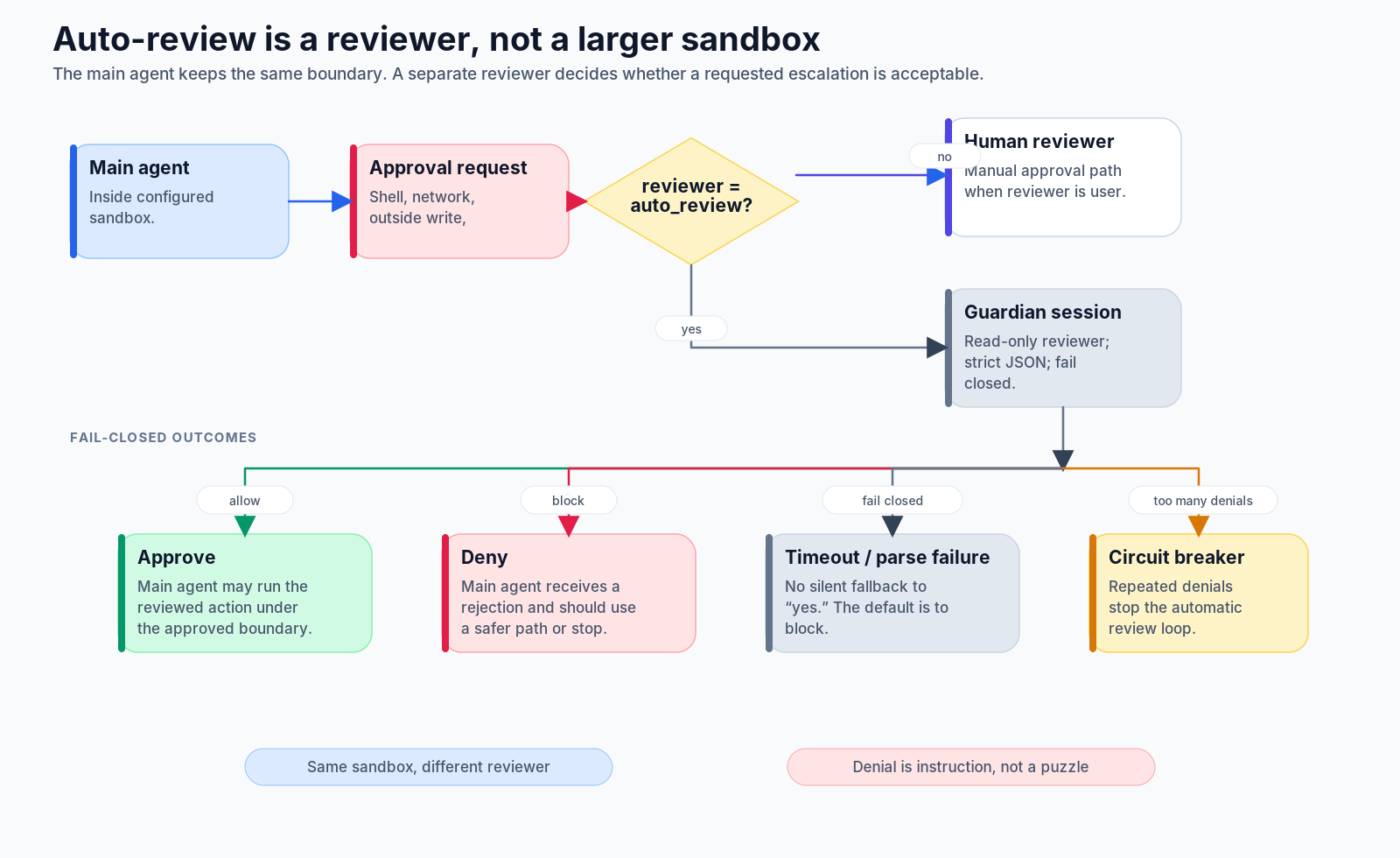
In our story, suppose the model says:
curl https://registry.npmjs.org/some-packageWith auto-review enabled, the question is not “can the main model persuade itself that this is fine?” The question is whether a separate reviewer, looking at the request and context, judges the escalation acceptable.
If the answer is no, the denial is not a puzzle for the model to solve by routing around the policy. It is an instruction: choose a safer path or ask the user.
That is a subtle but crucial agent-design point. Safety boundaries need to be represented as authoritative runtime facts, not merely as suggestions embedded in the prompt.
Platform sandboxing: one contract, different operating systems
The user-facing modes are deliberately simple: read-only, workspace-write, full access, approvals on request, and so on. Underneath that simplicity, the OS implementation differs by platform.
On macOS, Codex can use Seatbelt-style sandboxing. On Linux and WSL2, the sandbox path is based on bubblewrap and seccomp when the required support is available. On Windows, the runtime can use a native Windows sandbox path or WSL2-backed Linux sandbox behavior, depending on the environment. In cloud execution, isolation is provided by OpenAI-managed containers, with setup-phase and agent-phase network behavior separated.
The source layout mirrors this: core code builds high-level execution requests, while the sandboxing layer transforms those requests into backend-specific commands and environment changes. ExecRequest carries the common fields—command, cwd, environment, network setting, sandbox selection, permission profile, filesystem policy, and network policy—so the rest of the turn can handle output and events uniformly.
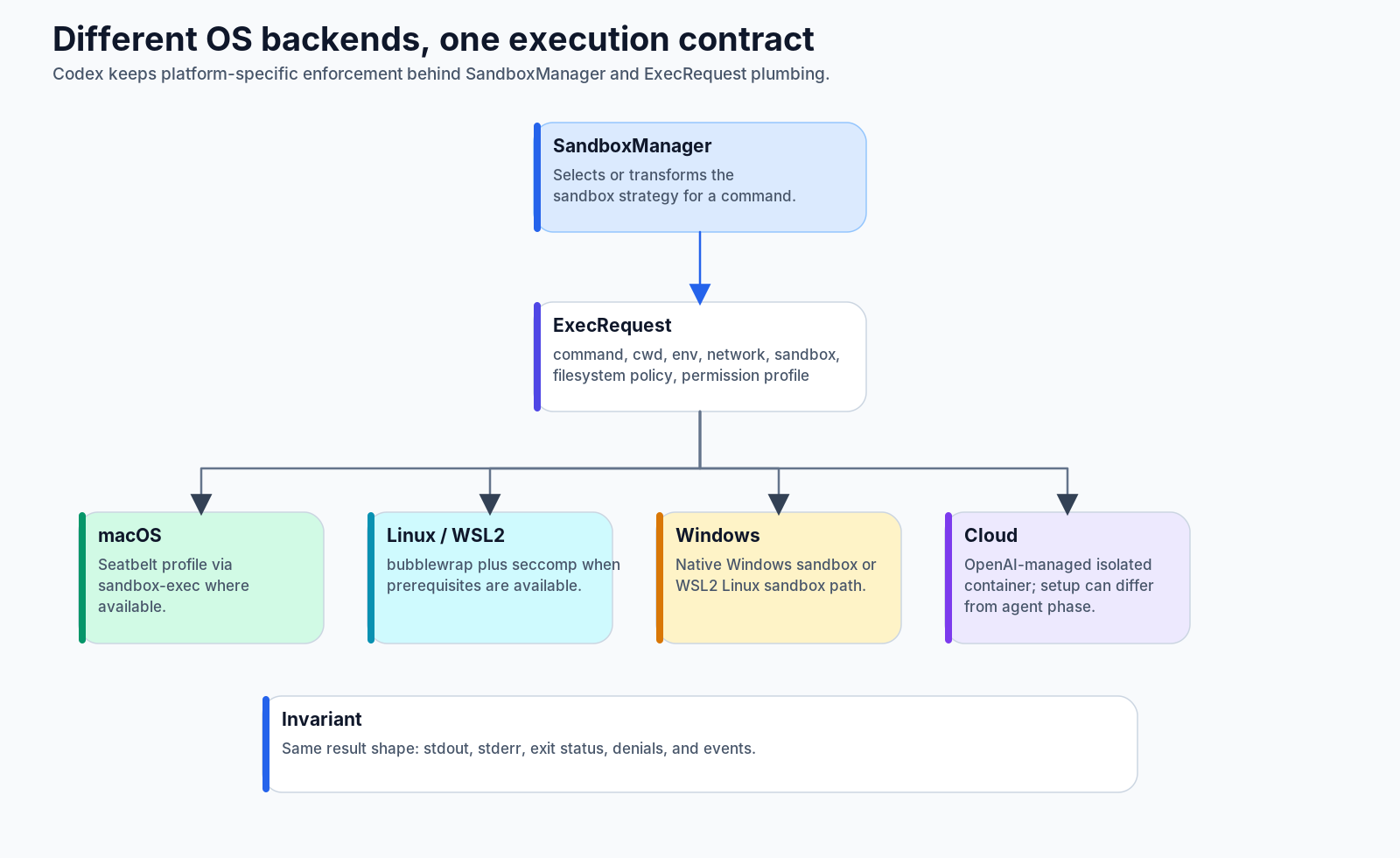
This abstraction is not just code cleanliness. It is what lets a user reason about the same security posture across environments even though the actual enforcement machinery differs.
The invariant should be:
same high-level policy;
platform-specific enforcement;
same model-visible result shape.That invariant is why the agent can receive a coherent denial message instead of “the subprocess failed in a strange way.”
Why danger-full-access exists
There is one setting that intentionally bypasses most of this friction: danger-full-access, often paired with approval_policy = "never" or a CLI shortcut that bypasses approvals and sandboxing.
It exists because there are workflows where the outer environment is already disposable or isolated. For example:
- a throwaway container with no secrets;
- a temporary VM;
- a CI-like environment designed for agent execution;
- a highly trusted local experiment where the user explicitly accepts the risk.
But it should not be treated as “advanced mode.” It is closer to removing the guardrail because another guardrail is supposed to exist outside Codex.
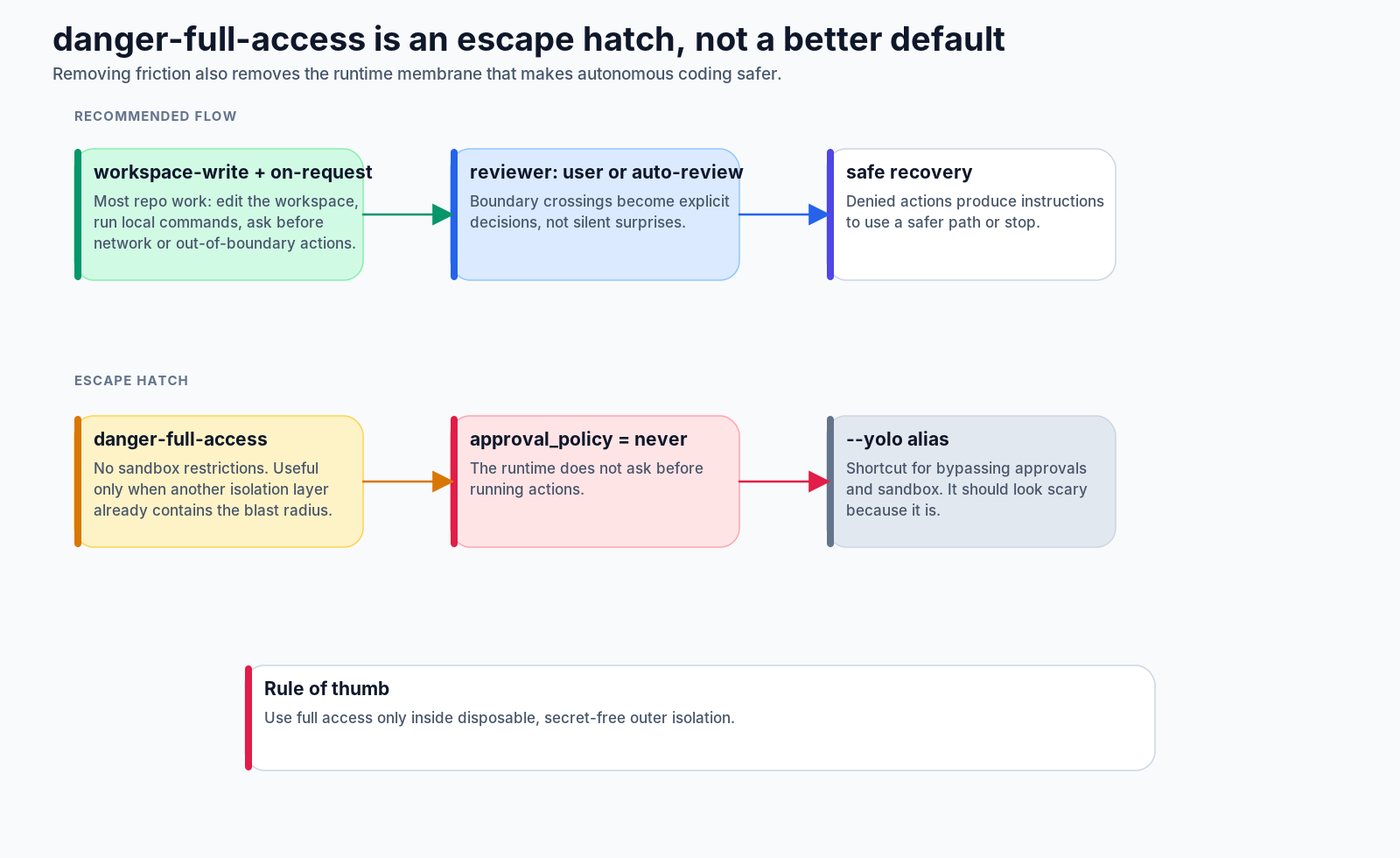
The dangerous part is not that the agent becomes malicious. The dangerous part is that the agent becomes capable of making ordinary model mistakes with real system authority.
A model can misunderstand a path. It can over-broaden a cleanup command. It can follow a malicious instruction in a file. It can run a package script that has unexpected side effects. It can reveal local state through a network request. A sandbox and approval system exists because these are not exotic attacks; they are normal failure modes of autonomous tooling.
So the sharper recommendation is:
Use full access only when the environment is already disposable, secrets are absent, and the blast radius is controlled outside Codex.
For day-to-day source work, workspace-write plus on-request approval is the more coherent default.
The hidden quality bar: denial must be useful
A security boundary that only says “no” is hard for an agent to use. Codex needs denials to be part of the agent loop.
When a command is blocked, the model should learn something actionable:
- the command needed network;
- the destination was not on the allowlist;
- the command tried to write outside the workspace;
- the path is protected;
- the reviewer denied the escalation;
- the sandbox backend refused to run unsandboxed because deny-read rules must be preserved.
That is why the runtime streams events and structured results rather than only returning an exit code. A denied network attempt is not the same as a failing test. A forbidden command is not the same as a shell syntax error. A reviewer denial is not something to retry with different spelling.
For our checkout task, this determines whether the agent stays useful after a block.
A bad agent behavior would be:
Network blocked. Try curl through a different shell wrapper.A good agent behavior is:
Network is blocked. I can continue by inspecting the lockfile and running the local test. If the missing dependency is required, I will ask for access to the package registry explicitly.This is where runtime safety and agent quality meet. The runtime must produce clear boundaries; the model must incorporate those boundaries into its plan.
The source map
Here is the map I use when reading this part of Codex:
| Area | Why it matters |
|---|---|
codex-rs/core/src/tools/handlers/shell.rs | Model-facing shell handler: environment resolution, permission checks, patch interception, shell request construction. |
codex-rs/core/src/exec_policy.rs | Command policy manager: parses command intent and lowers policy into Skip, NeedsApproval, or Forbidden. |
codex-rs/core/src/tools/orchestrator.rs | Central approval/sandbox/execution/retry choreography for tool calls. |
codex-rs/core/src/tools/sandboxing.rs | Shared approval primitives and sandbox attempt abstractions used by tools. |
codex-rs/core/src/exec.rs | Lower-level process execution path and sandbox-aware request construction. |
codex-rs/core/src/sandboxing/ | Core-owned sandboxing adapters and execution plumbing. |
codex-rs/core/src/network_policy_decision.rs | Turns network policy blocks into approval context or model-visible denial messages. |
codex-rs/core/src/guardian/ | Auto-review / guardian path for reviewer-agent approval decisions. |
The official docs are also important because this is not only an implementation detail. It is a user-facing contract:
And the relevant source entry points are:
- shell.rs
- exec_policy.rs
- orchestrator.rs
- tools/sandboxing.rs
- exec.rs
- sandboxing/mod.rs
- network_policy_decision.rs
- guardian/
Takeaway
The most tempting but wrong description is:
Codex asks before running dangerous commands.
That is too small.
A better description is:
Codex turns model actions into structured runtime requests, classifies them with exec policy, constrains them with sandbox and permission profiles, routes risky boundary crossings through approval or auto-review, and reports denials back into the agent loop as facts.
That is why this part belongs after Tool Runtime. Tools are how the model acts; the security model is how the host decides which actions are allowed to become real.
The deeper design lesson is not specific to Codex. Any serious coding agent eventually needs this separation:
model intent
!= command authority
!= filesystem authority
!= network authority
!= approval authorityWhen those collapse into one concept, the agent may feel simpler for a demo, but it becomes harder to trust. Codex’s design is more complicated because the problem is more complicated: autonomous coding needs a runtime membrane, not just a polite model.